Clear Sky Science · nl
Onzekerheid en inconsistentie van effecten van niet-farmaceutische COVID-19-maatregelen bij meerdere concurrerende statistische modellen
Waarom deze studie nú van belang is
De COVID-19-pandemie veranderde het dagelijks leven door schoolsluitingen, avondklokken, mondkapjesverplichtingen en vele andere regels. Regeringen stelden dat deze niet-farmaceutische interventies, of NPI’s, noodzakelijk waren om het virus te vertragen. Maar hoe sterk was het bewijs dat elke maatregel daadwerkelijk werkte, en hoe zeker waren wetenschappers over hun schattingen? Deze studie bekijkt de officiële Duitse analyse van COVID-19-beleid opnieuw en laat zien dat veel van de veronderstelde precisie over wat hielp en in welke mate een illusie was.
Opnieuw kijken naar Duitsland’s pandemiestrategie
Het Duitse ministerie van volksgezondheid gaf opdracht tot een omvangrijke analyse, de zogenaamde StopptCOVID-studie, om te schatten hoe verschillende interventies de verspreiding van het virus in elk deelstaat beïnvloedden. Het oorspronkelijke werk gebruikte een statistisch model dat een tijdsvariabele reproductiegetal, R(t) – hoeveel nieuwe infecties een geval gemiddeld veroorzaakt – koppelde aan meer dan 50 beleids- en contextvariabelen, waaronder vaccinatie en seizoen. Het model leverde keurige cijfers op over hoeveel het sluiten van openbare ruimtes, het beperken van het nachtleven of het verplichten van mondkapjes R(t) verminderde, en deze cijfers werden gerapporteerd met ogenschijnlijk smalle betrouwbaarheidsintervallen, wat duidde op behoorlijke zekerheid.
Wat de hertest wilde onderzoeken
Het nieuwe onderzoeksteam beoordeelde het Duitse rapport als iets dat een onafhankelijke audit nodig had. Ze behielden dezelfde basisinvoergegevens en epidemiologische aannames maar gebruikten negen verschillende, algemeen geaccepteerde statistische benaderingen om te testen hoe robuust de oorspronkelijke resultaten werkelijk waren. Hun aandacht was bewust beperkt: in plaats van te discussiëren welk biologisch epidemiemodel het beste was, vroegen ze hoe groot de veranderingen in antwoorden waren wanneer men statistische onzekerheden serieus nam, vooral voor tijdreeksen die veel regio’s over lange perioden volgen en tientallen overlappingen beleidsmaatregelen bevatten.
Verborgen statistische valkuilen in de originele studie
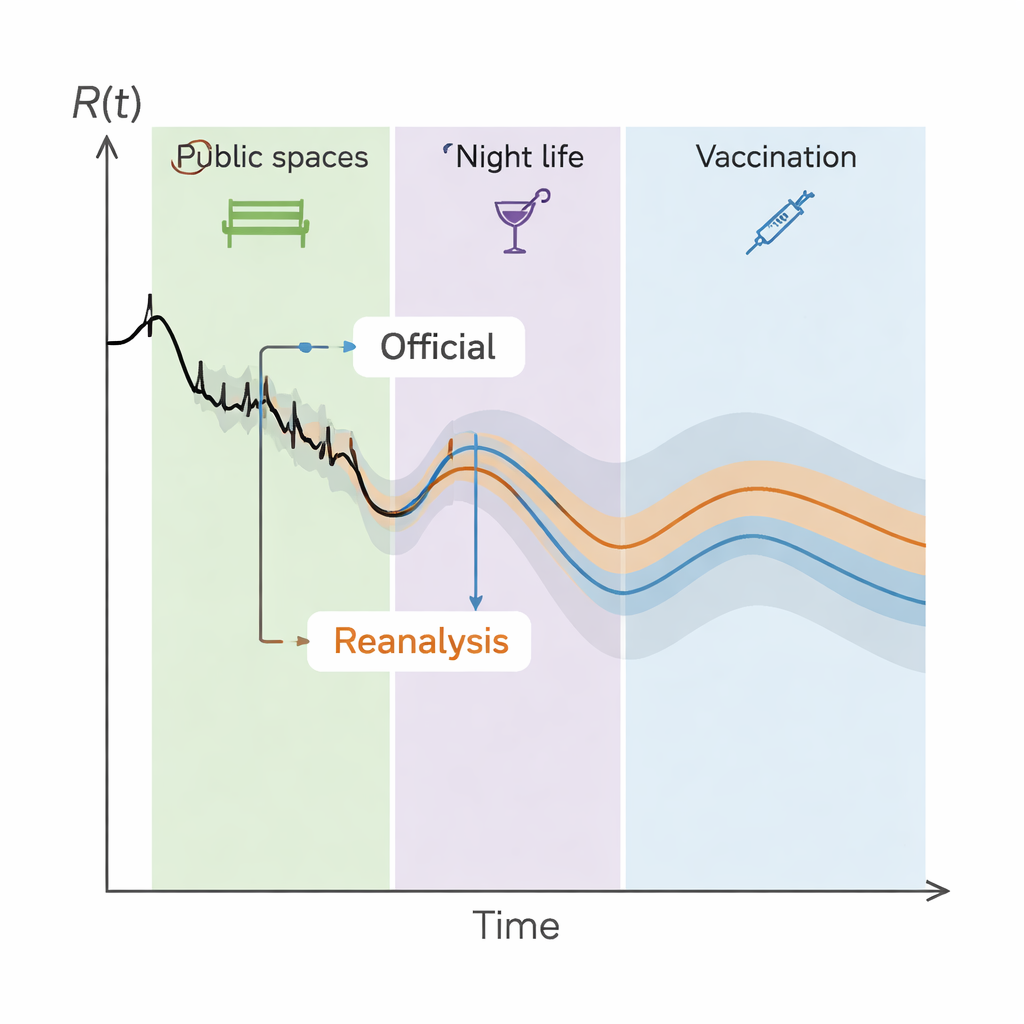
Twee problemen bleken cruciaal. Ten eerste ging het officiële model ervan uit dat het niet-verklaarde deel van de data – de residuen – van dag tot dag willekeurig was. In werkelijkheid, wanneer deze over de tijd voor elke deelstaat werden uitgezet, bewogen de residuen duidelijk in runs en vertoonden ze sterke autocorrelatie. Dat betekent dat de fouten van gisteren verbonden waren met die van vandaag, wat basisveronderstellingen van regressie schendt en de foutenmarges van