Clear Sky Science · nl
Meervoudige screeningsmethode voor netwerkbeveiligingswaarschuwingen gebaseerd op DBSCAN-algoritme en Rete-regelinferentie
Waarom slimmere waarschuwingen ertoe doen
Elke moderne organisatie is nu afhankelijk van netwerken die nooit slapen, van ziekenhuizen en banken tot cloudproviders en stedelijke infrastructuur. Deze netwerken worden bewaakt door beveiligingstools die dagelijks duizenden waarschuwingen genereren—veel meer dan menselijke analisten realistisch kunnen onderzoeken. In die stroom zitten enkele waarschuwingen die echte inbraken of ernstige zwakheden signaleren. Dit artikel presenteert een nieuwe manier om die cruciale signalen van de ruis te scheiden, waardoor valse alarmen verminderen terwijl meer echte aanvallen worden gedetecteerd, en dat alles met zeer weinig rekenkracht.
Van rommelige logs naar schone, bruikbare gegevens
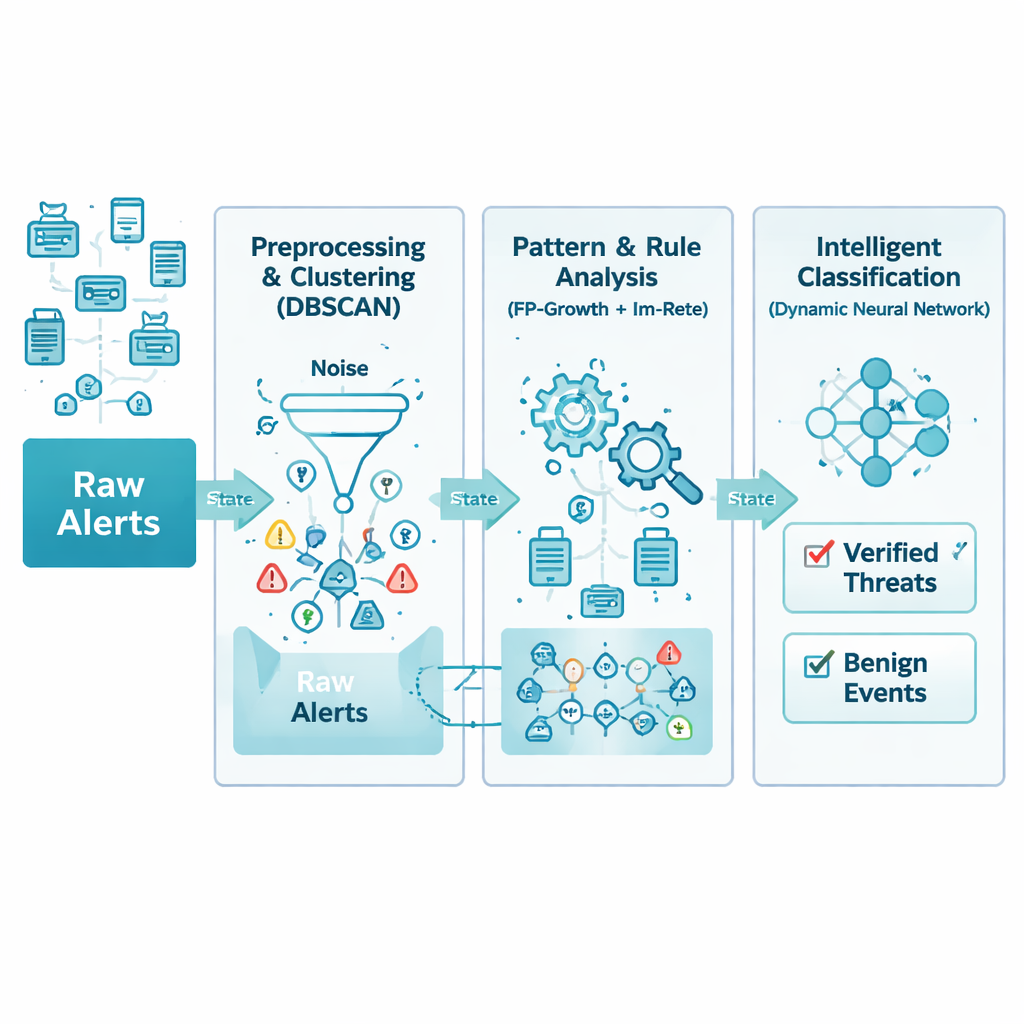
Netwerkwaarschuwingen komen van veel verschillende apparaten en leveranciers, elk met hun eigen formaat en detailniveau. De auteurs pakken deze chaos eerst aan met een zorgvuldige schoonmaak- en standaardisatiestap. Alle binnenkomende waarschuwingen worden naar een gemeenschappelijke structuur vertaald en ontdaan van duplicaten, ontbrekende velden en duidelijke fouten. Bijvoorbeeld: herhaalde waarschuwingen van meerdere apparaten over dezelfde aanval binnen enkele seconden worden samengevoegd tot één, rijker record. Het resultaat is een gestroomlijnde database van waarschuwingen die bewaart wat het belangrijkst is—wat er gebeurde, wanneer het gebeurde en welke systemen erbij betrokken waren—terwijl rommel wordt verwijderd die later analyse alleen zou vertragen.
