Clear Sky Science · nl
Langafstand-contextmodellering voor detectie van softwarekwetsbaarheden met een op XLNet gebaseerde aanpak
Waarom verborgen softwarefouten ertoe doen
Het moderne leven draait op software, van internetbankieren en ziekenhuissystemen tot videospelers en chatapps. Zelfs kleine fouten in programmatuur kunnen echter deuren openen voor hackers, met risico’s op datadiefstal of uitval van diensten. Beveiligingsexperts zetten steeds vaker kunstmatige intelligentie in om miljoenen regels code op zulke zwakheden te scannen. Dit artikel onderzoekt een nieuwe AI-gebaseerde methode, XLNetVD genoemd, die is ontworpen om subtiele softwarekwetsbaarheden op te sporen door veel grotere stukken code te lezen dan veel bestaande hulpmiddelen aankunnen.
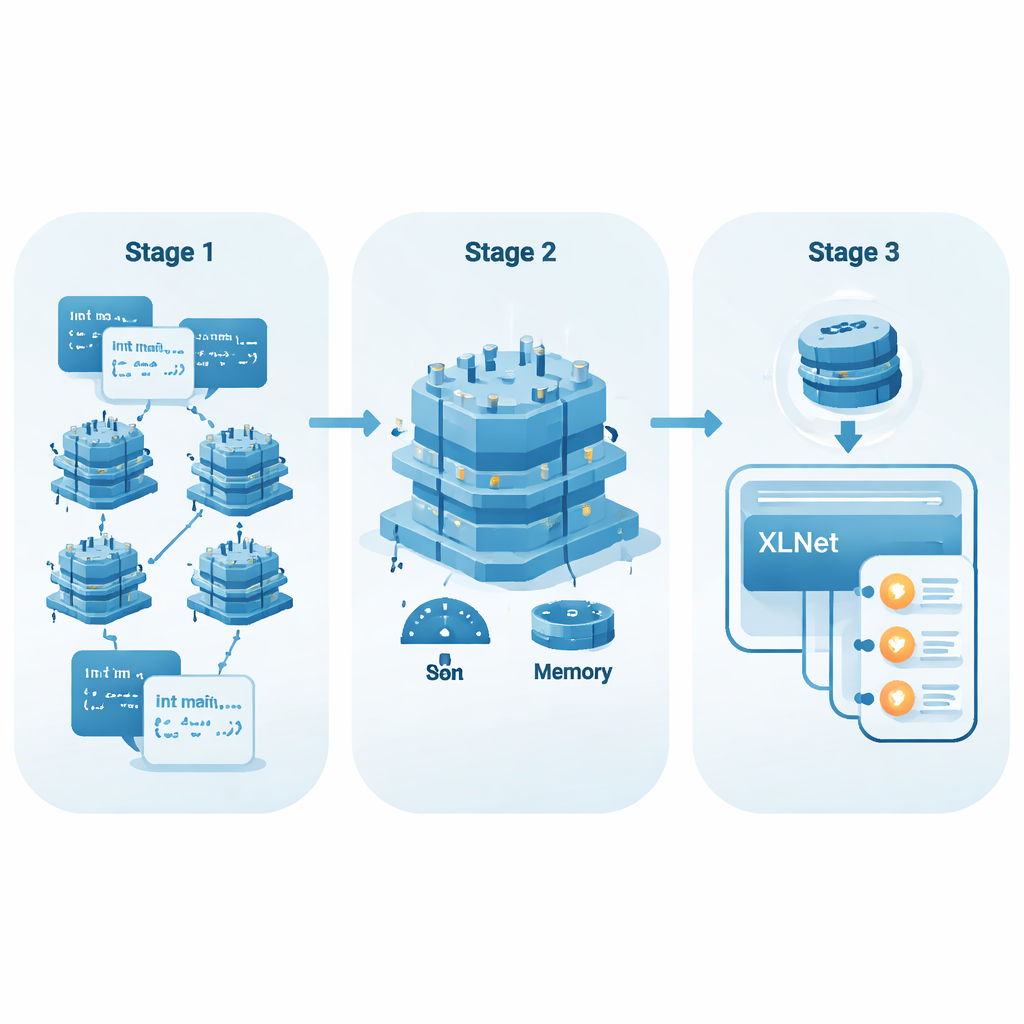
Van eenvoudige woordenlijsten naar code die context begrijpt
Vroege AI-methoden voor code-analyse behandelden elk token — zoals een variabelenaam of symbool — bijna als een gewoon woord met een vaste betekenis. Technieken als Word2Vec of GloVe leerden één vector per token, ongeacht waar het verscheen. Dat werkt redelijk voor natuurlijke taal, maar schiet tekort voor programma’s, waar dieselzelfde variabelenaam heel verschillend kan gedragen afhankelijk van waar en hoe hij wordt gebruikt. Nieuwere modellen, zogenaamde contextuele embeddingmodellen, bekijken in plaats daarvan de hele functie tegelijk en passen de representatie van elk token aan op basis van de omgeving. Daardoor kunnen ze patronen oppikken die te maken hebben met gegevensstroom, controleflow en onderlinge afhankelijkheden van variabelen — patronen die vaak het verschil bepalen tussen veilige en onveilige code.
