Clear Sky Science · nl
Gewijzigd geprioriteerd DDPG-algoritme voor gezamenlijke beamforming- en RIS-faseoptimalisatie in MISO downlink-systemen
Slimme oppervlakken voor de volgende generatie draadloze netwerken
Naarmate onze telefoons, auto’s en sensoren steeds snellere en betrouwbaardere verbindingen vragen, worden de huidige draadloze netwerken tot het uiterste gedreven. Deze studie onderzoekt een nieuwe manier om toekomstige 6G-netwerken zowel groener als betrouwbaarder te maken door "slimme" reflecterende oppervlakken op gebouwen te combineren met een kunstmatige-intelligentie-techniek die zelfstandig leert hoe radiosignalen met minder vermogen te sturen.
Muren veranderen in behulpzame signaalspiegels
Toekomstige 6G-systemen moeten enorme aantallen apparaten bedienen met hoge datasnelheden, zeer hoge betrouwbaarheid en zeer lage vertraging. Het alleen met traditionele basisstations voldoen aan al die eisen zou veel extra hardware en energie vereisen. Herconfigureerbare intelligente oppervlakken (RIS) bieden een andere benadering: panelen bedekt met veel kleine, laagvermogende elementen die inkomende radiogolven in gecontroleerde richtingen kunnen reflecteren, als een programmeerbare spiegel. Door zorgvuldig de fasen van deze reflecties te kiezen, kan een RIS signalen rond obstakels leiden, zwakke verbindingen versterken en interferentie verminderen, zonder zelf actief vermogen uit te zenden. Dit geeft netwerkontwerpers een krachtig instrument om bereik uit te breiden en efficiëntie te verbeteren.
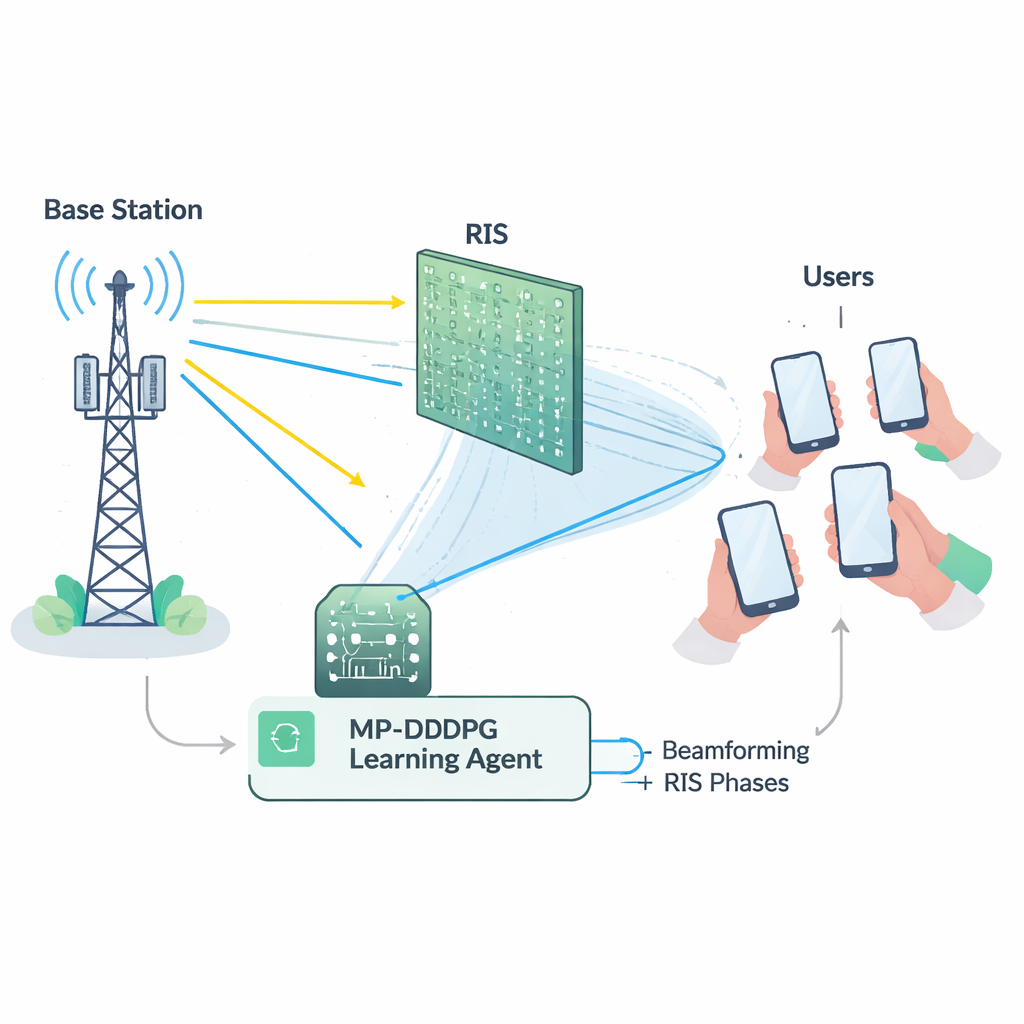
Een moeilijke evenwichtsoefening voor het netwerk
Goed gebruikmaken van een RIS is niet eenvoudig. Het basisstation moet beslissen hoe het zijn antennes richt (beamforming), terwijl de RIS voor elk van zijn vele reflecterende elementen de fase moet instellen. Deze keuzes hangen sterk met elkaar samen en moeten tegelijk aan meerdere beperkingen voldoen: het totale zendvermogen onder een maximum houden, elke gebruiker een minimale signaalkwaliteit garanderen en de fysieke limieten van de RIS-hardware respecteren. Wiskundig gezien is dit gezamenlijke afstemmingsprobleem sterk niet-lineair en "niet-convex", wat betekent dat conventionele optimalisatietools vaak traag, fragiel of vastlopend in suboptimale oplossingen zijn, vooral naarmate netwerken groter worden. Bovendien is het nauwkeurig meten van de gedetailleerde toestand van elke radiolink (de zogenaamde channel state information) in echte omgevingen kostbaar en foutgevoelig.
Een AI-agent leren hoe te sturen
Om deze hindernissen te overwinnen bouwen de auteurs een leeragent met behulp van diepe versterkingsleer, een tak van AI waarbij een agent via trial-and-error goede strategieën ontdekt in interactie met een omgeving. Hun methode, Modified Prioritized Deep Deterministic Policy Gradient (MP-DDPG), observeert de huidige netwerkstatus — vorige beamrichtingen, RIS-instellingen, ontvangen vermogen en signaalkwaliteit — en kiest vervolgens nieuwe beamforming- en RIS-fasewaarden. Na elke keuze ontvangt de agent een beloning die drie dingen tegelijk aanmoedigt: lager zendvermogen, voldoening aan kwaliteit-van-dienstdoelen voor gebruikers en naleving van de vermogenslimiet van het basisstation. Over vele gesimuleerde interacties leert de agent geleidelijk een regel die deze doelen in balans brengt zonder expliciet een kanaalformule te krijgen.
Sneller leren door te focussen op wat telt
De kerninnovatie zit in hoe het algoritme leert van eerdere ervaringen. Standaardmethoden slaan veel vroegere situaties op en nemen er tijdens training willekeurig monsters uit, wat inefficiënt en traag kan zijn. MP-DDPG kent in plaats daarvan aan elke opgeslagen ervaring een prioriteit toe die zowel afhangt van de beloning als van hoe verschillend de staat is ten opzichte van zijn dichtstbijzijnde buren. Ervaringen die zowel informatief als divers zijn worden vaker bemonsterd, terwijl redundante ervaringen worden genegeerd. Deze "gewijzigde geprioriteerde replay" maakt elke leerstap nuttiger, versnelt convergentie en helpt de agent slechte lokale oplossingen te vermijden. De auteurs analyseren ook de extra rekenlast die dit met zich meebrengt en tonen aan dat, hoewel de administratie complexer is dan in de basismethode, de snellere leerfase dit in de praktijk ruimschoots compenseert.
