Clear Sky Science · nl
Groepsleren in recommender-systemen: op weg naar adaptieve en impliciete groepsmodellering
Waarom slimere groepen online ertoe doen
Van filmavonden met vrienden tot familievakanties: veel van onze keuzes worden in groepen gemaakt. Toch denken de meeste online platforms nog steeds in termen van individuen. Dit artikel stelt een simpele maar ingrijpende vraag: wat als onze streamingdiensten, winkelapps en reisportalen in staat zouden zijn om op de achtergrond zelf natuurlijke groepen van mensen en items te ontdekken en zich daaraan aan te passen, in plaats van te vertrouwen op vaste, handgemaakte groeperingen? De auteurs presenteren een nieuwe manier waarop recommendersystemen zulke groepen automatisch kunnen leren, om aanbevelingen te doen die eerlijk en bevredigend aanvoelen voor alle betrokkenen.
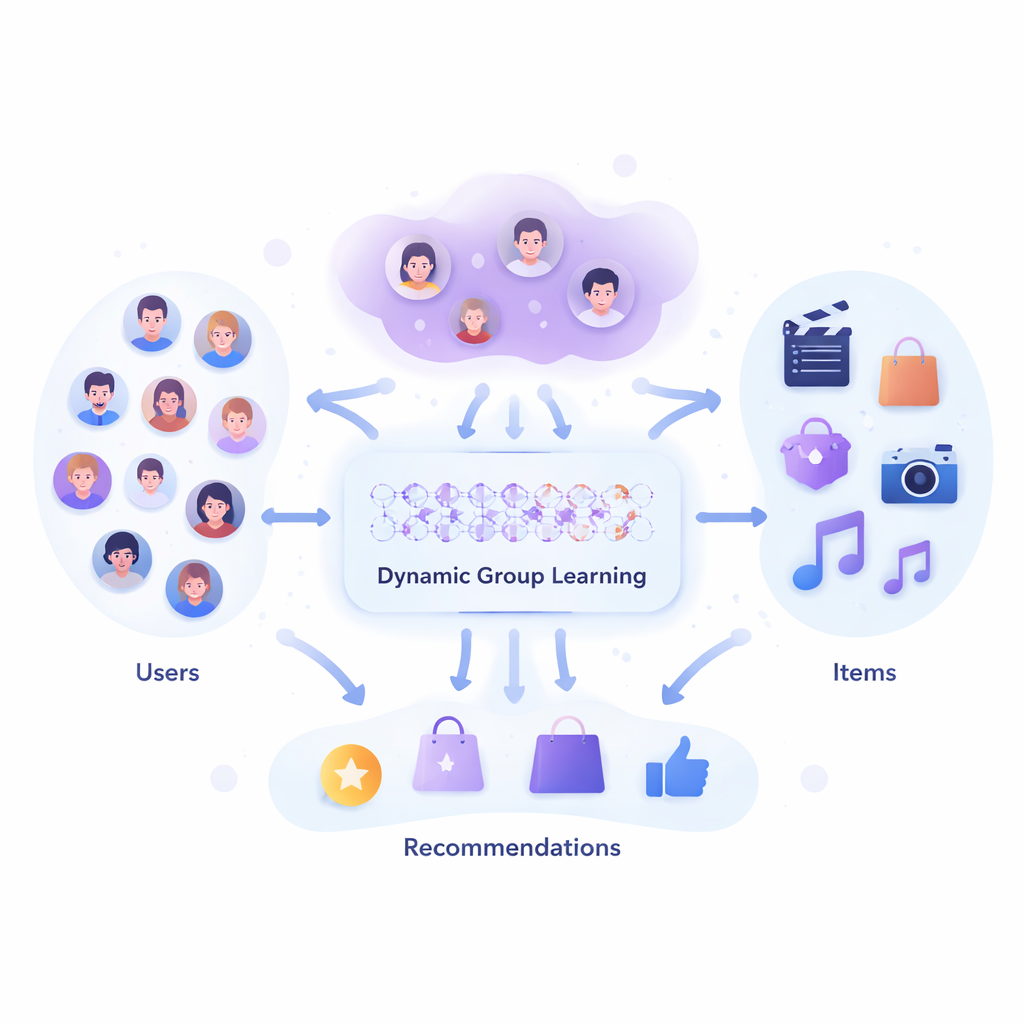
