Clear Sky Science · nl
Object-gestuurde contrastieve taal-beeld voortraining voor zero-shot doelherkenning
Slimmere ogen voor drukke luchten en zeeën
Moderne beveiligings- en hulpverleningssystemen vertrouwen op camera’s in de lucht en op zee om vliegtuigen, schepen en andere kritieke objecten te spotten. Maar het computers leren om een jachtvliegtuig te onderscheiden van een passagiersvliegtuig, of een oorlogsschip van een vrachtschip, is verrassend moeilijk wanneer scènes druk zijn, data schaars zijn en voortdurend nieuwe typen materieel verschijnen. Dit artikel introduceert OG-CLIP, een nieuw AI-systeem dat erop gericht is militaire en civiele doelen te herkennen waarop het nooit expliciet is getraind, door grootschalige voorkennis te combineren met een scherpere visuele focus op de objecten die het meest tellen.
Waarom traditionele AI het doel mist
De meeste beeldherkenningssystemen leren van enorme verzamelingen gelabelde foto’s: elke afbeelding is gekoppeld aan een vaste lijst categorieën, zoals “kat” of “auto”. Die aanpak faalt in gespecialiseerde domeinen zoals defensie en remote sensing, waar data gevoelig zijn, labeling deskundigen vereist en de verscheidenheid aan materieel enorm is. Nieuwere visie-taal modellen zoals CLIP koppelen beelden aan korte tekstbijschriften van het web, waardoor ze nieuwe begrippen kunnen herkennen die in woorden worden beschreven. Toch hebben deze modellen in militaire beelden nog steeds moeite: bijschriften zijn vaak vaag, achtergronden zoals wolken en golven domineren de pixels, en hun interne representaties zijn niet flexibel genoeg om efficiënt te draaien op alles van kleine drones tot krachtige servers. OG-CLIP pakt al deze drie problemen direct aan.
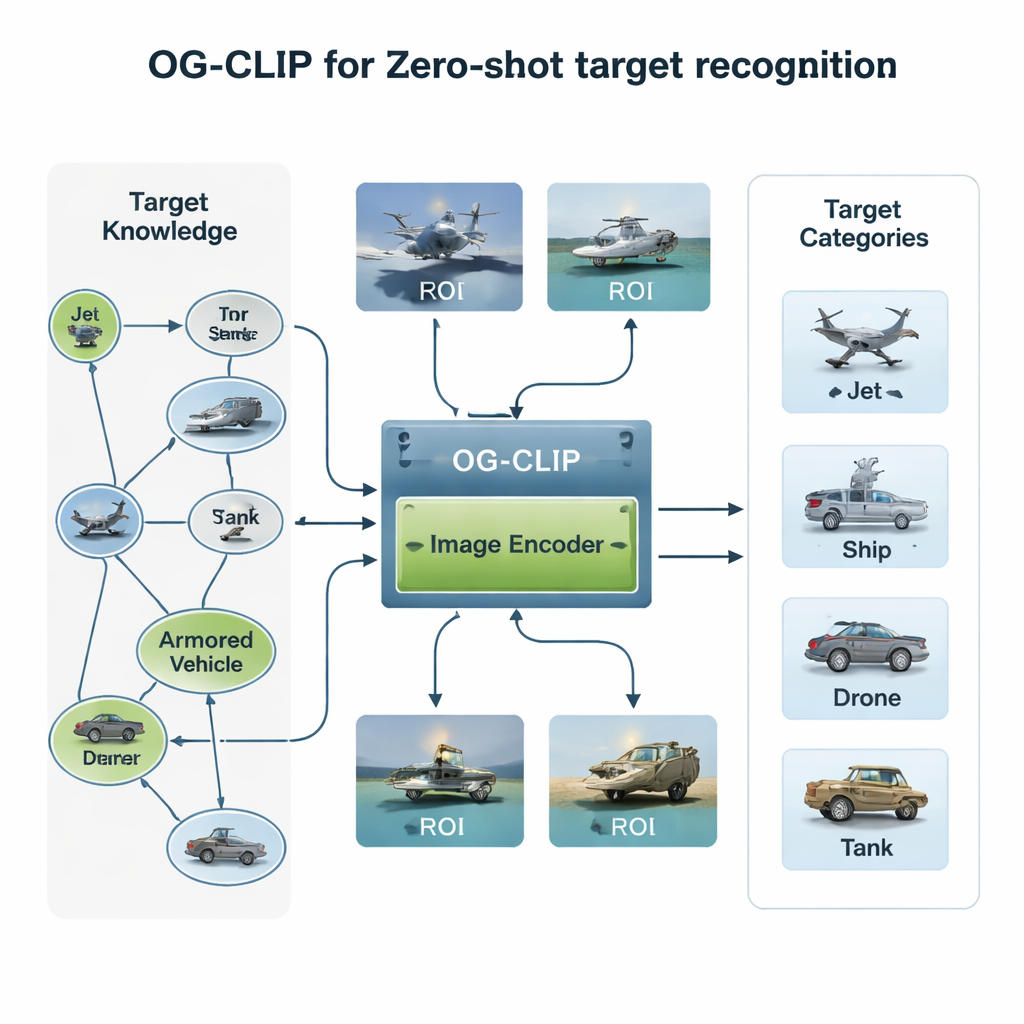
Een kennisrijke trainingswereld opbouwen
Het eerste ingrediënt van OG-CLIP is een zorgvuldig opgebouwd trainingsuniversum. De auteurs stelden een database samen van 5.000 soorten doelen—variërend van jachtvliegtuigen en bombardiers tot oorlogsschepen en civiele vliegtuigen—en organiseerden deze in een gedetailleerde kennisgraf. Elke invoer bevat gestructureerde feiten zoals bereik, gewicht en bewapening, afkomstig uit openbare defensiereferenties, encyclopedieën en technische documenten. Vervolgens verzamelden ze ongeveer een miljoen afbeeldingen uit publieke datasets, webzoekopdrachten, oudere interne archieven en zelfs gesimuleerde scènes uit game-engines. Om de data betrouwbaar te houden, clusterden ze afbeeldingen met een bestaand model om uitschieters te vinden, gevolgd door deskundige beoordeling, en filterden ze slechte labels eruit. Ten slotte gebruikten ze geavanceerde taal-beeld hulpmiddelen om de kennisgraf om te zetten in rijke, natuurlijke taalbeschrijvingen van elke afbeelding, zodat het systeem niet alleen leert “dit is een straalvliegtuig”, maar ook “een smalstaandig vliegtuig met omhoog gebogen winglets” of “een stealthbommenwerper met een vliegende-vleugelvorm.”
