Clear Sky Science · nl
Dialectale substitutie als een adversariële methode om de robuustheid van Arabische NLP te evalueren
Waarom alledaags Arabisch slimme computers in de war brengt
Veel apps lezen tegenwoordig Arabische tekst om sentiment te bepalen, nieuws te sorteren of vragen te beantwoorden. Toch leren deze systemen meestal van Modern Standaard Arabisch (MSA), terwijl mensen in het dagelijks leven voortdurend regionale dialecten gebruiken. Dit artikel toont aan hoe het vervangen van slechts één woord door Egyptisch of Golf-Arabisch geavanceerde taalmodellen kan misleiden, wat zorgwekkend is voor wie afhankelijk is van Arabische AI in klantenservice, mediamonitoring of online veiligheid.
Een taal, veel stemmen
Arabisch is geen eenduidige, uniforme spreekvorm. MSA wordt gebruikt op school, in het nieuws en in officiële teksten, maar alledaagse gesprekken leunen op dialecten zoals het Egyptisch en het Golf-Arabisch. Deze varianten verschillen in woordenschat, woordvormen en zelfs zinsbouw. Zo heeft een eenvoudig woord als “nu” heel verschillende vormen per regio. Voor menselijke lezers zijn deze variaties vanzelfsprekend en makkelijk te begrijpen. Voor computermodellen die vrijwel uitsluitend op MSA getraind zijn, kunnen dialectwoorden echter onbekend lijken, waardoor een duidelijke zin raadselachtig wordt.
Dialekten als stresstest voor AI
Om te onderzoeken hoe fragiel Arabische taalmodellen werkelijk zijn, ontwerpt de auteur een eenvoudige test in twee stappen. Eerst wordt een model herhaaldelijk bevraagd om het ene woord in een zin te vinden dat het meest bijdraagt aan zijn beslissing—vaak een sterk bijvoeglijk naamwoord, een cruciaal werkwoord of een onderwerp-anker. Ten tweede wordt dat ene woord vervangen door een equivalent uit het Egyptisch of Golf-Arabisch met behulp van een groot, zorgvuldig fijn-afgestemd "dialectizer"-model. De rest van de zin blijft ongewijzigd en voor menselijke lezers blijft de betekenis hetzelfde. Dat maakt de gewijzigde zin tot een realistisch adversariëel voorbeeld: een kleine, natuurlijk ogende aanpassing die het systeem misleidt zonder de beoogde boodschap te veranderen.
Hotelreviews en nieuwsverhalen op de proef
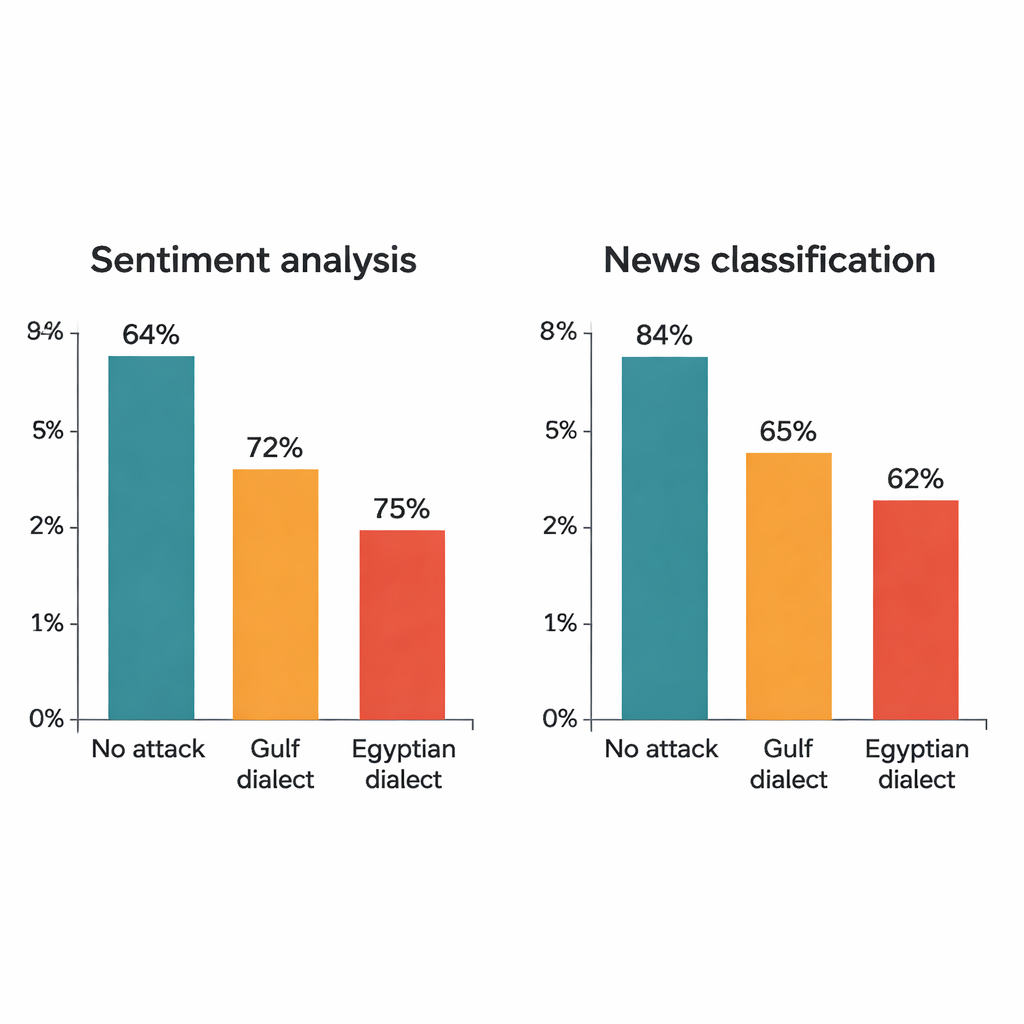
De studie valt vier bekende deep-learningmodellen aan: twee grote transformermodellen (AraBERT en CAMeLBERT) en twee kleinere netwerken (een convolutioneel model en een bidirectionele LSTM). Ze zijn getraind op twee belangrijke MSA-datasets: hotelreviews voor sentimentanalyse en nieuwsartikelen voor topicclassificatie. Uit elke testset haalt de auteur 1.280 voorbeelden en past de dialectale substitutieprocedure toe. Hoewel in elke zin maar één woord wordt veranderd, is het effect groot. Voor hotelreviews daalt de nauwkeurigheid van AraBERT van 94 procent op schone tekst naar ongeveer 72 procent met Golf-substituties en 65 procent met Egyptische. CAMeLBERT zakt nog verder, naar ongeveer 63 en 55 procent. Nieuwsclassificatoren lijden ook: het convolutionele model verliest grofweg 18 tot 22 procentpunten, en de LSTM laat vergelijkbare dalingen zien.