Van vaste teams naar flexibele samenstellingen
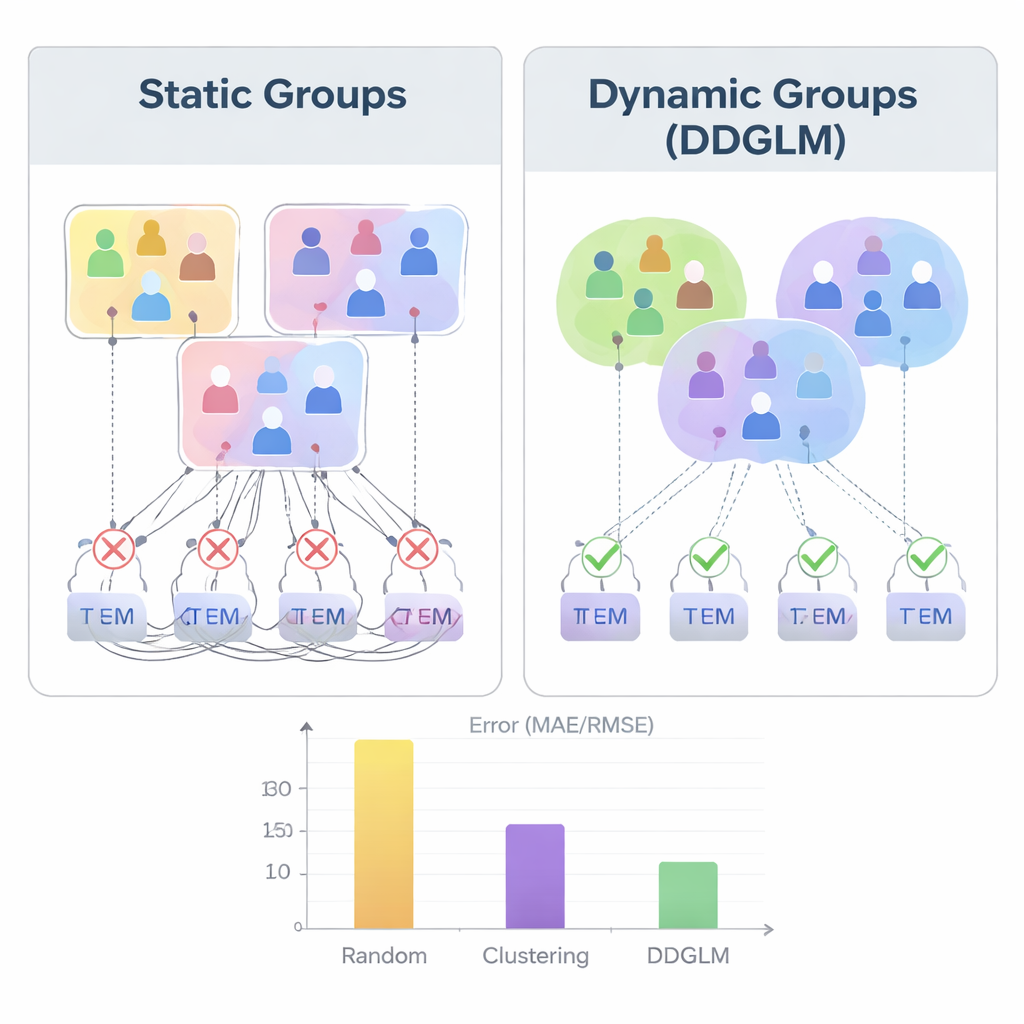
Huidige groepsaanbevelingstools beginnen meestal met een rigide idee van wie bij elkaar hoort: een vooraf gedefinieerde vriendengroep, een klaslokaal, of clusters die eenmalig met een statistisch hulpmiddel zijn gemaakt. Het systeem probeert vervolgens een “goed genoeg” item te vinden voor die bevroren groep. In de praktijk is het echter rommeliger. De mensen die vanavond een film kiezen, kunnen een andere samenstelling hebben dan degenen die volgende maand een vakantie kiezen, en ook de items zelf vormen vaak natuurlijke bundels, zoals afspeellijsten of reisarrangementen. De paper stelt dat groepvorming niet als een aparte, eenmalige stap behandeld moet worden, maar ingebed moet worden in de kern van hoe de recommender uit data leert.
