Clear Sky Science · nl
Identificatie van risicofactoren voor grootschalige attracties met een mixture of experts en fusie van meerdere modellen
Waarom veiligheid in pretparken slimmer lezen nodig heeft
Jaarlijks stappen honderden miljoenen mensen in achtbanen, valtorens en draaiende attracties, in de veronderstelling dat complexe machines en drukke bedieners hen veilig houden. Achter de schermen produceren toezichthouders en ingenieurs enorme hoeveelheden rapporten, ongevalsregistraties en klachten van het publiek — maar het merendeel van deze informatie staat in tekstvorm en is moeilijk snel doorzoekbaar. Deze studie onderzoekt hoe geavanceerde kunstmatige intelligentie deze documenten op schaal kan "lezen", patronen van gevaar eerder kan signaleren en autoriteiten een helderder beeld kan geven van waar attracties het meest waarschijnlijk falen.
Van verspreide rapporten naar een eenduidig risicobeeld
China telt nu meer dan 25.000 grote attracties en meer dan 700 miljoen bezoekers per jaar. Ondanks algemene verbeteringen in de veiligheid doen zeldzame maar ernstige ongevallen zich nog steeds voor, vaak nadat inspecties vroegen waarschuwingssignalen in technische beschrijvingen of gebruikersklachten hebben gemist. De auteurs betogen dat traditioneel toezicht — gebaseerd op periodieke handmatige controles, deskundig oordeel en onderhoudslogs — te traag en subjectief is voor zo’n snel veranderende omgeving. Zij brengen een grote, realistische tekstverzameling samen die ongevalsrapporten, wetten en normen, inspectie- en onderhoudsrecords en online klachten over attracties omvat. Na zorgvuldige schoonmaak en filtering vormt dit multisource corpus het ruwe materiaal voor een geautomatiseerd, datagedreven risicobewakingssysteem. 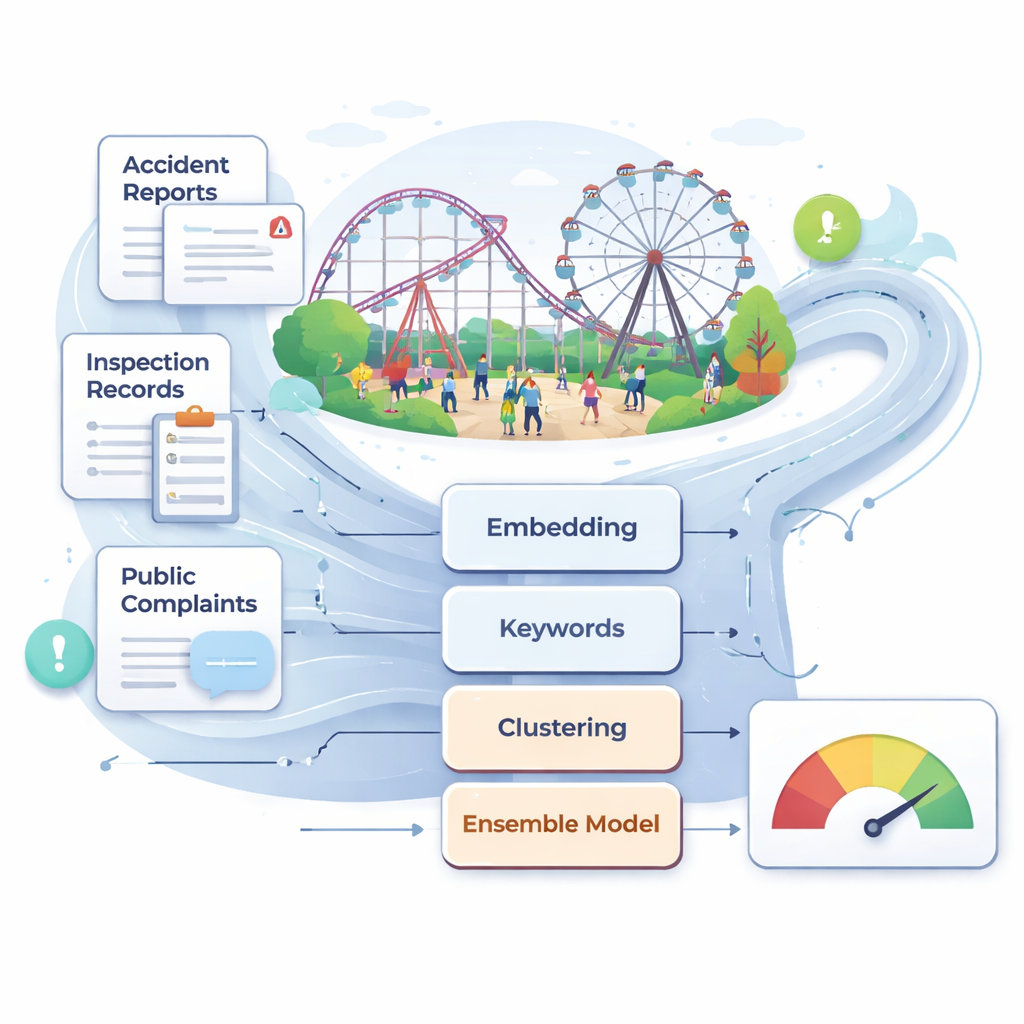
Computers leren de taal van risico te begrijpen
