Clear Sky Science · nl
IASUNet: gebouwextractie gebaseerd op verbeterde attention Swin-UperNet
Waarom het belangrijk is elk gebouw vanuit de ruimte te herkennen
Nu steden groeien en het klimaat verandert, is het cruciaal om precies te weten waar gebouwen staan — en hoe ze in de loop van de tijd veranderen. Van het plannen van veiligere wijken en het opsporen van illegale bouw tot het sturen van hulp na overstromingen of aardbevingen: gedetailleerde gebouwkaarten zijn een kerncomponent van slimme, veerkrachtige steden. Dit artikel introduceert IASUNet, een nieuw kunstmatig-intelligentiesysteem dat automatisch gebouwen herkent in hoge-resolutie satellietbeelden met opmerkelijke precisie, zelfs in rommelige, dichtbebouwde echte scènes.
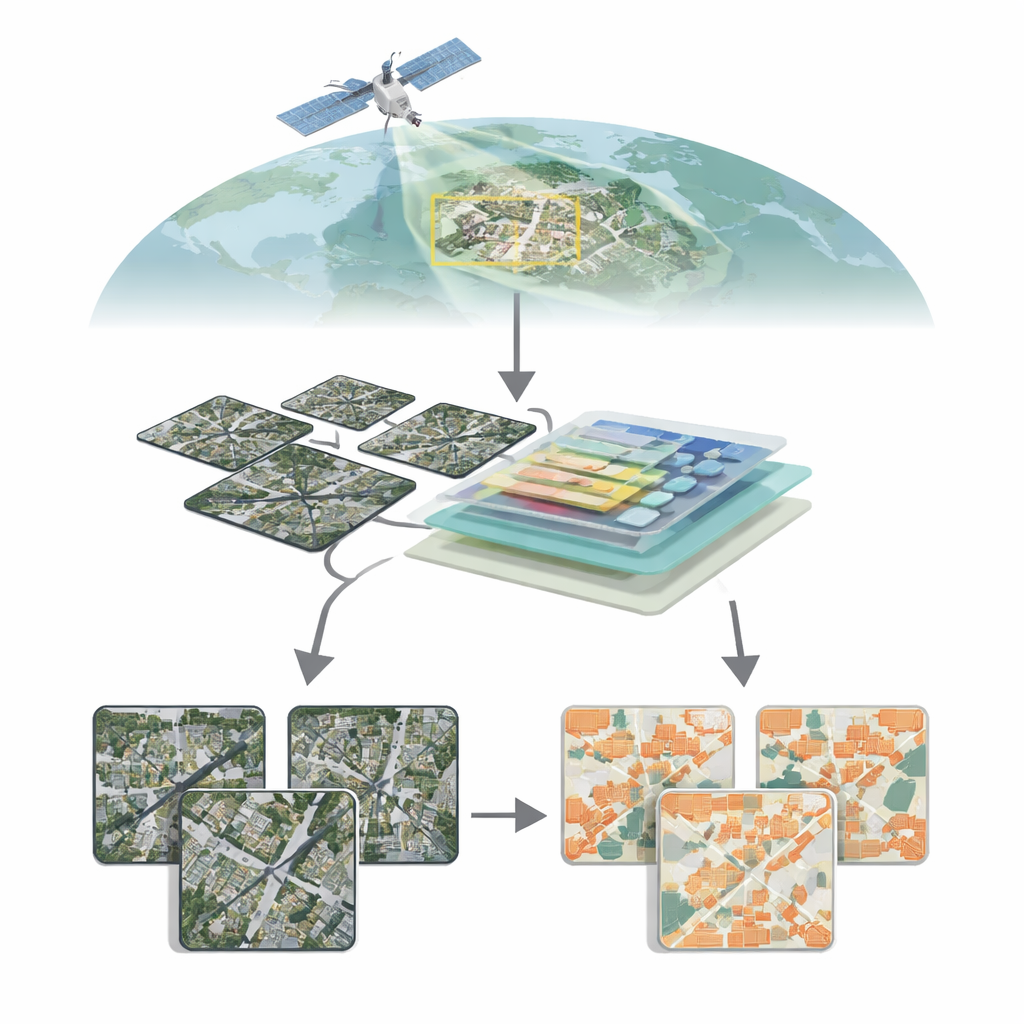
Steden vanuit de lucht bekijken
Moderne satellieten kunnen de aarde fotograferen met een uitzonderlijke detaillering, waarbij individuele daken, wegen en zelfs smalle steegjes zichtbaar worden. Het omzetten van deze zee van pixels in schone gebouwkaarten is echter allesbehalve eenvoudig. Gebouwen variëren enorm in grootte, vorm, kleur en omgeving: glazen torens in het stadscentrum, lage huizen in de buitenwijken, verspreide landbouwschuren op het platteland. In landelijke of gemengde gebieden beslaan gebouwen soms slechts een klein deel van een beeld, terwijl vegetatie, grond en water domineren. Traditionele computervisie-methoden, gebaseerd op convolutionele neurale netwerken, hebben vaak moeite het grotere geheel van een scène te vatten en tegelijk fijne grenzen te respecteren, wat leidt tot gemiste kleine structuren of vage randen.