Patronen in de tijd laten echt gevaar zien
Zelfs schoongemaakte gegevens kunnen overweldigend zijn, dus de volgende laag zoekt naar natuurlijke groeperingen in de tijd. De methode maakt gebruik van een techniek die dichtheidsgebaseerde clustering wordt genoemd, die in essentie zoekt naar perioden waarin gerelateerde waarschuwingen dicht bij elkaar optreden, terwijl geïsoleerde of willekeurige waarschuwingen als ruis worden behandeld. Dit voorkomt dat van tevoren moet worden geraden hoeveel typen incidenten er bestaan. Het systeem gebruikt ook overlappende schuivende tijdvensters, zodat snel bewegende aanvallen niet per ongeluk over verschillende batches worden verdeeld. Zorgvuldig afgestemd houdt deze stap de meest informatieve activiteitspieken vast en wordt tot een derde van misleidende achtergrondruis in de ruwe stromen verwijderd.
Regels leren omgaan met ontbrekende stukken
Netwerken in de echte wereld zijn onvolmaakt: pakketten raken zoek, apparaten gedragen zich vreemd en sommige waarschuwingen komen nooit aan. Traditionele regelengines verwachten volledige informatie en falen eenvoudigweg als een onderdeel ontbreekt. Hier herontwerpen de auteurs het klassieke Rete-regelsysteem zodat elke voorwaarde in een regel een gewicht heeft, wat weerspiegelt hoe belangrijk het is. In plaats van te eisen dat elk detail perfect overeenkomt, controleert de engine of genoeg van de belangrijke onderdelen na verloop van tijd samenvallen. Deze "vage" benadering laat het systeem een aanvalspatroon herkennen, zelfs als bijvoorbeeld een vroege verkenning of een kleine sensorwaarschuwing niet werd geregistreerd. Tegelijkertijd worden zelden gebruikte of lang inactieve regelvertakkingen weggeknipt om het geheugengebruik laag te houden.
Neuraal netwerk dat zichzelf hervormt
Nadat patronen en regels de waarschuwingen in betekenisvollere kenmerken hebben omgezet, gebruikt een laatste fase een neuraal netwerk om te beslissen welke gebeurtenissen echte dreigingen zijn en welke onschuldig zijn. In tegenstelling tot veel machine-learningmodellen die vastliggen zodra ze zijn ontworpen, kan dit netwerk zijn verborgen lagen vergroten of verkleinen tijdens training. Het begint klein, voegt eenheden toe wanneer dat duidelijk de prestaties verbetert, en snoeit delen weg die hun waarde niet bewijzen. Dit adaptieve ontwerp helpt het model zich aan te passen aan zowel eenvoudige als complexe datasets zonder giswerk, vermindert het risico op overfitting en verkort de trainingstijd terwijl de nauwkeurigheid hoog blijft.
