Clear Sky Science · nl
Voorspellen van arbeidsongevallen in Turkije met multivariate ARMAX- en NLARX-modellen
Waarom het voorspellen van ongevallen op de werkplek ertoe doet
Elk jaar raken in Turkije honderdduizenden werknemers gewond en verliezen duizenden hun leven door arbeidsongevallen. Voor overheden, werkgevers en vakbonden is het van essentieel belang om te weten of het aantal ongevallen de komende jaren waarschijnlijk zal toenemen of afnemen, zodat zij inspecties, training en veiligheidsinvesteringen kunnen plannen. Deze studie stelt een eenvoudige maar belangrijke vraag: kunnen we met behulp van historische ongevallencijfers betrouwbaar toekomstige ongevallen voorspellen, en zo ja, welk type wiskundig model doet dat het beste?
Een nadere blik op het Turkse ongevalsoverzicht
De auteurs gebruiken officiële maandgegevens van de Turkse Sociale Zekerheidsinstelling, over de periode vanaf 2013—toen een nieuwe wet op arbeidshygiëne en -veiligheid van kracht werd—tot eind 2023. Om het beeld overzichtelijk te houden, verdelen zij de beroepsbevolking in vier groepen: verzekerde werknemers zonder ongeval, zij met lichte ongevallen, zij met zware ongevallen en degenen die bij een fataal ongeval betrokken waren. Het gezamenlijke bekijken van deze groepen laat zien dat ongevalspatronen niet geïsoleerd zijn. Veranderingen in lichte ongevallen kunnen zich bijvoorbeeld doorvertalen naar ernstige verwondingen en sterfgevallen, met name in risicovolle sectoren zoals de bouw, de mijnbouw en het vervoer. Het doel van het team is deze onderling verbonden trends vast te leggen met modellen die uit het verleden kunnen leren en die in de toekomst kunnen projecteren. 
Van eenvoudige krommen naar gekoppelde tijdlijnen
Veel eerdere studies vertrouwden op afzonderlijke een-regel-voorspellingen, waarbij elk type ongeval werd behandeld alsof het onafhankelijk evolueerde. De onderzoekers hanteren hier een multivariate tijdreeksbenadering die toestaat dat de vier groepen elkaar in de loop van de tijd beïnvloeden. Ze testen twee families van modellen. De eerste, technisch aangeduid als ARMAX, is een lineair model: het veronderstelt dat toekomstige waarden kunnen worden uitgedrukt als gewogen combinaties van verleden waarden en willekeurige ruis. De tweede, NLARX genoemd, voegt niet-lineaire termen toe zoals kwadraten en interactie-effecten, wat complexere reacties mogelijk maakt. Omdat geschikte maandgegevens over de bredere economie en sectoren ontbreken, richten beide modellen zich uitsluitend op de interne dynamiek van de ongevallencijfers zelf, in plaats van externe factoren zoals werkloosheid of productieniveaus toe te voegen.
Hoe de modellen zijn opgebouwd en beoordeeld