standaardformules veel te optimistisch maakt. Ten tweede werden veel interventies vrijwel gelijktijdig door het hele land ingevoerd of aangescherpt. Dit veroorzaakte ernstige multicollineariteit: de activatiepatronen van verschillende NPI’s waren zo vergelijkbaar dat het model moeite had ze uit elkaar te houden. Onder deze omstandigheden kunnen schattingen voor individuele policyeffecten sterk variëren of zelfs van teken veranderen als het model wordt aangepast, wat opnieuw elk idee van precisie ondermijnt.
Wat houdbaar is, en wat niet
Onder de reeks concurrerende modellen vonden de onderzoekers dat de officiële betrouwbaarheidsintervallen veel breder hadden moeten zijn. Wanneer autocorrelatie en collineariteit strikter worden aangepakt, kan de meeste NPI’s niet met vertrouwen worden gekoppeld aan veranderingen in R(t). Dat betekent niet dat de maatregelen geen effect hadden; het betekent dat de beschikbare gegevens en methoden ze niet betrouwbaar kunnen onderscheiden. Sommige associaties zijn robuuster: vaccinatie springt eruit als duidelijk verminderend voor transmissie, en er is sterk, consistent bewijs dat COVID-19 een seizoenspatroon volgde. Beperkingen van openbare ruimten, nachtleven en bepaalde dienstensectoren, evenals de strengste regels in kinderopvang, komen ook naar voren als kandidaten voor reële effecten, maar zelfs daar is de precieze grootte van het voordeel zeer onzeker en mogelijk deels verward met vroege, brede maatregelen zoals algemene fysieke afstandsregels.
Lessen voor toekomstige beslissingen tijdens pandemieën
Voor niet‑specialisten is de kernboodschap dat nette tabellen die beleid rangschikken naar effectiviteit misleidend kunnen zijn wanneer ze gebaseerd zijn op complexe, rumoerige data. De auteurs betogen dat Duitsland’s aanpak – en veel van de wereldwijde tijdreeksliteratuur over COVID-19‑beleid – de onzekerheid heeft onderschat en daardoor heeft overschat hoe precies we individuele interventies kunnen beoordelen. Ze pleiten ervoor dat toekomstige pandemieplannen evaluatie in het ontwerp van maatregelen ingebakken moeten hebben: voldoende observatieperiodes toestaan, gegevens van hogere kwaliteit verzamelen, moderne tijdreeksmethoden gebruiken en invloedrijke modellen aan onafhankelijke verificatie onderwerpen. Zonder zulke zorg riskeren overheden ingrijpende beleidsmaatregelen te nemen of te verdedigen op een fragiele statistische basis, en kan het publiek meer vertrouwen in die cijfers krijgen dan gerechtvaardigd is.
Bronvermelding: Müller, B., Padberg, I., Lorke, M. et al. Uncertainty and inconsistency of COVID-19 non-pharmaceutical intervention effects with multiple competitive statistical models. Sci Rep 16, 5767 (2026). https://doi.org/10.1038/s41598-026-36265-z
Trefwoorden: COVID-19-maatregelen, evaluatie van pandemiebeleid, statistische onzekerheid, Duitsland, niet-farmaceutische maatregelen