Clear Sky Science · nl
Voorspelling van voedselverslaving met machine learning bij universiteitsstudenten op basis van demografische, antropometrische en persoonlijkheidskenmerken
Waarom onze relatie met voedsel soms uit de hand kan voelen lopen
Veel mensen maken grapjes dat ze “verslaafd” zijn aan chocolade of fastfood, maar voor sommigen zijn trek en gebrek aan controle rond eten ernstig en verontrustend. Universiteitsstudenten zijn bijzonder kwetsbaar: ze combineren stress, nieuwe vrijheden en veranderende lichamen. Deze studie stelt een actueel vraagstuk: kunnen computerprogramma’s leren welke studenten een hoger risico op voedselverslaving lopen, op basis van eenvoudige informatie over hun achtergrond, lichaamsmetingen en persoonlijkheid? Als dat kan, zouden we problemen mogelijk eerder kunnen signaleren en ondersteuning op maat kunnen bieden voordat eetgewoonten uitgroeien tot langdurige gezondheidsproblemen.
Studenten vanuit meerdere invalshoeken bekeken
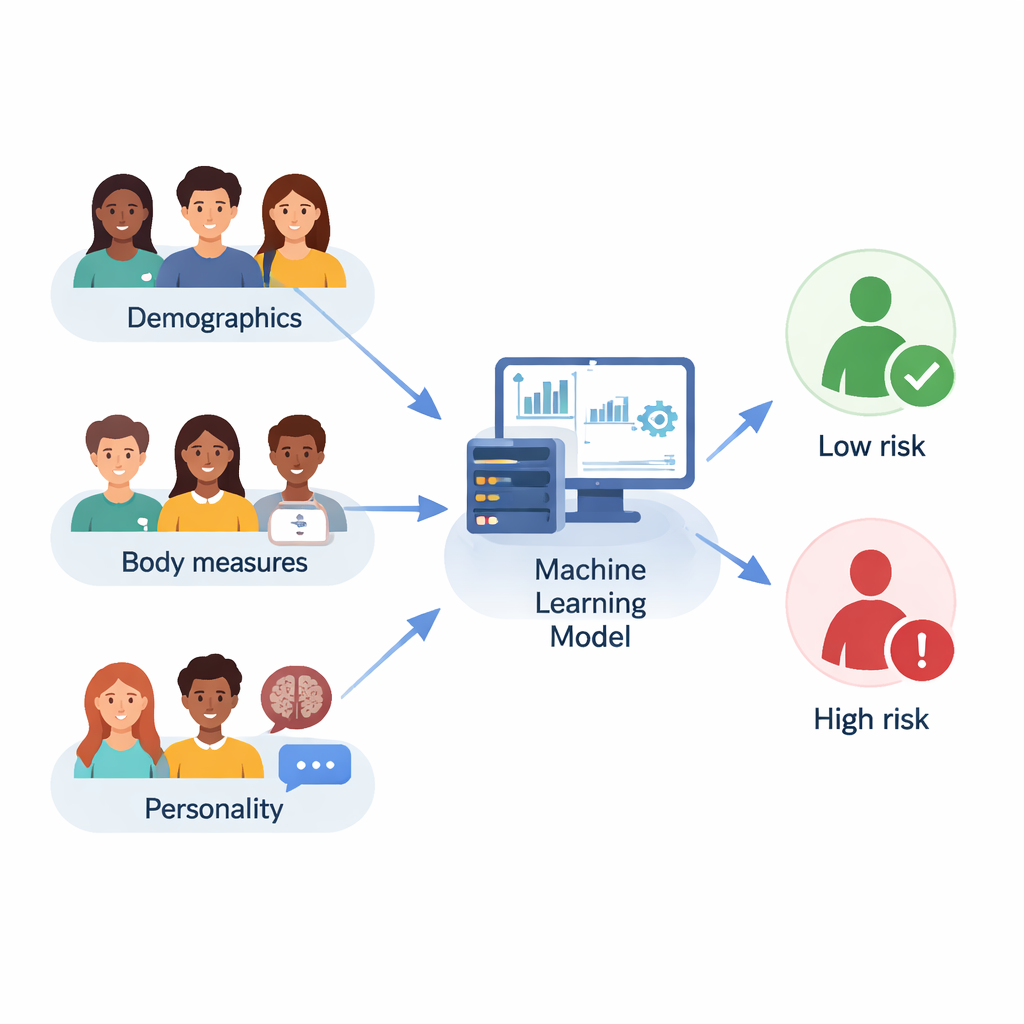
De onderzoekers werkten met 210 universiteitsstudenten in Ahvaz, Iran, in de leeftijd van 18 tot 35 jaar. Elke student gaf basisgegevens zoals leeftijd en opleidingsniveau, rapporteerde lengte en gewicht zodat de bodymassindex (BMI) kon worden berekend, en vulde een standaard persoonlijkheidsvragenlijst in. Ook werden ze gescreend met een korte versie van de Yale Food Addiction Scale, die classificeert of iemand verslavingsachtige patronen vertoont ten opzichte van sterk smakelijke voedingsmiddelen, zoals intense trek, mislukte pogingen om te minderen of eten ondanks negatieve consequenties. Slechts 30 studenten voldeden aan de criteria voor voedselverslaving, terwijl 180 dat niet deden, wat weerspiegelt dat zulke problemen een kleinere groep in de bevolking treffen.
