Clear Sky Science · nl
Diep inception-neuraal netwerk met residuele verbindingen voor Tamil handgeschreven tekenherkenning
Handschrift bewaren in het digitale tijdperk
Van oude palmbladvellen tot alledaagse aantekeningen: een groot deel van het geschreven erfgoed van het Tamil leeft nog op papier. Het omzetten van deze rijke verzameling handgeschreven pagina’s naar doorzoekbare digitale tekst is essentieel om cultuur te bewaren, onderwijs te ondersteunen en betere taaltechnologieën te bouwen. Dit artikel presenteert een nieuw computervisionsysteem, genoemd TamHNet, dat Tamil handschrift leest met vrijwel perfecte nauwkeurigheid, zelfs wanneer letters verwarrend veel op elkaar lijken.
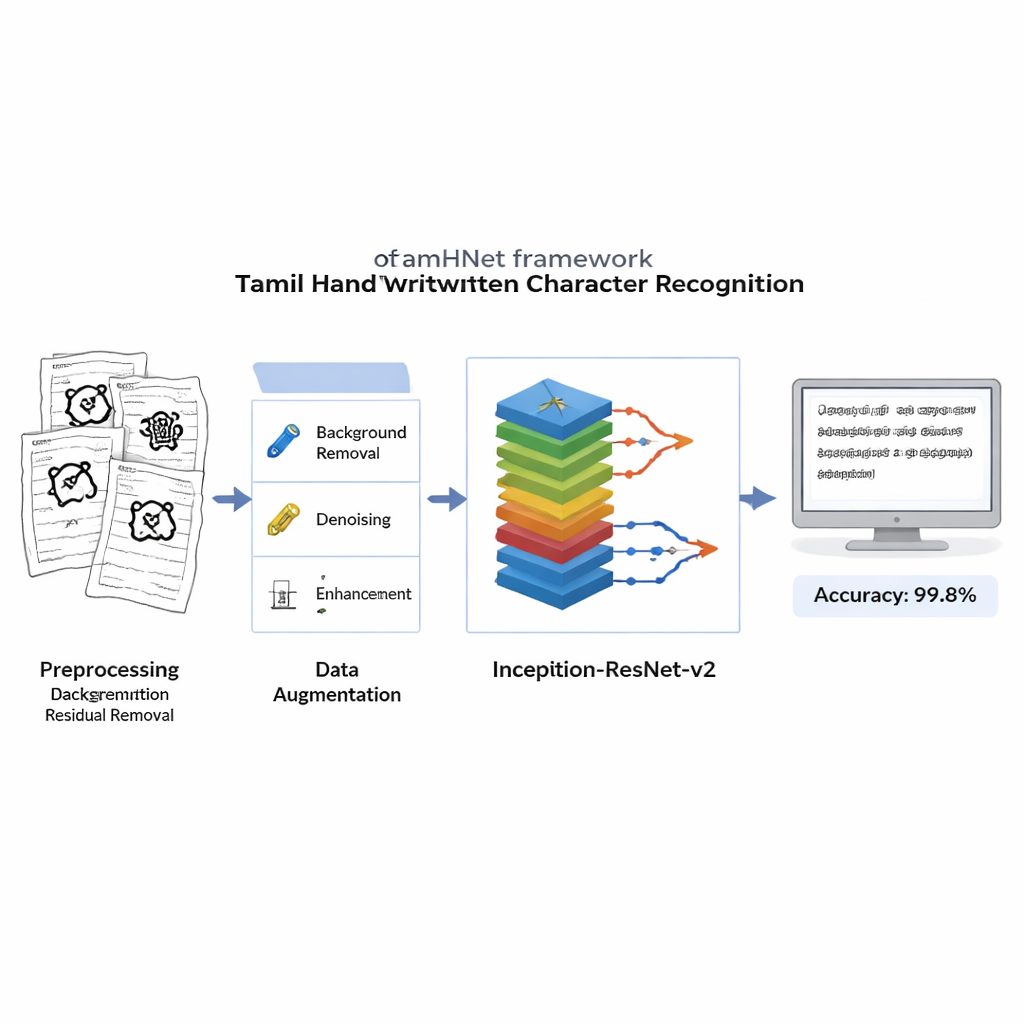
Waarom Tamil-letters moeilijk zijn voor computers
Het Tamil wordt door meer dan 80 miljoen mensen gesproken en gebruikt een schrift met 247 tekens, waaronder klinkers, medeklinkers en veel combinaties daarvan. Veel letters verschillen alleen door kleine krullen of extra streken, en schrijvers variëren sterk in hoe ze elk teken vormen. Paaren zoals எ/ஏ of ஒ/ஓ kunnen op het eerste gezicht bijna identiek lijken, en tekens zoals ல en வ zijn gemakkelijk met elkaar te verwarren. Eerdere computerprogramma’s en zelfs moderne systemen voor machinaal leren hadden vaak moeite met deze subtiliteiten, wat leidde tot fout gelezen woorden en onbetrouwbare digitalisering van documenten.