Wat de tests in de praktijk aantonen
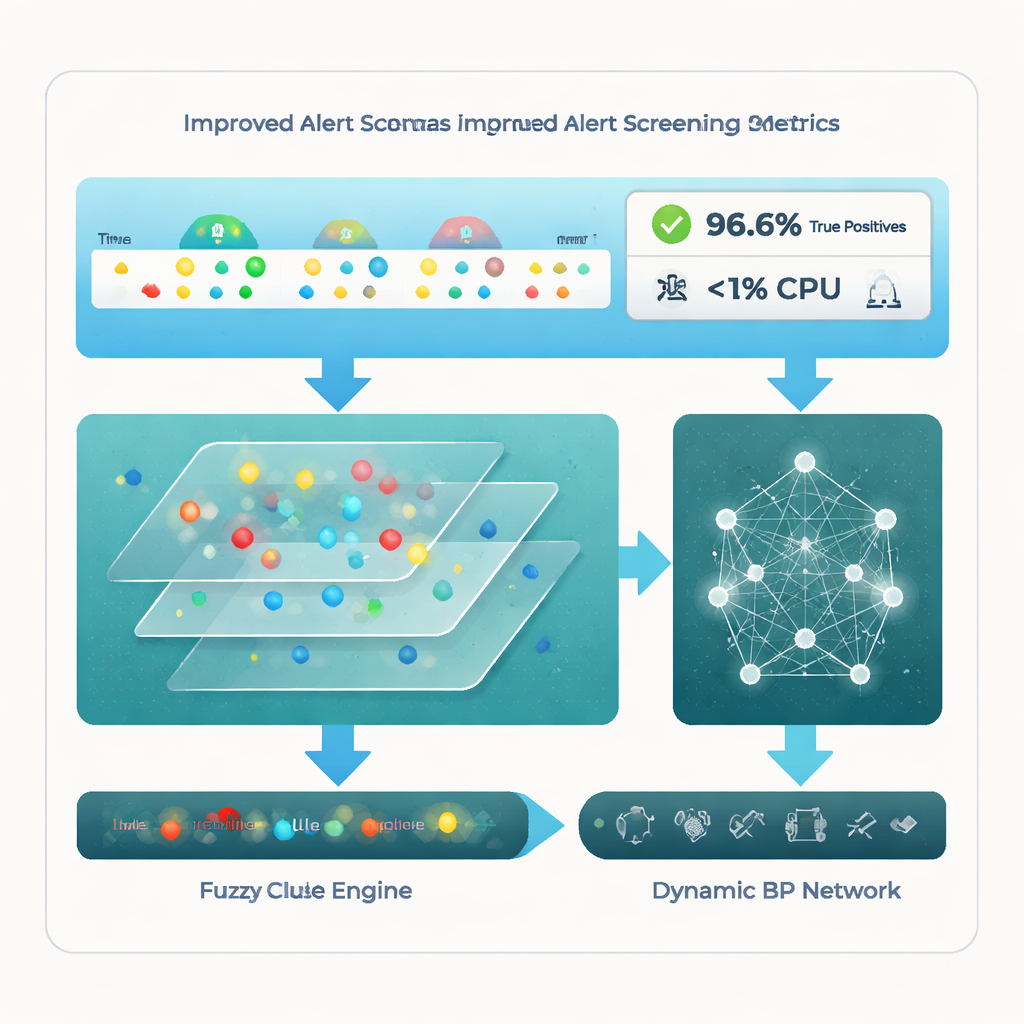
Het team evalueert hun raamwerk op bekende openbare inbraakdatasets en op een grote verzameling bedrijfswaarschuwingen uit de echte wereld. Vergeleken met vier recente geavanceerde methoden—waaronder pure clustering, gespecialiseerde IoT-waarschuwingssystemen en getunede neurale netwerken—valt de nieuwe meervoudige pijplijn op. Het bereikt een true positive rate van ongeveer 96,6%, wat betekent dat het bijna alle echte aanvalspatronen correct markeert, terwijl het lawaaierige of irrelevante waarschuwingen terugbrengt tot ongeveer 18,7%. Net zo opvallend is dat dit met minder dan 1% CPU-gebruik gebeurt, ver onder concurrerende benaderingen. Statistische tests bevestigen dat deze verbeteringen niet aan toeval te wijten zijn, maar aan de manier waarop de methode clustering, regelredenering en adaptief leren combineert.
Wat dit betekent voor alledaagse beveiligingsteams
Voor beveiligingsanalisten die dagelijks verdrinken in waarschuwingen, wijst dit werk op tools die zowel nauwkeuriger als zuiniger met beperkte hardware zijn. Door data te reinigen, het intelligent in de tijd te groeperen, ontbrekende stukken te tolereren en een zelfaanpassend neuraal netwerk te gebruiken, helpt het raamwerk de relatief kleine set waarschuwingen te benadrukken die werkelijk aandacht verdienen. Dat betekent snellere reactie op echte aanvallen, minder verspilde uren aan valse sporen en beter gebruik van bestaande apparatuur. Naarmate netwerken in omvang en complexiteit groeien, kan dergelijke meervoudige screening een belangrijke schakel zijn om digitale infrastructuur veilig te houden zonder de mensen die deze verdedigen te overweldigen.
Bronvermelding: Ni, L., Zhang, S., Huang, K. et al. Multi-level screening method for network security alarms based on DBSCAN algorithm and rete rule inference. Sci Rep 16, 5632 (2026). https://doi.org/10.1038/s41598-026-36369-6
Trefwoorden: netwerkbeveiliging, inbraakdetectie, alarmfiltering, machine learning, cyberaanvaldetectie