Om deze rommelige tekst te doorgronden, vertrouwen de onderzoekers op moderne taalmodellen die zinnen omzetten in numerieke vectoren die hun betekenis vastleggen. Ze gebruiken voornamelijk een Chinees model genaamd BGE, dat elk tekstfragment voorstelt als een 1.024-dimensionaal punt in de ruimte, plus een compacte set van 30 sleutelwoordgebaseerde kenmerken gericht op termen als “onderhoud,” “inspectie,” en “rectificatie.” Deze dubbele benadering — diepe semantische context plus handgecurateerde risicotermen — helpt het systeem subtiele verschillen te onderscheiden tussen bijvoorbeeld routinecontroles en ernstige gebreken. Het team experimenteert ook met een ander state-of-the-art embeddingmodel, Qwen3, om te testen of een andere taalkern de prestaties verbetert; in de praktijk blijkt BGE iets beter voor deze veiligheidstaak.
Verborgen patronen en belangrijke zwakke plekken ontdekken
Voordat teksten in concrete risicocategorieën worden ingedeeld, gebruiken de auteurs onbewaakte methoden om natuurlijke groeperingen te ontdekken. Ze passen k-means clustering toe op de embeddings en gebruiken een visualisatiemethode genaamd UMAP om te laten zien dat rapporten in meerdere duidelijke topicclusters vallen. Vervolgens bouwen ze een semantische graaf waarin elke knoop een veiligheid-gerelateerd sleutelwoord is en verbindingen sterke co-occurrence en semantische gelijkenis aangeven. Een community-detectie-algoritme groepeert deze knopen in clusters die overeenkomen met brede thema’s zoals apparatuur- en constructieveiligheid, dagelijkse operatie en onderhoud, noodrespons en beheer en toezicht. Binnen dit netwerk fungeren bepaalde woorden — zoals “onderhoud,” “inspectie,” en “verantwoordelijkheid” — als bruggen tussen clusters, waarmee dwarsliggende zwaktes worden benadrukt die op meerdere manieren ongelukken kunnen veroorzaken. Uit deze structuur extraheren zij 31 kernrisicofactoren die vier hoofd dimensies beslaan, van realtime monitoring van apparatuur tot duidelijkheid over functieverantwoordelijkheden. 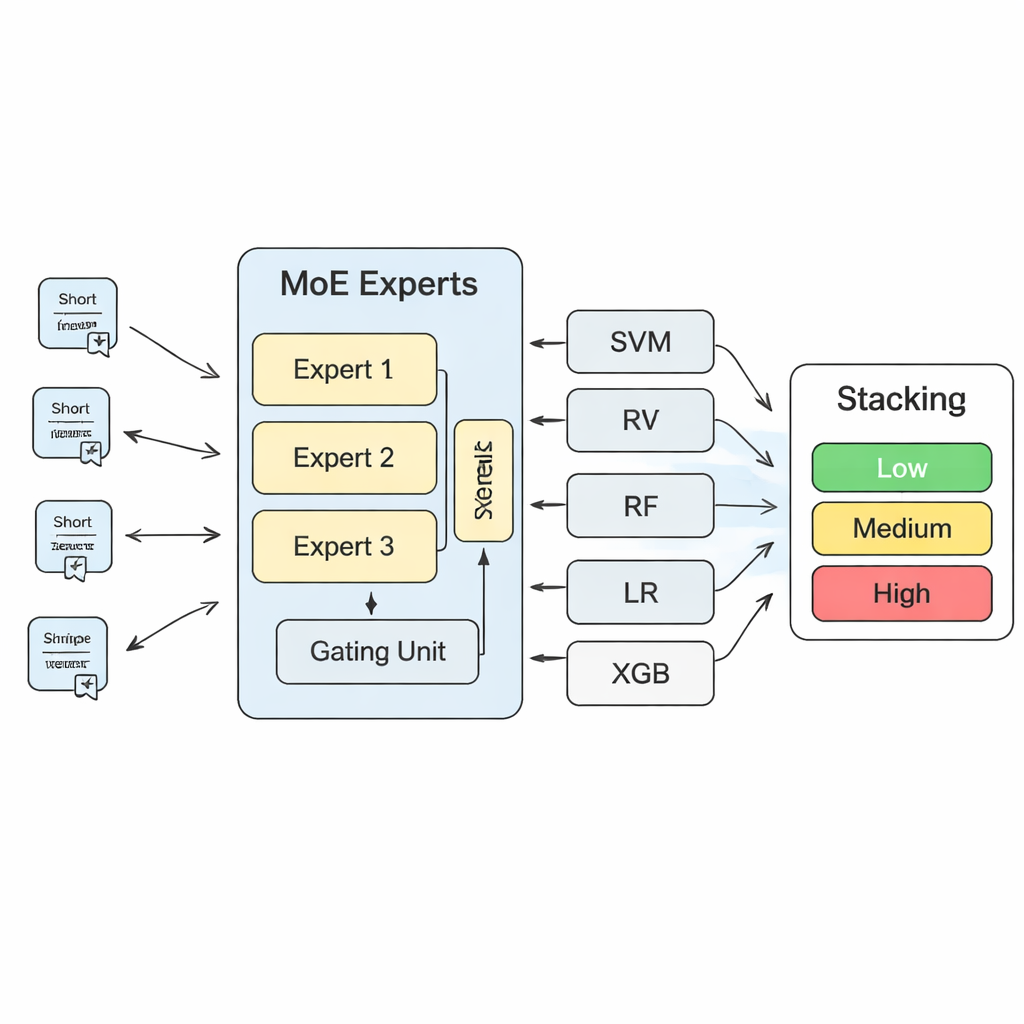
Verschillende modellen mengen tot één sterker veiligheidsvonnis
