Clear Sky Science · nl
Herkenning van hints in Chinese en Russische diplomatieke discours met behulp van grote taalmodellen
Lezen tussen de regels
Wanneer diplomaten publiekelijk spreken, kan wat ze niet zeggen net zoveel betekenen als de woorden die ze kiezen. Deze studie onderzoekt of moderne kunstmatige intelligentie de subtiele hints en verhulde boodschappen kan oppikken in persconferenties van de Chinese en Russische ministeries van buitenlandse zaken — signalen die menselijke luisteraars vaak missen, maar die internationale betrekkingen kunnen beïnvloeden.
Waarom hints ertoe doen in de wereldpolitiek
Diplomatieke taal is bedoeld om zorgvuldig en beleefd te zijn. Overheden moeten hun belangen verdedigen zonder openlijk rivalen uit te dagen of het publiek ongerust te maken. Als gevolg vertrouwen functionarissen vaak op hints — uitdrukkingen die oppervlakkig neutraal klinken maar stilletjes kritiek leveren, waarschuwen of een politieke houding signaleren. Het verkeerd lezen van zulke hints heeft in het verleden bijgedragen aan crisissen en wantrouwen tussen staten. Het begrijpen van deze indirecte boodschappen is extra moeilijk over talen en culturen heen, waar gedeelde achtergrondkennis niet als vanzelfsprekend kan worden verondersteld.
Van klassieke theorie naar slimme machines
Decennialang hebben taalkundigen en filosofen bestudeerd hoe sprekers meer impliceren dan ze letterlijk zeggen. Vroege theorieën richtten zich vooral op de intenties van de spreker en gingen ervan uit dat een rationele luisteraar de verborgen betekenis kon reconstrueren. Later werk in de “cognitieve pragmatiek” benadrukte dat het begrijpen van hints ook afhangt van de mentale processen van de luisteraar, culturele achtergrond en de omliggende context. Voortbouwend op deze ideeën beschrijven de auteurs hints als gelaagd: de zichtbare formulering (verbaal-semantisch niveau), de cultureel gevormde denkwijzen erachter (linguïstisch-cognitief niveau), en de motieven en strategieën van de spreker, zoals kritiek, waarschuwing of het bewaren van gezichtsverlies (motivationeel-pragmatisch niveau).
Hoe het AI-systeem werd opgebouwd
De onderzoekers verzamelden bijna 1.400 vraag–antwoordfragmenten uit officiële persconferenties van de Chinese en Russische ministeries van buitenlandse zaken die in 2024 plaatsvonden. Deskundige taalkundigen annoteerden handmatig 498 gevallen waarin woordvoerders hintten in plaats van duidelijk te spreken. Zij groepeerden deze in drie typen: “vaste hints” met stabiele, herhaalde bewoording (bijvoorbeeld standaard diplomatieke formuleringen), “culturele hints” waarvan de betekenis afhankelijk is van gedeelde culturele kennis en metaforen, en “contextuele hints” die alleen herkend kunnen worden door nauw naar de directe situatie en motieven te kijken. Deze voorbeelden werden gebruikt om een externe kennisbasis op te bouwen en om een set redeneervormen voor een groot taalmodel te ontwerpen.
Het model leren stap voor stap te redeneren
Het team combineerde twee AI-technieken. Retrieval-Augmented Generation (RAG) laat het model relevante voorbeelden uit de aangepaste hint-database ophalen wanneer het een nieuw persconferentieantwoord verwerkt. Chain-of-Thought (CoT) prompting dwingt het model vervolgens stap-voor-stap te redeneren: identificeer de taal, splits het antwoord in zinnen, controleer op bekende hintpatronen, beslis of een zin een specifiek motief uitdrukt (zoals kritiek of waarschuwing) via een erkende strategie (zoals feitelijke bewering, contrast of ironie), en label het tenslotte als een vaste, culturele, contextuele hint of “geen hint”. Het systeem voert ook een zelfcontrole uit om te waarborgen dat de geïmpliceerde betekenis daadwerkelijk verschilt van de letterlijke bewoording.