Een realistische dataset voor handschrift opbouwen
Om hun systeem onder realistische omstandigheden te trainen en testen, creëerden de onderzoekers een nieuwe Tamil Isolated Character Dataset met handgeschreven voorbeelden van 1.000 universiteitsstudenten. In plaats van te vertrouwen op synthetische of computergemaakte afbeeldingen, verzamelden ze echte pen-op-papier karakters die 12 klinkers, 18 medeklinkers en 214 veelvoorkomende combinaties omvatten. Het team labelde deze voorbeelden zorgvuldig en maakte de dataset openbaar beschikbaar zodat andere groepen methoden kunnen vergelijken en voortbouwen op dit werk. Door het schrift te organiseren in 104 basis-symbolen die alle 247 tekens omvatten, verminderden ze redundantie terwijl ze nog steeds het volledige scala aan vormen weergeven die in echt handschrift voorkomen.
Afkaderen, uitrekken en de afbeeldingen onderwijzen
Voordat er leren plaatsvindt, wordt elke gescande afbeelding gereinigd om ruisende achtergronden, vlekken en ongelijkmatige belichting te verwijderen, terwijl de fijne streken die elk teken definiëren behouden blijven. De afbeeldingen worden omgezet naar scherpe zwart-wit beelden en aangepast naar een standaardformaat zodat de computer elk voorbeeld op dezelfde manier ziet. Om het systeem robuust te maken tegen verschillende schrijfgewoonten, gebruiken de auteurs gecontroleerde vervormingen: ze verschuiven sleutelpunten in de afbeelding lichtjes en passen zachte warping toe, waarmee nieuwe versies van elk teken worden gegenereerd die voor een mens nog steeds als hetzelfde letterteken herkenbaar zijn. Deze uitgebreide trainingsset helpt het model tekens te herkennen, zelfs wanneer ze schuin geschreven zijn, ingedrukt of met ongebruikelijke verhoudingen.
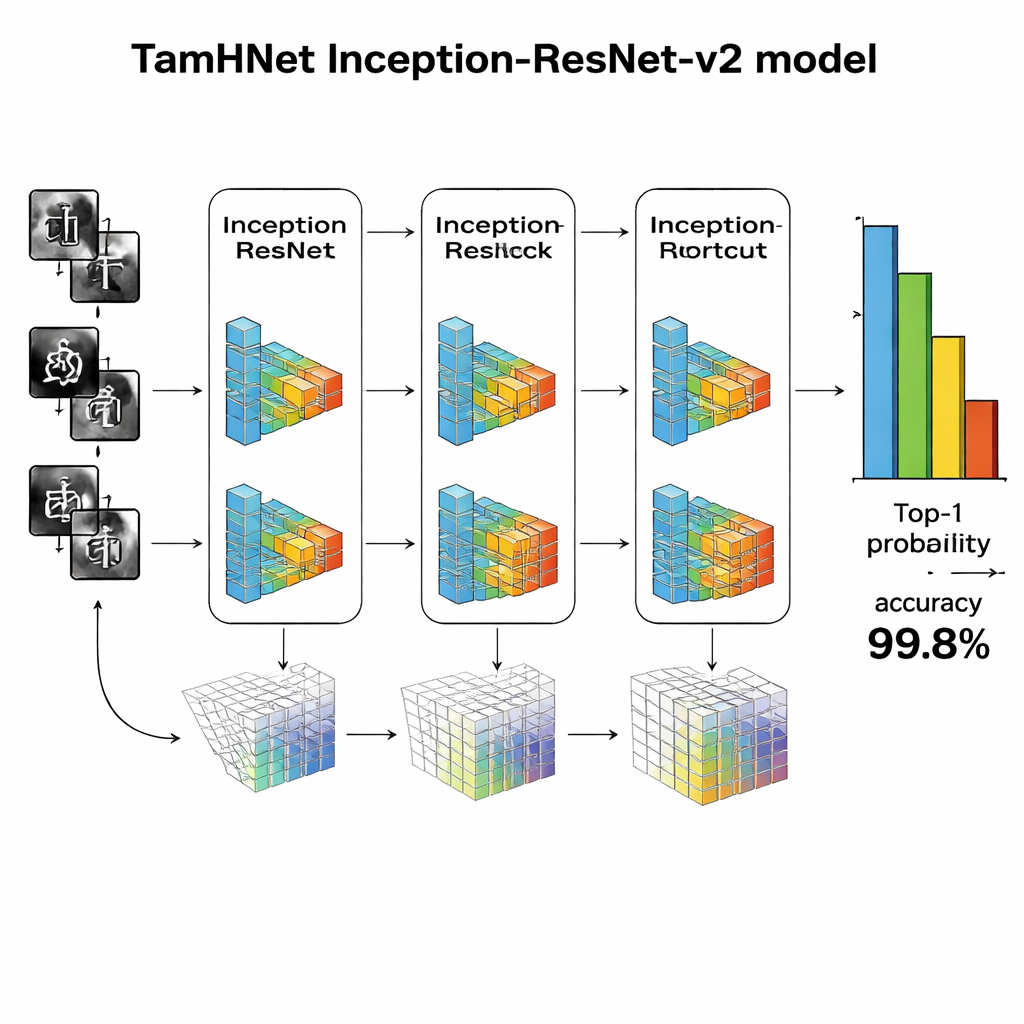
Een diep netwerk dat subtiele verschillen leert
In het hart van TamHNet staat een krachtig deep-learning-architectuur genaamd Inception-ResNet-v2, oorspronkelijk ontworpen voor algemene objectherkenning. De auteurs passen dit netwerk aan en fijn-tunen het specifiek voor Tamil-handschrift. Het model verwerkt elke afbeelding door vele lagen die ruwe pixels geleidelijk omzetten in hoogwaardiger patronen, zoals randen, krommen en tekenonderdelen. Speciale snelkoppelingen, bekend als residuele