Clear Sky Science · nl
Prestatievergelijking van grote taalmodellen bij kennisbeoordeling van boron neutron capture-therapie
Slimme tutors voor een nieuw soort kankerbestraling
Boron neutron capture-therapie, of BNCT, is een opkomend type bestralingstherapie dat erop gericht is tumoren te vernietigen terwijl omliggend gezond weefsel wordt gespaard. Naarmate deze complexe therapie zich verspreidt van laboratoria naar ziekenhuizen, moeten artsen en leerlingen veel nieuwe, gespecialiseerde kennis beheersen. Deze studie stelt een actueel vraagstuk: kunnen de tegenwoordig populaire AI-chatbots helpen bij het onderwijzen en ondersteunen van BNCT, en zo ja, hoe betrouwbaar zijn ze?
Wat maakt BNCT anders dan reguliere bestraling?
BNCT werkt heel anders dan standaard röntgen- of protonbehandelingen. Patiënten krijgen medicijnen met een speciale vorm van boor die zich ophoopt in kankercellen. Wanneer die cellen later worden blootgesteld aan een neutronenbundel, ondergaan de booratomen een kleine kernreactie die deeltjes met een korte reikwijdte vrijmaakt, waardoor de kankercel van binnenuit wordt gedood terwijl het omliggende weefsel grotendeels ongedeerd blijft. Deze sterk gerichte aanpak is vooral veelbelovend voor moeilijk te behandelen tumoren of tumoren met weinig zuurstof. Tot voor kort was BNCT afhankelijk van kernreactoren als neutronenbron, wat het klinische gebruik beperkte. De goedkeuring van accelerator-gebaseerde BNCT-apparaten in Japan in 2020, en de komst van nieuwe centra in landen zoals China, hebben BNCT een realistische optie voor meer patiënten gemaakt — en een dringende behoefte aan gerichte training en certificering gecreëerd.
Vier toonaangevende AI-systemen op de proef gesteld
Om te zien hoe goed algemene chatbots BNCT-onderwerpen behandelen, stelden de onderzoekers een toets van 47 vragen samen die basisideeën, de nieuwste onderzoeken, klinische praktijk en berekenings- en redeneertaakjes besloeg. De vragen waren zowel in het Chinees als in het Engels geschreven en bevatten eenvoudige feiten (zoals definities) en meer veeleisende problemen die logica of rekentaligheden vereisten. Vier grote AI-families — vertegenwoordigd door veelgebruikte systemen van verschillende bedrijven — werden elk getest over vijf afzonderlijke perioden, in twee talen en met twee manieren van vragen stellen (eenvoudige directe vragen en vragen verpakt in een korte klinische casus). Menselijke oncologie-specialisten beoordeelden elk antwoord aan de hand van een standaardsleutel, en het team hield ook bij hoe vaak de AI’s onzekerheid erkenden door dingen te zeggen als “Ik weet het niet.”
Wie beantwoorde het beste, en bij wat voor vragen?
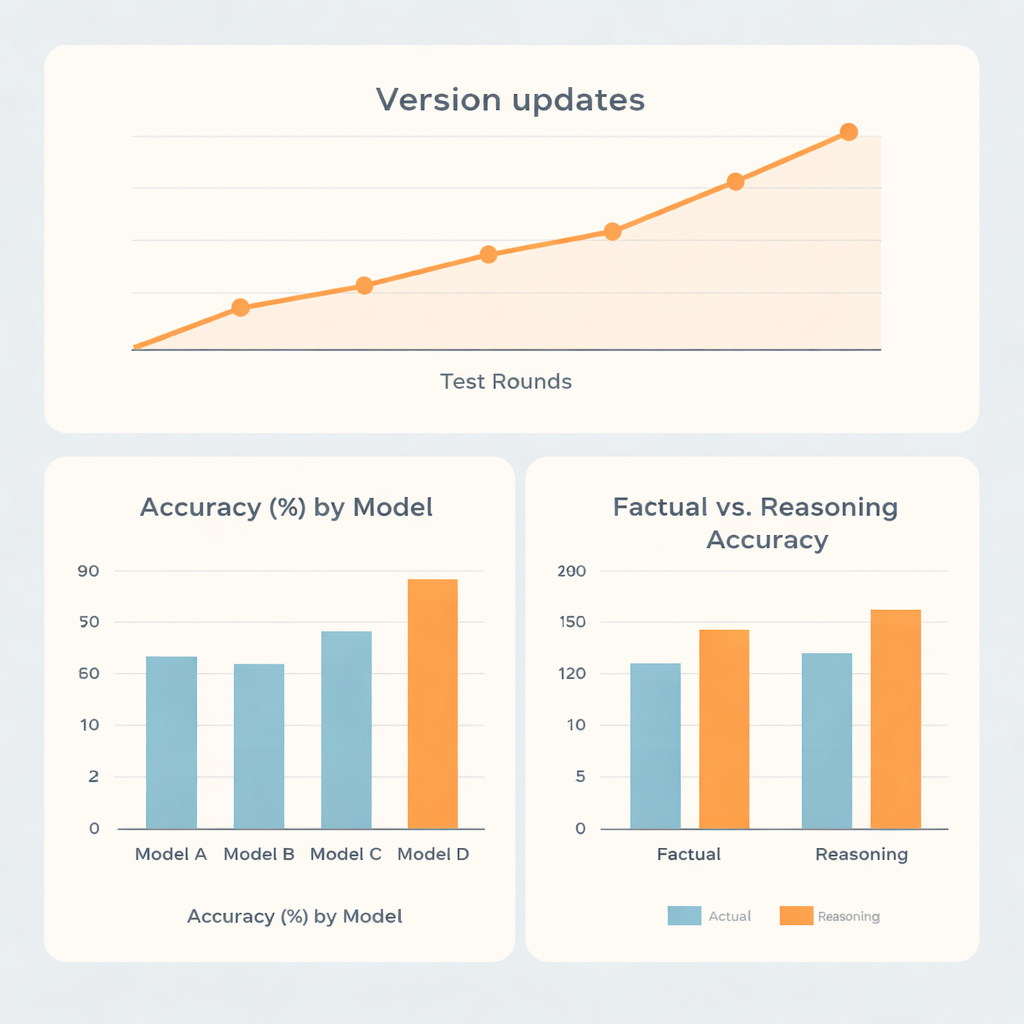
