Clear Sky Science · nl
Topic-analysemethoden benutten om psychologische dimensies in sociale-mediagegevens te verkennen
Waarom onze online woorden ertoe doen
Miljoenen mensen praten elke dag op sociale media over hun gevoelens, vaak opener dan ze dat in persoon zouden doen. Verborgen in deze zee van informele opmerkingen zitten waardevolle aanwijzingen over geestelijke gezondheid, waaronder signalen van depressie of zelfbeschadiging. Deze studie stelt een eenvoudige vraag met grote implicaties: kunnen moderne kunstmatige-intelligentiesystemen door de rumoerige online conversaties heen filteren, betekenisvolle thema’s vinden en professionals helpen psychologische risico’s beter te begrijpen—zonder elk bericht één voor één te lezen?
Chaos omzetten in thema’s
De onderzoekers concentreerden zich op een grote verzameling Reddit-berichten uit het eRisk-initiatief, dat mensen omvat die zeiden dat ze een depressiediagnose hadden en een controlegroep zonder bekende diagnoses. Hun doel was niet om individuen te diagnosticeren, maar om te onderzoeken of topic-analyse—technieken die teksten groeperen op gedeelde thema’s—patronen kan blootleggen die relevant zijn voor geestelijke gezondheid. Omdat taal op sociale media rommelig is, vol slang, typefouten en plotselinge onderwerpenwisselingen, vormt het een realistische maar zeer uitdagende test voor deze methoden.
Drie manieren om te ontdekken waar mensen het over hebben
De studie vergeleek drie verschillende families van topicmodellen. De eerste, Latent Dirichlet Allocation (LDA), is een klassieke methode die kijkt hoe vaak woorden samen in documenten verschijnen. De tweede, BERTopic, gebruikt krachtige moderne taalmodellen om elk bericht in een rijke numerieke representatie om te zetten, clustert vervolgens vergelijkbare berichten en extraheert sleutelwoorden voor elke groep. De derde, TopClus, steunt ook op neurale netwerken en combineert aandachtmechanismen en clustering in een gedeelde wiskundige ruimte. Alle drie werden met standaardinstellingen uitgevoerd om elk 50 topics te produceren, waarmee ze nabootsen hoe veel onderzoekers deze methoden kant-en-klaar zouden gebruiken.
Mensen vragen, niet alleen formules
Om te beoordelen welke topics echt betekenisvol waren, vertrouwde het team niet alleen op automatische scores. Zes getrainde annotatoren onderzochten 150 topics, elk gerepresenteerd door de topwoorden en een handvol centrale berichten. Voor elk topic beoordeelden zij hoe coherent de woordlijst was, hoe coherent de voorbeeldberichten waren en of de woorden en berichten bij elkaar pasten. Ze probeerden ook elk onderwerp, waar mogelijk, een korte, intuïtieve naam te geven. Deze mensgerichte aanpak bracht een belangrijke bevinding aan het licht: numerieke “coherentie”-metriek, die populair is in onderzoek, kwam vaak niet overeen met menselijk oordeel, vooral bij de rommelige tekst van sociale media.
De duidelijke winnaar en wat die onthulde
Op basis van alle menselijke beoordelingen leverde BERTopic duidelijk de meest begrijpelijke en specifieke topics. Annotatoren konden zijn topics veel vaker benoemen dan die van de andere modellen, en ze kwamen onderling op een solide, matig niveau overeen. LDA daarentegen groeperde vaak niet-gerelateerde woorden en berichten die voor de beoordelaars bijna willekeurig aanvoelden. Nadat de beste topics waren geselecteerd, doken de onderzoekers in waar mensen daadwerkelijk over praatten. Sommige thema’s, zoals “Geestelijke gezondheidsproblemen” en “Zelfbeschadiging”, waren sterk verbonden met gebruikers met depressie en bevatten veel berichten die nood of verdriet uitdrukten. Andere waren minder duidelijk klinisch—zoals “Afvallen”, “Genderidentiteit”, “Seksuele dromen” en “Sociale drinketiquette”—maar bleken een hoog aandeel berichten van depressieve gebruikers en veel tekenen van emotionele pijn te bevatten. Een eenvoudige tijdsanalyse liet zien dat de activiteit in sommige van deze gevoelige thema’s sterk toenam tijdens de COVID-19-pandemie, wat overeenkomt met bredere rapporten over verslechtering van de geestelijke gezondheid.