verbindingen, stabiliseren de training en helpen het netwerk zich te richten op kleine maar cruciale verschillen tussen gelijkaardige letters. In plaats van alle interne instellingen tegelijk aan te passen, ‘ontdooien’ de onderzoekers selectief de meest nuttige lagen en stemmen die af voor deze taak. Ze gebruiken een optimalisatietechniek genaamd Adam, die automatisch aanpast hoe snel elke parameter verandert, waardoor het netwerk efficiënt kan leren van complex en soms rommelig handschrift.
Hoe goed het systeem handschrift leest
De onderzoekers evalueren TamHNet op de nieuwe dataset met behulp van standaardmaatstaven voor herkenningskwaliteit. Het systeem behaalt ongeveer 99,8% nauwkeurigheid over 104 karakterklassen en overtreft daarmee een breed scala aan eerdere methoden gebaseerd op support vector machines, traditionele convolutionele netwerken en andere geavanceerde deep-learningontwerpen. Gedetailleerde tests tonen aan dat zelfs letters met extreem vergelijkbare vormen in de meeste gevallen correct worden onderscheiden, en statistische krommen bevestigen dat het model zeer zelden het ene teken met het andere verwisselt. Vergeleken met eerder werk is dit een duidelijke stap voorwaarts in betrouwbaarheid voor Tamil handgeschreven tekenherkenning.
Wat dit betekent voor lezers en archieven
Voor niet-specialisten is de belangrijkste conclusie dat computers dramatisch beter worden in het lezen van Tamil-handschrift. Een systeem zoals TamHNet kan hulpmiddelen aandrijven die stapels notitieboekjes, historische manuscripten en handgeschreven formulieren omzetten naar doorzoekbare digitale tekst met minimale menselijke correctie. Hoewel het huidige model nog niet bepaalde puntgebaseerde symbolen en oudere varianten van het schrift afhandelt, schetsen de auteurs plannen om het uit te breiden naar oude schrijftypen. In praktische termen brengt dit onderzoek ons dichter bij grootschalige, nauwkeurige digitalisering van Tamil-documenten, wat helpt het culturele erfgoed te beschermen en geschreven kennis makkelijker toegankelijk te maken voor toekomstige generaties.
Bronvermelding: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Trefwoorden: Tamil handgeschreven tekenherkenning, optische tekenherkenning, deep learning, Inception-ResNet, digitale conservering