Clear Sky Science · nl
Een hybride leerframework dat chaotische Niche alpha-evolutie integreert voor voorspelling van academische prestaties van leerlingen
Waarom vroege voorspelling van cijfers ertoe doet
Scholen beschikken steeds meer over een schat aan informatie over hun leerlingen—van aanwezigheidsgegevens en huiswerkcijfers tot enquêteantwoorden over thuissituatie en studiegewoonten. Dit artikel onderzoekt hoe je die ruwe data kunt omzetten in vroege waarschuwingen over wie waarschijnlijk moeite zal hebben of zal uitblinken in een vak. De auteurs presenteren een nieuw computerframework dat eindcijfers voor middelbare scholieren nauwkeuriger voorspelt, wat de deur opent naar eerder en meer op maat gemaakt steunaanbod in plaats van noodoplossingen op het laatste moment.
Van rapportcijfers naar rijke datasporen
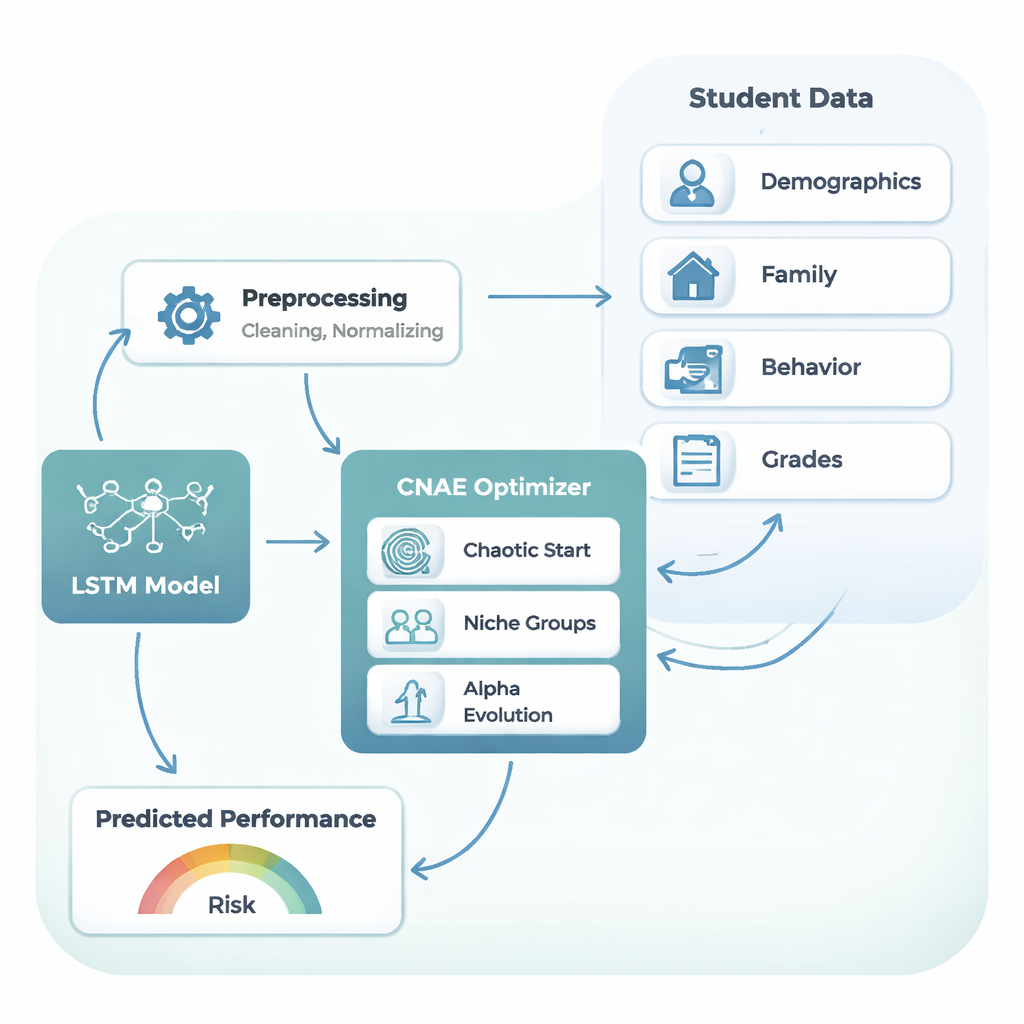
Moderne klaslokalen genereren veel meer dan een paar examencijfers. De dataset die in deze studie is gebruikt bevat 480 leerlingen en 32 verschillende gegevenspunten per leerling: leeftijd, gezinssituatie, reistijd, internettoegang, bestede studietijd, absenties en drie afzonderlijke cursuscijfers gedurende het schooljaar. Samen schetsen deze details een leertraject—hoe inzet, omstandigheden en eerdere resultaten zich opstapelen tot een eindcijfer. Deze rijkdom maakt voorspellen echter ook moeilijker: de gegevens zijn lawaaierig, ongelijkmatig en sterk verschillend van leerling tot leerling.