Een slimmere aandacht voor detail
IASUNet pakt deze uitdagingen aan door twee krachtige ideeën te combineren: een Transformer-gebaseerde encoder genaamd Swin Transformer en een flexibele decoder bekend als UperNet. De Swin Transformer verdeelt een afbeelding in veel kleine patches en leert hoe deze zich tot elkaar verhouden over de hele scène, in plaats van alleen binnen een venster met vaste grootte te kijken. Dit helpt het model om bredere context te begrijpen — bijvoorbeeld of een heldere rechthoek zich binnen een dicht stedelijk blok bevindt of in een geïsoleerd veld — terwijl het toch detail behoudt. Daarbovenop integreren de auteurs een aandachtmechanisme genaamd Convolutional Block Attention Module (CBAM) op meerdere plaatsen. CBAM leert, kanaal voor kanaal en regio voor regio, welke beeldkenmerken waarschijnlijk bij gebouwen horen en welke achtergrondruis is, waarbij het eerste wordt versterkt en het laatste wordt onderdrukt voordat de decoder alles weer samenvoegt tot een volledige gebouwkaart.
De balans herstellen wanneer gebouwen zeldzaam zijn
Een andere praktische uitdaging is onbalans: in veel satellietbeelden tonen de meeste pixels wegen, velden, bomen of water, terwijl gebouwen slechts kleine eilandjes vormen. Standaard trainingsmethoden neigen ertoe wat het vaakst voorkomt te bevoordelen, wat het risico met zich meebrengt dat minder frequente gebouwen als bijzaak worden behandeld. Om dit tegen te gaan passen de auteurs een verliesfunctie aan genaamd Focal Cross‑Entropy. Deze strategie vermindert de invloed van “eenvoudige” achtergrondpixels en versterkt het effect van moeilijk te classificeren gebouwpixels tijdens de training. Daardoor besteedt het model extra aandacht aan kleine, vage of ongebruikelijke structuren die anders over het hoofd zouden worden gezien, wat de recall verbetert zonder de kaart te overspoelen met valse alarmen.
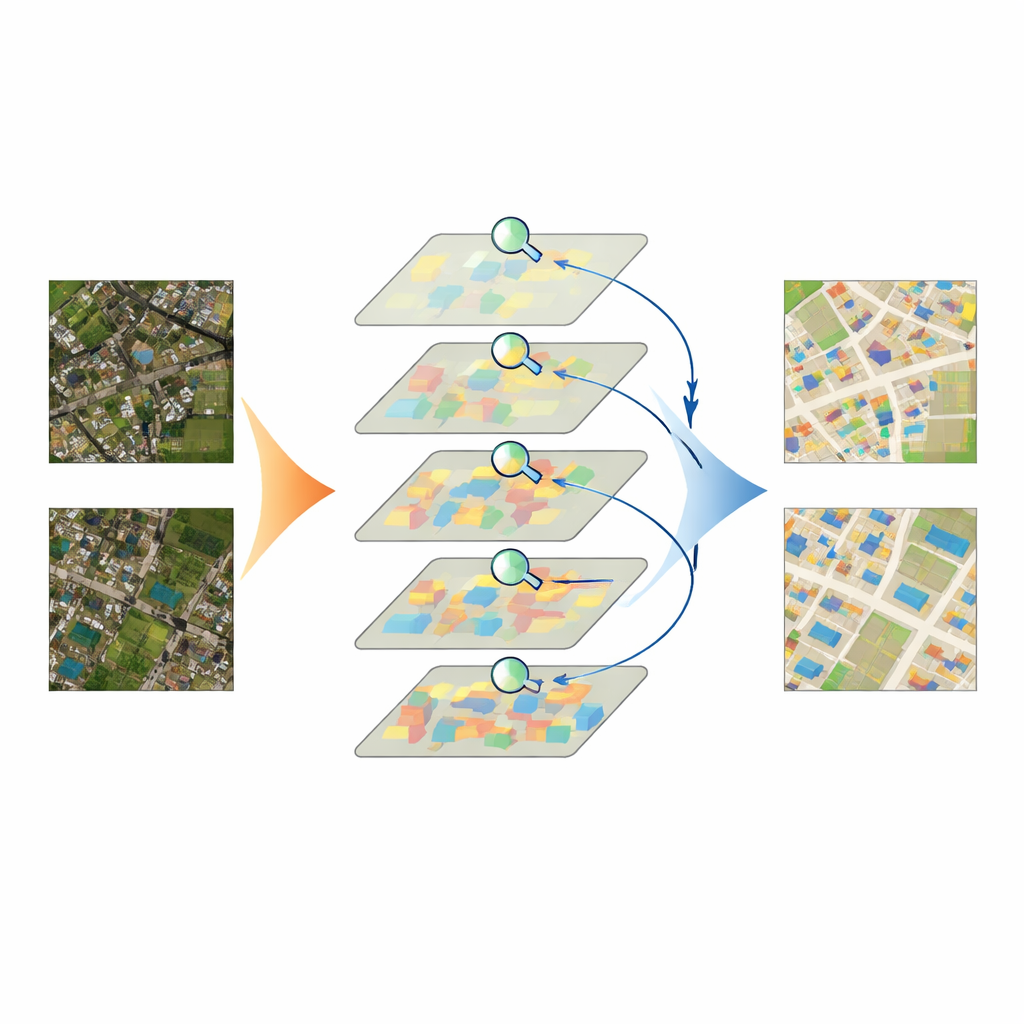
Het model op de proef stellen