Om deze inzichten om te zetten in concrete risicovoorspellingen bouwt de studie een gelaagd machine-learningsysteem. In de kern staat een "mixture of experts" (MoE)-model: meerdere neurale netwerken, of experts, leren elk te specialiseren in verschillende soorten risicopatronen, terwijl een gatingcomponent bepaalt welke experts voor een nieuwe tekst het meest betrouwbaar zijn. De uitkomsten van dit MoE-model worden vervolgens gecombineerd met de voorspellingen van meer traditionele algoritmen, zoals support vector machines, random forests, logistieke regressie en gradient-boosted trees. Een uiteindelijke "Stacking"-laag — een ander machine-learningmodel — leert hoe al deze meningen te wegen om tot een eindbeslissing te komen. Door uitgebreide cross-validatie vinden de auteurs dat het gebruik van drie experts in de MoE-laag de beste balans biedt tussen modelcapaciteit en stabiliteit.
Wat de winst betekent voor toezicht in de praktijk
Vergeleken met elk enkel model verbetert het MoE-plus-Stacking-systeem aanzienlijk op nauwkeurigheid, precisie, recall en een betrouwbaarheidsmaat genaamd LogLoss. In praktische termen betekent dit minder gemiste waarschuwingen en minder valse alarmen bij het screenen van grote volumes veiligheidstekst. Het model kan op een gewone werkstation draaien en snelle risico-evaluaties leveren voor nieuwe inspectierapporten of klachten, waardoor het geschikt is als besluitvormingsondersteuning in plaats van vervanging van menselijk oordeel. De auteurs benadrukken dat hun aanpak verder aangepast kan worden aan andere bijzondere apparatuur zoals liften of kabelbanen. Voor niet-specialistische lezers is de kernboodschap dat door computers de taal van veiligheid te leren — over technische documenten, regelgeving en alledaagse klachten heen — toezichthouders gevarenzones eerder kunnen detecteren, inspecties slimmer kunnen richten en een dag in het park iets veiliger kunnen maken voor iedereen.
Bronvermelding: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Trefwoorden: veiligheid van attracties, risicotekstanalyse, machine learning, mixture of experts, toezicht op openbare veiligheid