Wat er intern misgaat in de modellen
Een nadere blik laat zien dat de meest kwetsbare woorden overeenkomen met hoe mensen tekst werkelijk lezen. In hotelreviews is bijna de helft van de doelwoorden bijvoeglijke naamwoorden zoals "goed" of "verschrikkelijk", die duidelijke emotionele lading dragen. In nieuwsartikelen zijn de meeste geselecteerde woorden zelfstandige naamwoorden en namen die onderwerpen als politiek, sport of financiën signaleren. Wanneer die trigger-woorden in dialectvorm worden gezet, falen modellen die alleen op MSA zijn getraind vaak in het herkennen ervan. Transformermodellen blijken bijzonder fragiel: hun afhankelijkheid van subwoordfragmenten en hun focus op enkele sterk gewogen tokens maakt dat één dialectwoord genoeg kan zijn om een voorspelling omver te werpen. Kleinere modellen, die de aandacht meer gelijkmatig over een zin verspreiden, worden nog steeds misleid maar zijn iets robuuster.
Egyptisch versus Golf: niet alle dialecten zijn gelijk
De aanvallen laten ook zien dat Egyptisch Arabisch modellen vaker uit balans brengt dan Golf-Arabisch. Taalkundige studies ondersteunen dit beeld: Golfvarianten blijven vaak dichter bij MSA in woordenschat en structuur, terwijl het Egyptisch meer afwijkende vormen heeft opgenomen door historische ontwikkeling en contact met andere talen. Daardoor lijken Golf-substituties soms voldoende op het MSA-originelen om door het model te worden verwerkt, terwijl Egyptische substituties vaker buiten wat het model eerder heeft gezien vallen. Statistische tests bevestigen dat de waargenomen prestatieverliezen niet toevallig zijn—ze weerspiegelen systematische blinde vlekken in hoe huidige systemen omgaan met Arabische diglossie.
Wat dit betekent voor Arabische AI
Voor alledaagse gebruikers is de conclusie eenvoudig: de huidige Arabische AI laat zich gemakkelijk verwarren door gewone dialectwoorden, zelfs wanneer mensen de tekst volkomen helder vinden. Een enkel dialectisch woord in een hotelreview kan het oordeel van een model van positief naar negatief doen kantelen, of het onderwerp van een nieuwsverhaal verkeerd labelen. Voor onderzoekers en ontwikkelaars is de boodschap een oproep om "diglossie-bewuste" systemen te bouwen die zowel op MSA als op regionale dialecten trainen, en om realistische stresstests zoals dialectale substitutie te gebruiken bij het beoordelen van robuustheid. Tot die tijd loopt elke toepassing die ervan uitgaat dat "Arabisch gewoon MSA is" het risico op serieuze misverstanden in de praktijk.
Bronvermelding: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Trefwoorden: Arabische NLP, dialectale variatie, adversariële voorbeelden, sentimentanalyse, tekstclassificatie