Clear Sky Science · nl
Een resource-toewijzingsmethode voor een cognitief internet der dingen gebaseerd op een multi-agent reinforcement learning-algoritme
Waarom de data van uw auto “vers” moet blijven
Moderne auto’s delen continu informatie over hun positie, snelheid en omgeving met andere voertuigen en wegkantapparatuur. Voor veiligheidsfuncties en toekomstige zelfrijdende toepassingen moet deze informatie niet alleen nauwkeurig maar ook actueel zijn: een remwaarschuwing die een seconde te laat komt, kan nutteloos zijn. Dit artikel onderzoekt hoe zulke gegevens zo up-to-date mogelijk gehouden kunnen worden op drukke draadloze netwerken, met behulp van een nieuw soort op leren gebaseerde regelmethode die auto’s in staat stelt zelf te beslissen hoe en wanneer ze verzenden.
Slimme wegen die de ether delen
De studie beschouwt een toekomstig wegennetwerk waarin duizenden verbonden auto’s het beperkte radiospectrum delen met bestaande gebruikers zoals mobiele telefoongebruikers. Deze omgeving, genoemd een cognitief Internet of Things, neemt aan dat de auto’s “beleefde gasten” zijn: ze mogen frequenties alleen gebruiken wanneer dat geen primaire gebruikers stoort. Tegelijk moeten voertuigen snel met elkaar en met basisstations communiceren om aanrijdingswaarschuwingen, verkeerscoördinatie en entertainmentdiensten te ondersteunen. Het in balans brengen van deze eisen is lastig omdat auto’s snel bewegen, signalen vervagen terwijl ze door stadsblokken rijden en de beschikbare kanalen van het ene op het andere moment veranderen.
Versheid meten, niet alleen snelheid
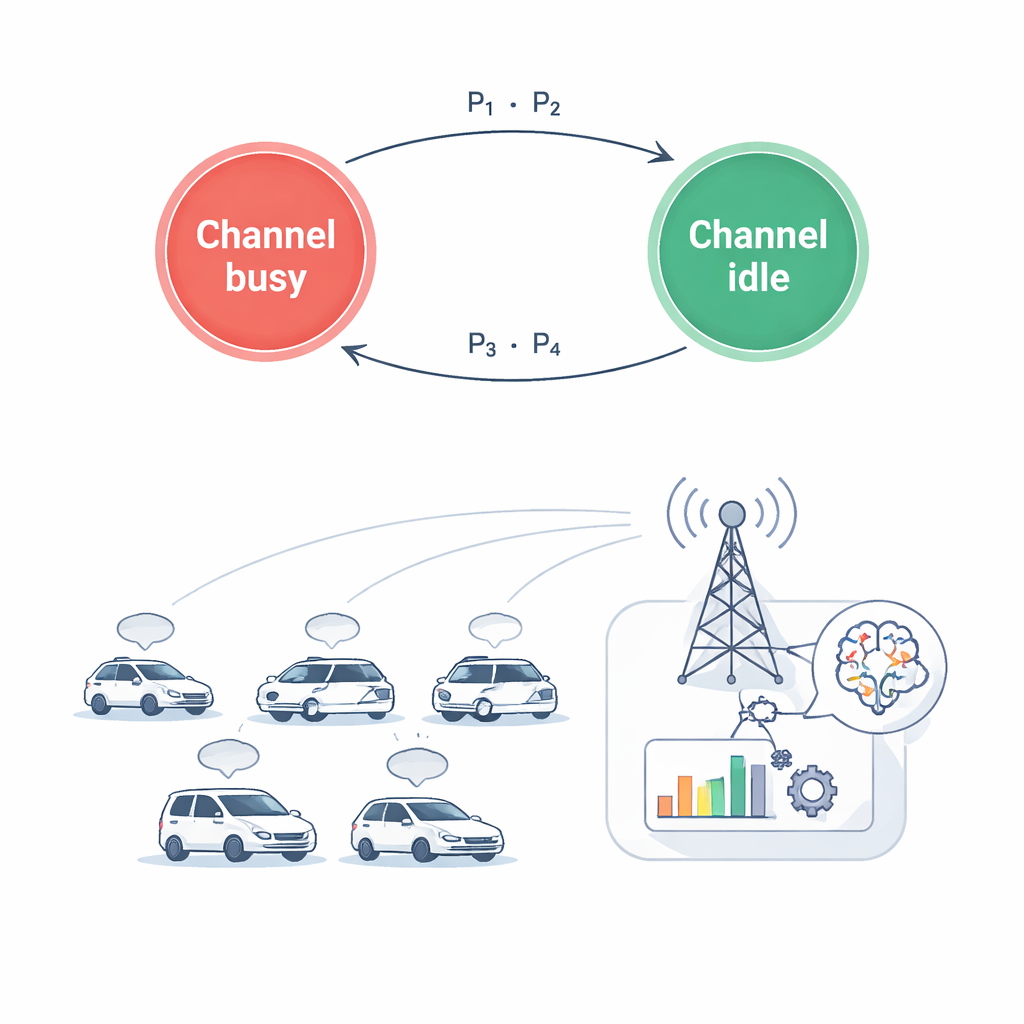
Traditioneel netwerkontwerp richt zich vaak op het verhogen van de datarate of het verlagen van de gemiddelde vertraging. Voor veiligheidskritische voertuigmessingen is echter echt van belang hoe oud de meest recente statusupdate is wanneer deze een ontvanger bereikt. De auteurs gebruiken een maatstaf genaamd Age of Information, die groeit naarmate de tijd verstrijkt sinds de laatste succesvolle update en wordt gereset wanneer een nieuw bericht arriveert. In hun model stuurt elk voertuigpaar herhaaldelijk datablokken. Als de draadloze link sterk is en het gekozen vermogen hoog genoeg, wordt het huidige blok snel afgehandeld en daalt de age; als de verbinding slecht is of het vermogen beperkt, blijft data achter en blijft de age stijgen. Het doel is radiofrequenties en vermogensniveaus te kiezen zodat deze age zo laag mogelijk blijft, terwijl tegelijk energie bespaard wordt en primaire gebruikers beschermd worden tegen interferentie.
Auto’s leren samenwerken door trial-and-error