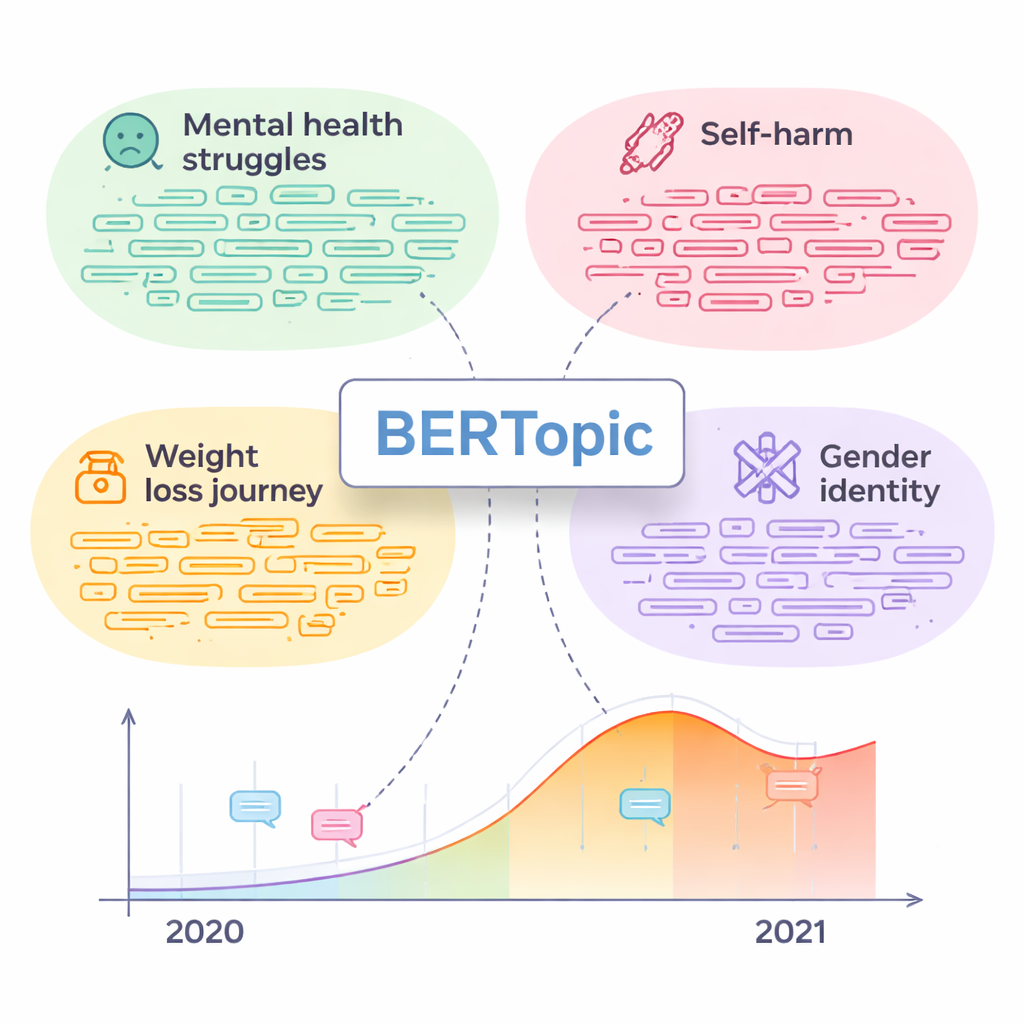
Van online patronen naar hulp in de echte wereld
Om beter te begrijpen hoe ernstig sommige van deze berichten kunnen zijn, gebruikten de auteurs een apart taalmodel om de inhoud ruwweg te koppelen aan items uit een bekend depressievragenlijst (de Beck Depression Inventory). Deze verkennende stap suggereerde dat bepaalde topics, vooral rond geestelijke gezondheidsproblemen, zelfbeschadiging, lichaamsbeeld en genderidentiteit, vaak taal bevatten die geassocieerd wordt met matige tot ernstige depressieve symptomen. De auteurs benadrukken dat dergelijke geautomatiseerde interpretaties geen klinische diagnoses zijn, maar ze kunnen helpen aangeven waar deskundige aandacht het meest dringend nodig is.
Wat dit betekent voor geestelijke gezondheid en technologie
Eenvoudig gezegd toont de studie aan dat de meest geavanceerde topicmodellen van vandaag, met name BERTopic, chaotische sociale-mediagesprekken in duidelijke thema’s kunnen omzetten die overeenkomen met echte psychologische zorgen. Het toont ook aan dat het blindelings vertrouwen op automatische kwaliteitscores riskant is; menselijke beoordeling blijft essentieel wanneer het doel is geestelijke-gezondheidsbeslissingen te ondersteunen. In de toekomst zouden vergelijkbare hulpmiddelen clinici, publieke instanties en onderzoekers kunnen helpen brede trends te monitoren, opkomende risico’s te signaleren en betere preventie-inspanningen te ontwerpen—terwijl de uiteindelijke beoordeling en zorg aan menselijke professionals wordt overgelaten.
Bronvermelding: Couto, M., Parapar, J. & Losada, D.E. Exploiting topic analysis models to explore psychological dimensions in social media data. Sci Rep 16, 6047 (2026). https://doi.org/10.1038/s41598-026-36339-y
Trefwoorden: sociale media en depressie, topicmodellering, patronen in geestelijke gezondheid, online signalen van zelfbeschadiging, taalmodellen in de psychologie