In het algemeen presteerden twee modelfamilies duidelijk beter dan de andere twee. Het sterkste systeem haalde ongeveer 73% nauwkeurigheid, en de op één na beste ongeveer 70%, terwijl de overige modellen rond de 62% en 56% scoorden. Interessant genoeg blonken de toppers niet alleen uit in uit het hoofd geleerde feiten. Ze waren merkbaar beter in vragen die zwaar op redeneren leunden dan in eenvoudige feitenkennis, wat suggereert dat deze systemen relatief sterk zijn in meerstapsdenktaken, zoals dosisberekeningen of planningsachtige problemen, binnen dit smalle medische domein. Eén model liet vrijwel dezelfde scores zien op feitelijke en redeneeritems, terwijl een ander model ondanks een iets betere prestatie op redeneren achterbleef in de totaalscore.
Updates, talen en de bereidheid om “Ik weet het niet” te zeggen
Aangezien AI-systemen regelmatig worden bijgewerkt, onderzochten de onderzoekers ook hoe de prestaties veranderden over vijf testronden verspreid van eind 2023 tot midden 2025. Grote versie-upgrades leidden doorgaans tot duidelijke sprongen in nauwkeurigheid, terwijl kleine aanpassingen binnen dezelfde versie weinig uitmaakten. Eén familie klom in die periode van minder dan 60% naar meer dan 80% nauwkeurigheid, wat benadrukt hoe snel de technologie vordert. Verrassend genoeg hadden de vraagtaal (Chinees of Engels) of de vraag direct werd gesteld versus verpakt in een rollenspelprompt slechts kleine effecten vergeleken met de aangeboren sterktes van elk model. Meer opvallend waren de verschillen in hoe open de systemen waren wanneer ze het mis hadden. Sommige modellen erkenden onzekerheid bij bijna één op de vijf foutieve antwoorden, terwijl een ander zelden zoiets deed en vaak zelfverzekerde maar foutieve antwoorden gaf.
Wat dit betekent voor artsen, studenten en patiënten
De studie concludeert dat de beste algemene chatbots van vandaag al redelijk nauwkeurige uitleg en oefenvragen over BNCT kunnen bieden, waardoor ze veelbelovende hulpmiddelen zijn voor onderwijs en zelfstudie. Geen enkel systeem is echter nog betrouwbaar genoeg om alle BNCT-vragen correct te beantwoorden, en hun manieren om onzekerheid uit te drukken — of te verbergen — verschillen op manieren die belangrijk zijn voor de veiligheid. Vooralsnog zijn deze tools het beste te zien als slimme assistenten die deskundig oordeel kunnen ondersteunen, maar niet vervangen. De auteurs betogen dat speciaal voor BNCT ontwikkelde AI-modellen, samen met duidelijke normen voor hoe zulke hulpmiddelen in klinieken en leslokalen gebruikt moeten worden, nodig zullen zijn voordat AI een betrouwbare frontlinie-rol kan spelen in deze sterk gespecialiseerde vorm van kankerzorg.
Bronvermelding: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Trefwoorden: boron neutron capture-therapie, kankerbestraling, medische opleiding, kunstmatige intelligentie, grote taalmodellen