De AI meer van het bestand laten lezen
Populaire codemodellen zoals CodeBERT en GraphCodeBERT gebruiken deze contextbewuste aanpak al, maar beperken doorgaans hun "zicht" tot ongeveer 512 tokens. Voor lange functies, of voor kwetsbaarheden die in ver uiteenliggende delen van de code worden gesuggereerd, kan dat venster te kort zijn. Belangrijke controles aan het begin van een functie kunnen afgesneden worden van risicovolle bewerkingen aan het einde. De auteurs bouwen in plaats daarvan voort op XLNet, een model dat is gebaseerd op Transformer-XL, dat informatie over segmenten heen kan onthouden en comfortabel langere reeksen kan verwerken (tot 768 tokens in hun experimenten). Daardoor is het beter geschikt om verre gebeurtenissen in code te koppelen — bijvoorbeeld begrijpen dat een waarde eerder gevalideerd is, of vaststellen dat dat nooit is gebeurd.
Krachtige modellen lichter en sneller maken
Grote AI-modellen vereisen vaak krachtige hardware, wat hun gebruik in alledaagse ontwikkelomgevingen beperkt. Om dit aan te pakken passen de auteurs een fine-tuningmethode toe genaamd Low-Rank Adaptation (LoRA). In plaats van alle vele parameters van XLNet te wijzigen, voegt LoRA kleine adapterlagen toe die veel goedkoper zijn om te trainen en op te slaan. Het team introduceert een eenvoudige score, EffScore, die afweegt hoeveel geheugen en tijd worden bespaard tegen eventuele daling in detectiekwaliteit. Over meerdere toonaangevende modellen heen blijkt XLNet met LoRA in de praktijk het meest efficiënt te zijn, met sterke nauwkeurigheid terwijl aanzienlijk minder middelen worden gebruikt.
Testen op echte en synthetische projecten
De onderzoekers evalueren XLNetVD op twee sterk verschillende datasets. De ene bestaat uit echte C-code van 12 open-sourceprojecten — zoals mediatheken en webservers — met een sterk scheve verhouding van ongeveer 1 kwetsbare functie op 65 niet-kwetsbare functies, wat de realiteit van grote softwarebases weerspiegelt. De andere is een gebalanceerde synthetische verzameling uit het SARD-project, waarbij elke functie is geconstrueerd om een bekend zwakte-type te representeren. XLNetVD evenaart of overtreft niet alleen eerdere deep-learning-systemen en klassieke statische analysetools in deze tests, het presteert ook goed in cross-projectscenario’s, waarin het fouten moet vinden in een project dat het niet eerder heeft gezien. Het voordeel is vooral groot voor lange functies, waar langere context cruciaal is, en over een reeks kwetsbaarheidscategorieën, waaronder integer-overflows, verkeerd beheer van bronnen en onjuiste invoerverwerking.
Wat dit betekent voor alledaagse softwareveiligheid
Voor niet-specialisten is de kernboodschap dat slim, contextbewust AI-code kan lezen en redeneren meer als een ervaren menselijke reviewer, maar op machinale schaal. Door het model meer van elke functie te laten zien en het efficiënt te tunen, biedt XLNetVD een praktische manier om te prioriteren welke delen van een enorme codebase nader menselijk onderzoek verdienen. Het vervangt geen handmatige beveiligingsaudits of formele methoden en kan niet garanderen dat software foutloos is. Het vergroot echter aanzienlijk de kans om gevaarlijke fouten vroegtijdig te vinden, zelfs in onbekende projecten, en is daarmee een veelbelovende bouwsteen voor betrouwbaardere en veiligere digitale infrastructuur.
Bronvermelding: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Trefwoorden: softwarekwetsbaarheden, codebeveiliging, deep learning, XLNet, LoRA-fine-tuning