Omdat de draadloze omgeving snel verandert en elke auto slechts lokale informatie ziet, formuleren de auteurs het probleem als een leertaak in plaats van een vaste formule. Elke auto fungeert als een intelligent agent die herhaaldelijk zijn situatie observeert: welke kanalen druk lijken, hoe sterk zijn radiolinks zijn, hoeveel data nog verzonden moet worden en hoe oud zijn laatste update is. Op basis van dit gedeeltelijke beeld kiest de agent een actie die een discrete keuze combineert (welk kanaal te gebruiken of stil te blijven) met een continue keuze (hoeveel vermogen te sturen). Na het handelen meet het systeem hoe actueel de informatie is, hoeveel vermogen is gebruikt en of primaire gebruikers gestoord zijn. Deze terugkoppeling wordt omgezet in een beloningssignaal dat de agenten, over veel gesimuleerde episodes, stuurt naar betere gezamenlijke beslissingen.
Een op maat gemaakt leeralgoritme voor gemengde beslissingen
Om deze agenten te trainen ontwikkelen de auteurs een verbeterde multi-agent versie van een populaire methode genaamd Proximal Policy Optimization. Hun variant, IMAPPO, gebruikt een centraal trainingsmodule die de globale toestand ziet en evalueert hoe goed de gecombineerde acties van alle auto’s zijn, terwijl elke individuele auto een privé beslisregel leert die hij zelf in real time kan toepassen. Een belangrijke innovatie is een verbeterd beslisnetwerk dat op natuurlijke wijze zowel de aan/uit-keuze van kanalen als het vloeiende bereik van mogelijke vermogensniveaus kan afhandelen. In simulaties van rasterachtige stadswegen, met auto’s en basisstations op realistische posities en radio-effecten zoals fading en interferentie meegenomen, wordt de voorgestelde methode vergeleken met verschillende moderne leeralgoritmen en een willekeurige baseline.
Versere data met minder energie
De resultaten tonen aan dat de nieuwe methode informatie merkbaar verser kan houden terwijl tegelijkertijd minder vermogen wordt verbruikt. Over verschillende aantallen voertuigen en verschillende hoeveelheden data om te verzenden verlaagt IMAPPO de gemiddelde Age of Information tot ongeveer de helft vergeleken met eenvoudige willekeurige toegang, en presteert het beter dan andere geavanceerde leermethoden met betekenisvolle marges. Tegelijk verlaagt het het totale vermogen dat door de auto’s gebruikt wordt, wat helpt batterijleven te sparen en interferentie met andere spectrumsumgebruikers te beperken. Voor een lezer zonder technische achtergrond betekent dit dat slimmer, leergebaseerd beheer van wie wanneer en hoe luidruchtig op de draadloze “rijbaan” praat, verbonden en autonome voertuigen veiliger, efficiënter en respectvoller naar de druk gedeelde ether kan maken.
Bronvermelding: Wang, R., Shen, Y., Wang, D. et al. A cognitive internet of things resource allocation method based on multi-agent reinforcement learning algorithm. Sci Rep 16, 7756 (2026). https://doi.org/10.1038/s41598-026-36380-x
Trefwoorden: verbonden voertuigen, draadloze spectrumsdeling, age of information, reinforcement learning, internet der dingen