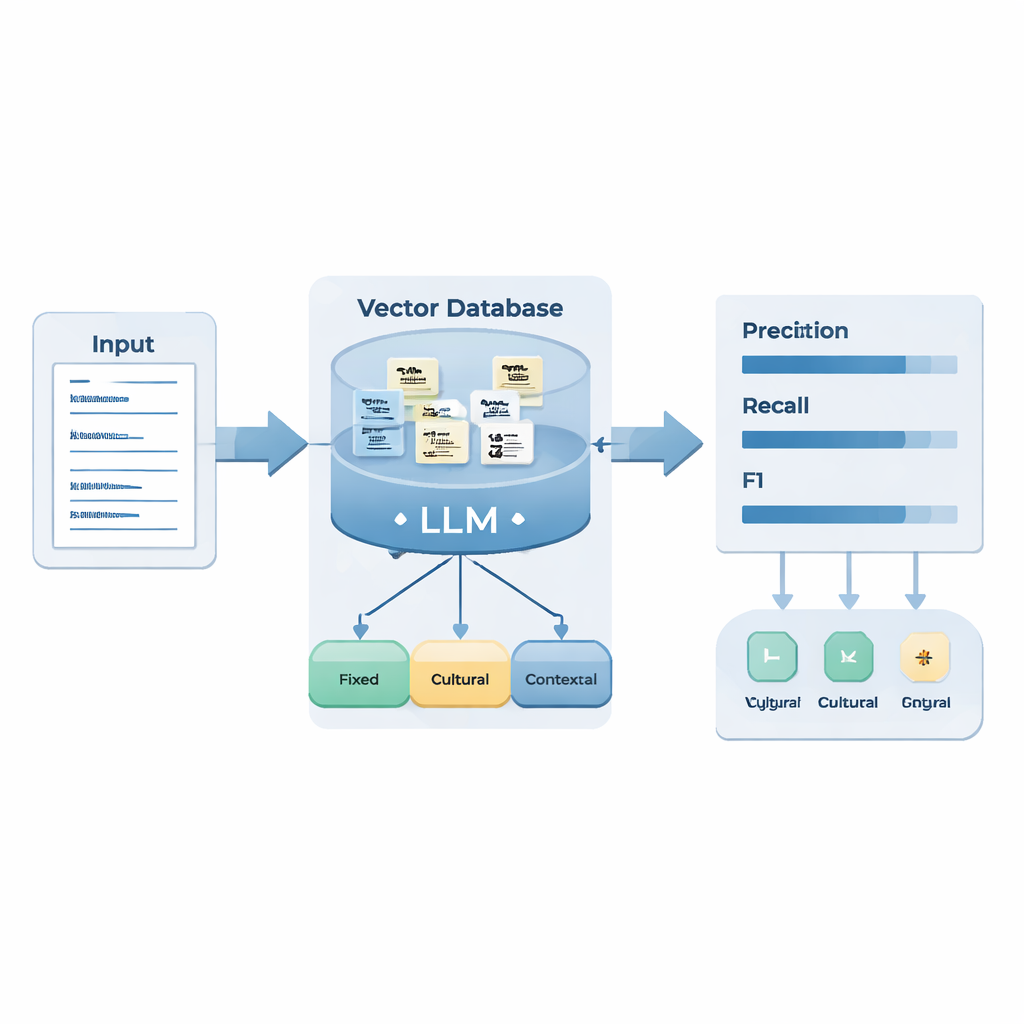
Hoe goed werkte het?
Om het systeem te testen gebruikten de auteurs nieuwe persconferentiegegevens uit 2025 in beide talen. In het algemeen deed het verbeterde model betrouwbaar werk bij het opsporen van verborgen boodschappen: het ving de meeste echte hints op (hoge recall) en bereikte een respectabele balans tussen detecteren en overdetecteren (F1-score 0,83 voor Russisch en 0,76 voor Chinees). Het was vooral sterk bij vaste hints in beide talen, wat de gedachte ondersteunt dat stabiele patronen voor machines het gemakkelijkst te leren zijn. Het had echter meer moeite met Chinese culturele en contextuele hints dan met Russische. De auteurs koppelen dit verschil aan stijlverschillen: Russische diplomatieke taal gebruikt vaak levendige metaforen en scherpe contrasten die kritiek of waarschuwing duidelijk signaleren, terwijl Chinese discours meer leunt op neutrale formulieren, idiomen en contextafhankelijke beleefdheid, die lastiger door het model van letterlijke uitspraken te onderscheiden zijn.
Wat de fouten onthullen — en hoe te verbeteren
Bij nadere beschouwing van de fouten vonden de auteurs drie terugkerende problemen. Soms “las” het model teveel in de tekst en verzon het verborgen betekenissen waar die niet bestonden. Soms ontdekte het een hint maar gaf het de verkeerde type-toewijzing, waardoor de grens tussen vaste en contextuele gevallen vervaagde. En soms behandelde het simpele bewoording als een hint omdat bepaalde gevoelige woorden of bekende patronen aanwezig waren. Om deze zwaktes aan te pakken stelt het artikel voor veel duidelijke “geen-hint” diplomatieke zinnen als negatieve voorbeelden toe te voegen, het systeem te dwingen zijn afleidingen nauwer te verankeren in de feitelijke vraag en omliggende context, zinnen meerdere keren tegen de kennisbasis te matchen met herschrijvingen, en een prefilter- en zelfevaluatiestap in te voegen die vraagt: is dit al expliciet, of echt impliciet?
Waarom dit ertoe doet voor de rest van ons
Voor niet-specialisten is de belangrijkste conclusie dat grote taalmodellen analisten al kunnen helpen grote hoeveelheden officiële verklaringen te doorzoeken en plekken te signaleren waar regeringen tussen de regels spreken. Tegelijk benadrukt de studie hoe sterk diplomatie afhankelijk is van cultuur, geschiedenis en stijl — factoren die zelfs voor geavanceerde AI uitdagend blijven. Door taalkundige theorie te verenigen met moderne AI-instrumenten wijst dit werk op betrouwbaardere systemen voor het volgen van subtiele signalen in de wereldpolitiek, terwijl het ook duidelijk maakt dat menselijk oordeel en cross-culturele expertise nog steeds essentieel zijn om te interpreteren wat onuitgesproken blijft.
Bronvermelding: Guo, Y., Wang, X. Hint recognition in Chinese and Russian diplomatic discourse using large language models. Sci Rep 16, 5751 (2026). https://doi.org/10.1038/s41598-026-36338-z
Trefwoorden: diplomatieke taal, impliciete betekenis, grote taalmodellen, cross-linguale analyse, retrieval-augmented generatie