Een slimmere manier om leren in de tijd te lezen
Om deze leertrajecten te volgen, gebruiken de auteurs een type neuraal netwerk dat Long Short-Term Memory (LSTM) heet. In plaats van elk gegeven als een losstaand feit te behandelen, is een LSTM ontworpen om nuttige signalen uit eerdere delen van een reeks te onthouden—net zoals een docent die zich een leerling’s gestage vooruitgang of geleidelijke terugtrekking herinnert in plaats van alleen naar de laatste toets te kijken. In deze studie neemt de LSTM de mix van achtergrondfactoren, gedrag en eerdere cijfers in en geeft een voorspelling van het eindexamencijfer op een schaal van 0–20. LSTMs zijn echter kieskeurig: hun prestatie hangt sterk af van ontwerpskeuzes zoals het aantal lagen, het aantal eenheden per laag, de leersnelheid, de mate van regularisatie en hoeveel leerlinggegevens tegelijk worden gebruikt tijdens training.
Laten evolueren om het beste model te vinden
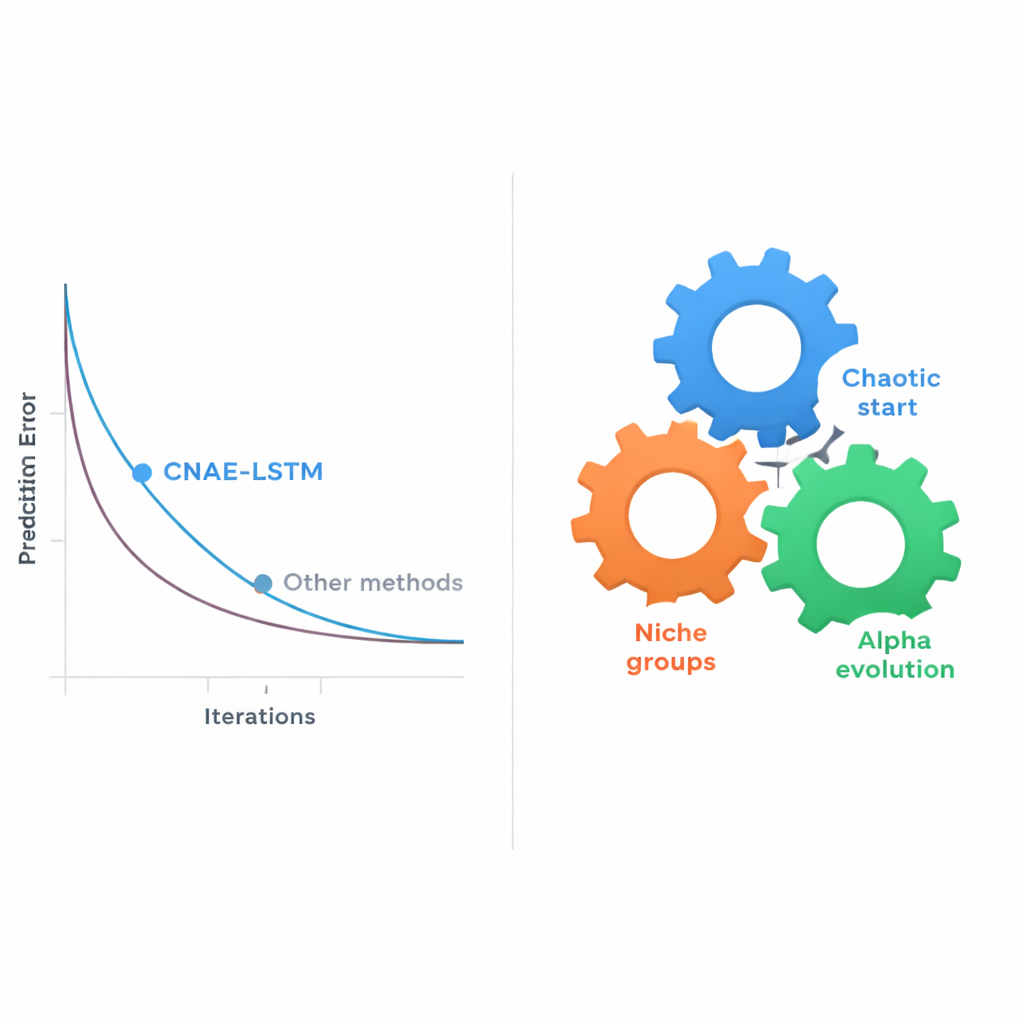
Het handmatig kiezen van die ontwerpinstellingen—of zelfs via eenvoudige trial‑and‑error‑roosters—wordt snel onpraktisch naarmate de combinaties exploderen. De kern van dit artikel is een nieuwe automatische zoekstrategie genaamd Chaotic Niche Alpha Evolution (CNAE), die de auteurs combineren met de LSTM en zo het CNAE‑LSTM-framework vormen. CNAE begint met het genereren van een grote variëteit aan kandidaat‑LSTM‑ontwerpen met behulp van een wiskundig proces geïnspireerd op chaos, waardoor de initiële opties ruim verspreid over de zoekruimte liggen. Vervolgens groepeert het vergelijkbare kandidaten in “niches”, waarbij het slechts het sterkste voorbeeld uit elke cluster behoudt en deze licht muteert om nabijgelegen mogelijkheden te verkennen. Ten slotte duwt een “alpha evolution”-stap de zoekrichting naar de meest veelbelovende regio’s terwijl deze geleidelijk verschuift van brede verkenning naar verfijning. Elke kandidaat‑LSTM wordt beoordeeld op hoe goed hij cijfers voorspelt op een apart gehouden validatieset, en de beste ontwerpen overleven om de volgende generatie te vormen.
Wat de experimenten laten zien