Middels gespecialiseerde systeemidentificatietools zetten de auteurs de ongevalsgegevens om in een gestructureerde dataset en splitsen deze in een trainingsgedeelte (de eerste 80 maanden) en een testgedeelte (de resterende 52 maanden). Vervolgens passen ze zowel lineaire als niet-lineaire modellen toe op de trainingsdata en laten elk model de testperiode voorspellen. De nauwkeurigheid wordt gemeten met een genormaliseerde mean squared error-score, die het verschil tussen voorspelde en waargenomen kurven over alle maanden en alle vier groepen vergelijkt. Door veel mogelijke modelstructuren te doorlopen en alleen parameters te behouden die statistisch zinvol zijn, verkleinen ze het risico op te ingewikkelde formules die alleen het verleden memoriseren. Deze zorgvuldige procedure maakt het mogelijk te vergelijken hoe goed de lineaire en niet-lineaire benaderingen generaliseren buiten de data waarop ze zijn getraind. 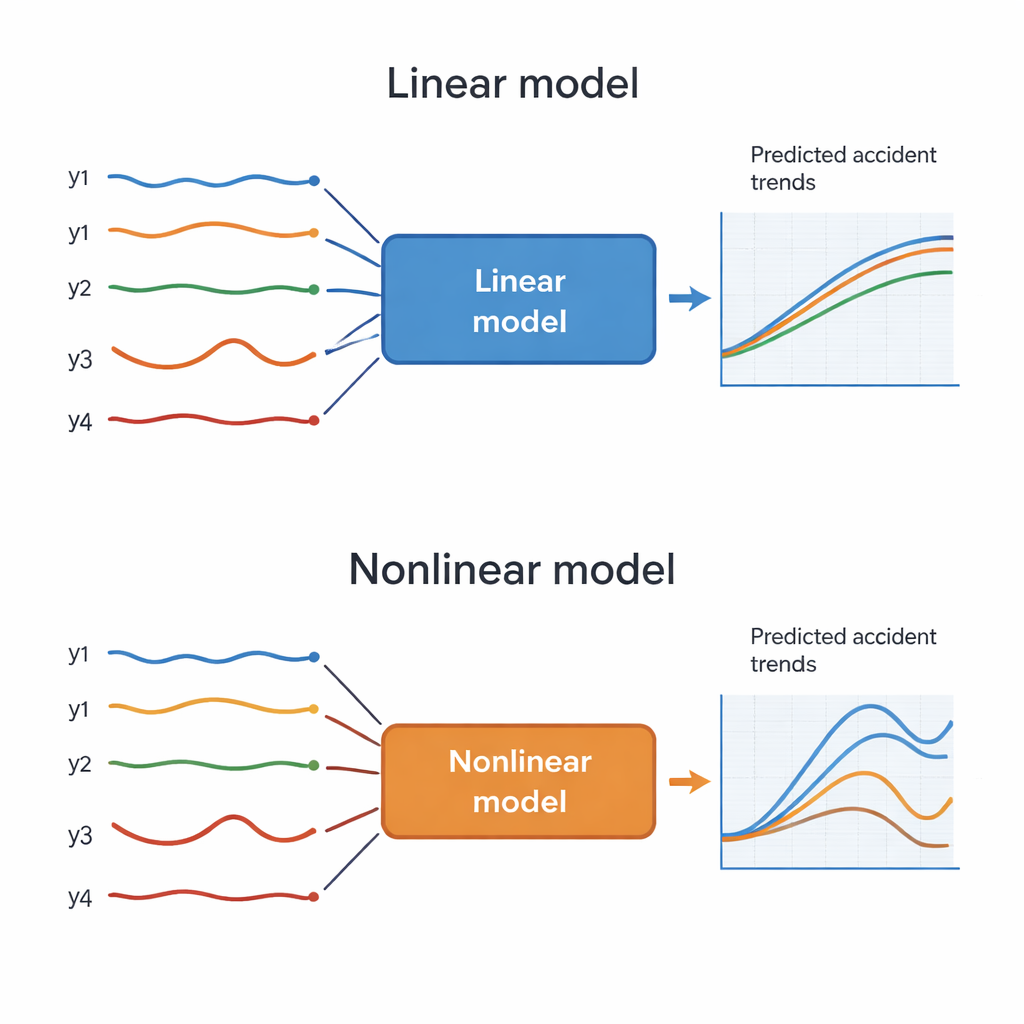
Wat de voorspellingen onthullen
De resultaten tonen een duidelijk patroon. Over het geheel genomen levert het lineaire ARMAX-model zeer nauwkeurige aanpassingen aan de historische data en lage voorspellingsfouten voor alle vier de populaties. Het presteert vooral goed voor verzekerde werknemers zonder ongevallen en voor lichte ongevallen, waarbij de voorspelde kurven dicht de werkelijke data volgen gedurende meer dan vier jaar testperiode. Het niet-lineaire NLARX-model blinkt uit voor de ongevalsvrije groep, waar het de lineaire aanpak licht overtreft, en het benadert het lineaire model voor lichte ongevallen en sterfgevallen. Echter, de voorspellingen voor zware ongevallen zijn merkbaar minder stabiel, met grotere afwijkingen naarmate de voorspellingshorizon toeneemt. Een nadere blik op de parameters van het lineaire model suggereert dat lichte ongevallen en de niet-ongevalspopulatie worden bepaald door veel bescheiden maar significante invloeden, terwijl zware ongevallen en sterfgevallen worden gedreven door enkele sterke, dominante effecten.
Wat dit betekent voor veiligheidsbeleid
Voor niet-specialisten is de kernboodschap dat relatief eenvoudige, goed ontworpen lineaire modellen al betrouwbare vroegsignalen kunnen geven over hoe verschillende categorieën arbeidsongevallen in Turkije zich waarschijnlijk zullen ontwikkelen. Omdat deze modellen expliciet bijhouden hoe lichte, zware en fatale ongevallen in de loop van de tijd samen bewegen, kunnen ze besluitvormers helpen opkomende problemen in de gevaarlijkere categorieën te herkennen en in te grijpen voordat het aantal doden oploopt. Niet-lineaire modellen voegen waarde toe in enkele stabiele groepen, maar zijn nog niet consequent beter waar het het meest telt: het voorspellen van zware verwondingen en dodelijke ongevallen. De studie suggereert dat autoriteiten met vertrouwen multivariate lineaire voorspellingen kunnen gebruiken om gerichte inspecties te sturen, strengere handhaving in risicovolle sectoren te bevorderen en de toewijzing van training en preventiemiddelen te verbeteren, terwijl toekomstig werk dat rijkere gegevens over sectoren en werkomstandigheden opneemt deze voorspellende instrumenten verder kan verfijnen.
Bronvermelding: Kaplanvural, S., Tosyalı, E. & Ekmekçi, İ. Forecasting occupational accidents in Turkey using multivariate ARMAX and NLARX models. Sci Rep 16, 5696 (2026). https://doi.org/10.1038/s41598-026-36210-0
Trefwoorden: arbeidsongevallen, tijdrijgvoorspelling, veiligheid op de werkvloer, Turkije, statistische modellering