Het model leren de ruis te negeren
Een tweede innovatie zit in waar het model kijkt. In veel satelliet- of luchtfoto’s beslaat het daadwerkelijke schip of vliegtuig slechts een klein stukje, omgeven door afleidende lucht, zee of terrein. OG-CLIP voegt een region-of-interest (ROI)-module toe die nabootst hoe een mens vluchtig naar het kernobject kijkt in plaats van naar het hele beeld. Een state-of-the-art segmentatietool omlijnt automatisch waarschijnlijk objecten in de afbeelding en produceert zachte maskers die het doel benadrukken en de achtergrond dimmen. Deze maskers worden, samen met de originele afbeelding, in de visuele backbone van het model gevoed, zodat de aandacht zich natuurlijk concentreert op onderscheidende kenmerken zoals vleugelvorm, dekindeling of silhouet van de romp. Dit plug-in-ontwerp kan aan bestaande systemen worden toegevoegd zonder hun kernarchitectuur te herschrijven, waardoor ze een meer “object-gestuurde” blik krijgen.

Detail afstemmen op de hardware
Het derde onderdeel behandelt een praktisch maar cruciaal punt: niet alle apparaten kunnen hetzelfde detailniveau aan. Een grondstation voor satellieten kan rijke, hoog-dimensionale kenmerken verwerken, terwijl een kleine drone behoefte heeft aan snellere, lichtere berekeningen. Traditionele methoden leggen één waarde voor features vast, of trainen meerdere afzonderlijke modellen voor verschillende groottes. OG-CLIP gebruikt in plaats daarvan een “Matryoshka”-achtige representatie, die informatie op meerdere detailniveaus in één vector verpakt, als geneste poppen. Het systeem kan kortere of langere delen van deze vector afsnijden—grovere of fijnere beschrijvingen van wat er in de afbeelding staat—zonder opnieuw te trainen. Een weegmechanisme stimuleert elk niveau om de meest bruikbare informatie voor classificatie vast te houden, en een extra verliescomponent duwt de niveaus semantisch consistent te blijven met elkaar.
Hoe presteert het in de praktijk?
Om OG-CLIP te testen, bouwden de onderzoekers een uitdagende evaluatieset van 99 doelcategorieën, waaronder 51 typen militaire vliegtuigen, 29 typen oorlogsschepen en 19 civiele of gemengde doelen. Cruciaal is dat geen van deze categorieën in de trainingsdata voorkomt, zodat het systeem moet vertrouwen op zijn aangeleerde begrip van taal en visuele patronen—een “zero-shot” test. Vergeleken met verschillende sterke CLIP-gebaseerde baselines verbeterde OG-CLIP de gemiddelde nauwkeurigheid met meer dan 11 procentpunten, en bereikte het 84,28 procent overall. Het presteerde vooral goed in drukke, complexe scènes en bij het maken van fijne onderscheidingen tussen vergelijkbare modellen, zoals verschillende jachtvliegtuigen, waar de ROI-module en kennisrijke beschrijvingen het een duidelijk voordeel gaven. Ablatiestudies toonden aan dat elk component—de kennisgrafdata, de ROI-focus en de adaptieve representaties—meetbare bijdragen leverde.
Wat betekent dit voor monitoring in de echte wereld
Voor niet-specialisten is de belangrijkste boodschap dat OG-CLIP een stap is naar beveiligings- en monitoringsystemen die onbekende vliegtuigen en schepen betrouwbaarder kunnen herkennen op echte beelden, zelfs wanneer gelabelde voorbeelden schaars zijn. Door gestructureerde deskundige kennis, automatische focus op het object van belang en aanpasbare detailniveaus te combineren, maakt de aanpak visie-taal AI zowel slimmer als praktischer. Buiten defensie kunnen vergelijkbare ideeën helpen bij milieu-monitoring, rampenbestrijding en industriële inspectiesystemen om complexe scènes te begrijpen terwijl ze op een breed scala aan hardware draaien.
Bronvermelding: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Trefwoorden: zero-shot herkenning, visie-taal modellen, objectdetectie, remote sensing, kennisgrafen