Een verborgen kaart van mensen en dingen
De auteurs introduceren een model dat ze het Deep Dynamic Group Learning Model (DDGLM) noemen. In de kern bouwt het systeem een verborgen kaart waarin zowel mensen als items worden weergegeven als punten in een wiskundige ruimte. In plaats van elke persoon of elk product aan één vaste groep toe te wijzen, laat het model hen eerst tot meerdere overlappende “zachte” groepen behoren met verschillende lidmaatschapsgraden. Een temperatuurregeling verscherpt deze lidmaatschappen naarmate het leren vordert, zodat tegen de tijd dat het systeem in de praktijk wordt gebruikt, elke persoon of elk item effectief in die ene groep terechtkomt die het beste past voor de taak. Deze geleerde groepen zijn niet uitsluitend gebaseerd op zichtbare eigenschappen zoals leeftijd of genre, maar op hoe goed ze het systeem helpen voorspellen welke beoordelingen of keuzes gebruikers daadwerkelijk zullen maken.
Individuen en groepen in overeenstemming brengen
DDGLM gaat een stap verder door te eisen dat het beeld van een persoon als individu en het beeld van die persoon als onderdeel van een groep overeenstemmen. Het voegt een extra term toe aan het leerproces die individuele en groepsrepresentaties zachtjes naar elkaar toe trekt. Dit voorkomt dat groepsprofielen afdwalen naar onrealistische patronen die geen enkel lid echt weerspiegelen, terwijl het model toch gedeelde smaakpatronen kan vastleggen. Met deze representaties kan het systeem vier veelvoorkomende situaties op een uniforme manier afhandelen: het aanbevelen van een enkel item aan één persoon, een item aan een groep, een bundel items aan één persoon, of een bundel aan een groep. In elk geval komen de aanbevelingen neer op eenvoudige vergelijkingen tussen de relevante personen en itemgroepen binnen de verborgen kaart.
Helpen adaptieve groepen echt?
Om te testen of dit idee werkt, voerden de auteurs uitgebreide experimenten uit op bekende filmbekijkingsdatasets genaamd MovieLens-100K en MovieLens-1M. Ze vergeleken DDGLM met methoden die groepen willekeurig vormen, via traditionele clustering, of via eerdere uniforme aanbevelingskaders. Over alle vier scenario’s — individueel, groep, pakket en pakket-naar-groep aanbevelingen — leverde het dynamische model nauwkeurigere beoordelingsvoorspellingen en betere top-aanbevelingen. Het presteerde vooral sterk wanneer groepen of bundels betrokken waren, waar statische benaderingen moeite hadden. Zorgvuldige statistische testen bevestigden dat deze winst niet door toeval verklaard kon worden, en tijdsmetingen lieten zien dat de methode goed schaalt als het aantal gebruikers, items en groepen toeneemt.
Wat dit betekent voor dagelijkse gebruikers
Voor niet-specialisten is de conclusie eenvoudig: recommendersystemen presteren beter wanneer ze nuttige groeperingen ter plekke mogen ontdekken, in plaats van vast te zitten aan rigide groepsdefinities die van tevoren zijn gekozen. Door te leren welke mensen en items van nature samen in de data bewegen — en door die patronen voortdurend bij te werken — kan DDGLM suggesties genereren die beter gedeelde voorkeuren weerspiegelen, of het nu gaat om een film voor een gezin, een afspeellijst voor een feestje, of een vakantiebundel voor een reisgroep. De studie toont aan dat het behandelen van groepvorming als iets wat het systeem zelf kan leren, leidt tot nauwkeurigere, aanpasbare en potentieel eerlijkere aanbevelingen in de digitale diensten die we dagelijks gebruiken.
Bronvermelding: Busireddy, N.R., Kagita, V.R. & Kumar, V. Group learning in recommendation systems: towards adaptive and implicit group modeling. Sci Rep 16, 5918 (2026). https://doi.org/10.1038/s41598-026-36356-x
Trefwoorden: groeprecommendersystemen, dynamisch groepsleren, gepersonaliseerde aanbevelingen, collaborative filtering, deep learning