De onderzoekers testten hun benadering op de echte middelbare‑schooldataset en vergeleken CNAE‑LSTM met een reeks alternatieven: een support vector machine (een klassiek machine‑learning‑methode), twee deep‑learningmodellen (een convolutioneel netwerk en een Transformer), een standaard hand‑afgestelde LSTM en meerdere LSTMs waarvan de instellingen waren gekozen door bekende evolutionaire zoekmethoden of door grid‑ en randomsearch. De prestatie werd gemeten aan de hand van hoe dichtbij de voorspelde cijfers bij de werkelijke kwamen en hoeveel van de variatie in scores het model kon verklaren. CNAE‑LSTM kwam in alle maatstaven als beste uit de bus: het had de laagste gemiddelde voorspellingsfout en het grootste vermogen om verschillen tussen leerlingen te verklaren, met een foutvermindering van meer dan 10 procent vergeleken met de sterkste bestaande evolutionaire referentie. Herhalingen van de experimenten (30 runs) toonden aan dat CNAE‑LSTM niet alleen accurater was, maar ook stabieler—de resultaten varieerden minder tussen runs.
Waarom dit belangrijk is voor leerlingen en scholen
Voor een algemeen publiek is de kernboodschap helder: door een evolutionaire zoekprocedure het voorspellende model te laten ontwerpen, kunnen scholen betrouwbaardere voorspellingen krijgen over hoe leerlingen een cursus zullen afsluiten, lang voordat het eindexamen plaatsvindt. Het CNAE‑LSTM‑framework zet rommelige, real‑world educatieve data om in een helderder beeld van wie op schema ligt en wie mogelijk extra hulp nodig heeft, en doet dat efficiënt genoeg qua rekenmiddelen om praktisch inzetbaar te zijn. Hoewel de huidige studie zich richt op één middelbare‑schooldataset, kan dezelfde aanpak worden aangepast aan andere vakken en schoolniveaus. Gecombineerd met doordachte, humane interventies kunnen dergelijke voorspellingsinstrumenten onderwijsprofessionals helpen verschuiven van reageren op falen naar het voorkomen ervan.
Bronvermelding: Chen, H., Zhou, Y. & Cao, Q. A hybrid learning framework integrating chaotic Niche alpha evolution for student academic performance prediction. Sci Rep 16, 5302 (2026). https://doi.org/10.1038/s41598-026-36263-1
Trefwoorden: voorspelling van leerlingprestaties, educatieve data-analyse, LSTM, evolutionaire optimalisatie, vroegtijdige waarschuwingssystemen