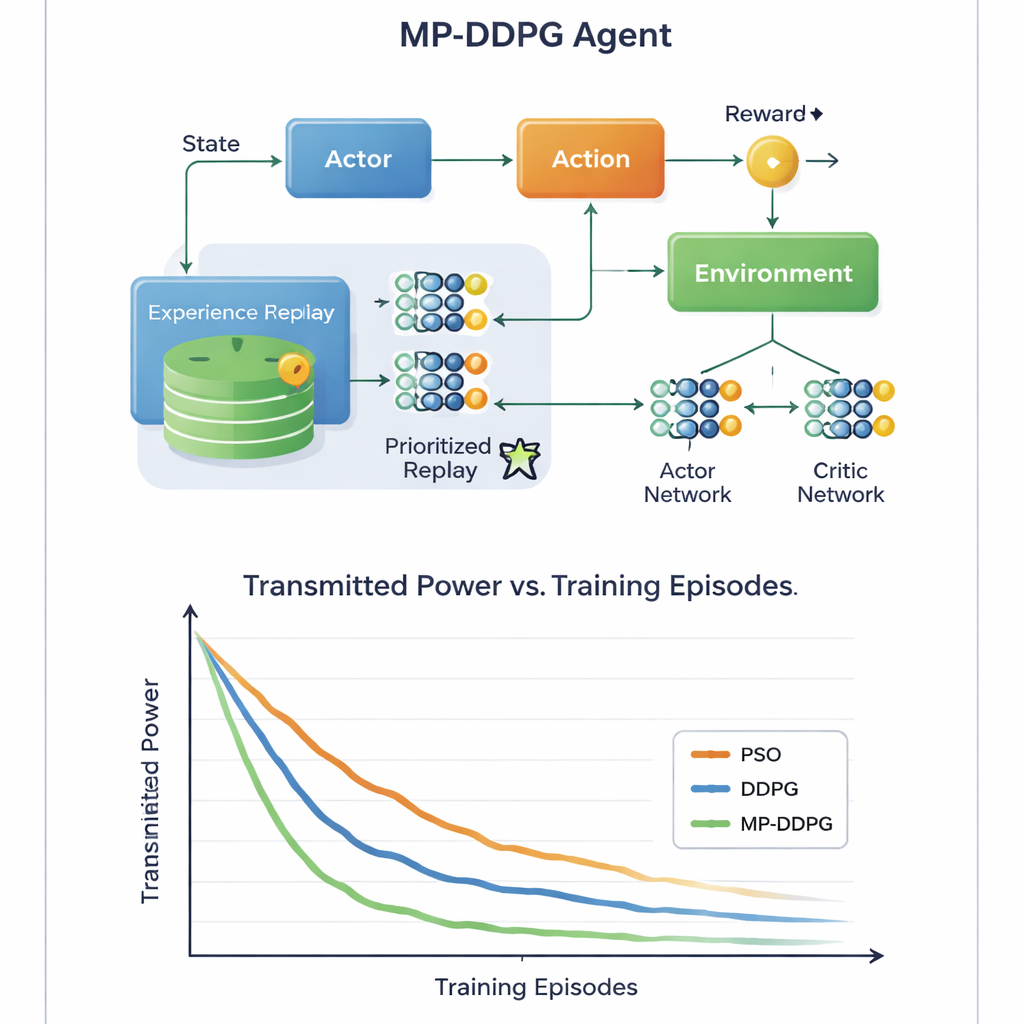
Groenere signalen met minder hardware
Door middel van gedetailleerde computersimulaties van een downlink-cellschema vergelijkt de studie MP-DDPG met twee alternatieven: een traditionele particle swarm optimization-methode en het oorspronkelijke DDPG-leeralgoritme. De nieuwe methode bereikt consequent lager zendvermogen in minder trainingsepisodes, en doet dit met minder RIS-elementen en minder basisstationantennes voor hetzelfde prestatieniveau. Simpel gezegd leert het netwerk meer voordeel te halen uit elke reflecterende tegel en elke antenne. Voor de niet-specialist is de kernboodschap dat door een AI-controller zowel de beamforming van het basisstation als de slimme oppervlakken op nabijgelegen muren slim te laten afstemmen, toekomstige 6G-netwerken sterke, betrouwbare signalen kunnen leveren met minder energie en hardware, wat bijdraagt aan een duurzamere, meer verbonden wereld.
Bronvermelding: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Trefwoorden: herconfigureerbaar intelligent oppervlak, 6G-draadloos, diepe versterkingsleer, beamforming-optimalisatie, energiezuinige netwerken