Het team testte IASUNet op drie bekende gebouwdatasets uit Duitsland, Nieuw-Zeeland en de Verenigde Staten, en op een zorgvuldig samengestelde collectie Chinese satellietbeelden die ze zelf voorbereidden en kwaliteitscontroleerden. Over deze benchmarks heen presteerde IASUNet consequent op gelijke hoogte met of beter dan toonaangevende benaderingen, inclusief sterke convolutionele netwerken en andere Transformer-gebaseerde modellen. Op de uiterst gedetailleerde Potsdam-dataset bereikte het bijna perfecte overlap tussen voorspelde en werkelijke gebouwgebieden, terwijl het nog steeds praktisch snel draaide op moderne grafische hardware. Zelfs in meer onregelmatige landschappen, waar gebouwen verspreid, deels verborgen of dicht op elkaar staan, tekende IASUNet schonere contouren, ving het meer kleine doelen en voorkwam het veel van de weglatingen en grensfouten die bij concurrerende methoden optreden.
Van pixels naar betere steden
Concreet laat de studie zien dat we computers nu kunnen leren stadsgezichten vanuit de ruimte met ongekende helderheid te lezen. Door de aandacht van het model zorgvuldig te richten op de juiste delen van een afbeelding en zeldzame maar cruciale gebouwpixels bewust zwaarder te wegen, zet IASUNet ruwe satellietbeelden om in nauwkeurige, actuele gebouwkaarten met geringe extra rekenkosten. Dergelijke kaarten kunnen worden gebruikt voor stedelijke planning, energie- en hitte-eilandstudies, grondgebruiksregulering en snelle schadebeoordeling na rampen. Hoewel het werk technisch van aard is, is de conclusie simpel: slimmere AI kan beslissers een scherper, betrouwbaarder beeld van de gebouwde omgeving geven en zo helpen steden op een veiligere en duurzamere manier te laten groeien.
Bronvermelding: Zhang, H., Ma, Y., Wang, G. et al. IASUNet: building extraction based on impoved attention Swin-UperNet. Sci Rep 16, 7969 (2026). https://doi.org/10.1038/s41598-026-36270-2
Trefwoorden: remote sensing, gebouwextractie, semantische segmentatie, transformer-netwerken, stedelijke kartografie