Onevenwichtige data in balans brengen en slimme machines trainen
Omdat veel minder studenten als voedselverslaafd werden geklasseerd, was de dataset scheef verdeeld. Dit onevenwicht kan computermodellen ertoe verleiden vooral de meerderheidsgroep te voorspellen en de hoogrisicominderheid te negeren. Om dit tegen te gaan, gebruikte het team twee dataverwerkingsmethoden. Eerst pasten ze Tomek Links toe om verwarrende gevallen uit de meerderheidsgroep te verwijderen die te dicht bij minderheidsgevallen lagen. Vervolgens gebruikten ze SMOTE, dat realistische synthetische voorbeelden van de minderheidsgroep creëert om de aantallen gelijker te maken. Alleen de trainingsdata werden op deze manier aangepast; een aparte onaangeroerde testgroep werd apart gehouden om te controleren hoe goed de modellen presteerden op nieuwe, ongeziene studenten.
Verschillende algoritmen aan de tand voelen
De onderzoekers vertrouwden niet op één wiskundig recept. In plaats daarvan vergeleken ze tien verschillende machine learning-modellen, van eenvoudige methoden zoals logistieke regressie en k-nearest neighbors tot geavanceerdere 'ensemble'-methoden zoals Random Forest, Gradient Boosting, LightGBM en CatBoost. Ze probeerden ook twaalf strategieën voor feature-selectie om te bepalen welke vragen en metingen het meest informatief waren, en gebruikten cross-validatie en geautomatiseerde zoektochten om de instellingen van elk model te optimaliseren. De algemene prestatie werd beoordeeld met verschillende maten, waaronder nauwkeurigheid (hoe vaak het model gelijk had), F1-score (een balans tussen het detecteren van echte gevallen zonder te veel valse alarmen) en de oppervlakte onder de ROC-curve, die vastlegt hoe goed een model hogere risico’s scheidt van lagere risico’s.
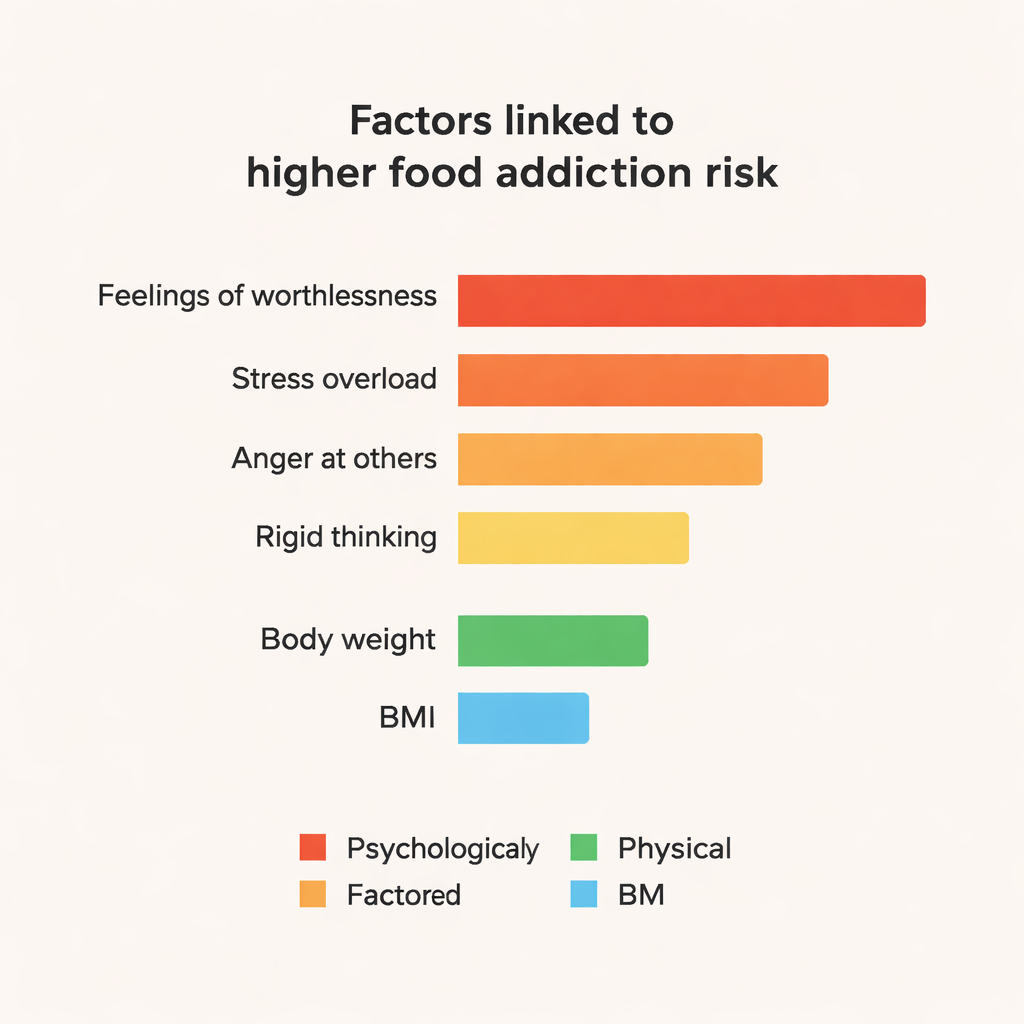
Wat de voorspellingen onder de motorkap aandrijft
Ensemblemodellen, in het bijzonder CatBoost en Random Forest, presteerden consequent beter dan eenvoudigere benaderingen en haalden ongeveer 84% nauwkeurigheid en F1-scores rond 0,84 in deze kleine dataset. Om verder te gaan dan 'black box'-voorspellingen gebruikte het team een hulpmiddel genaamd SHAP om te onderzoeken welke kenmerken het model ertoe brachten iemand als voedselverslaafd te labelen. De voornaamste invloeden waren psychologisch van aard: sterke uitspraken zoals 'Soms voel ik me volkomen waardeloos', het gevoel onder stress 'in elkaar te storten', frequente boosheid over hoe anderen hen behandelen, emotionele spanning en rigide, inflexibel denken. Lichaamsgewicht en BMI speelden ook een rol, maar waren minder centraal dan deze emotionele en persoonlijkheidsgerelateerde signalen. Kenmerken die samenhangen met een positief humeur en goede organisatie vertoonden een milde beschermende werking.
Wat dit betekent voor het dagelijks leven
Voor de gewone lezer is de kernboodschap dat voedselverslaving niet eenvoudigweg draait om wilskracht of het lekker vinden van snacks. In deze pilotgroep van studenten waren diepere emotionele problemen — laag zelfbeeld, moeite met stresshantering en gespannen relaties — nauw verweven met problematisch eetgedrag. Vroege versies van machine learning-instrumenten, gevoed met basisvragenlijsten en lichaamsmetingen, konden deze patronen met bemoedigende nauwkeurigheid detecteren. De auteurs benadrukken echter dat hun steekproef klein was, gebaseerd op zelfrapportage en afkomstig uit één universiteit, dus de resultaten zijn voorlopig. Met grotere en meer diverse studies zouden vergelijkbare modellen uiteindelijk naast standaard klinische beoordelingen kunnen worden gebruikt om jongeren te signaleren die baat zouden hebben bij ondersteuning bij het omgaan met zowel hun emoties als hun eetgewoonten.
Bronvermelding: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Trefwoorden: voedselverslaving, universiteitsstudenten, persoonlijkheidskenmerken, machine learning, emotioneel eten