Clear Sky Science · nl
Integratie van optimalisatie en machine learning voor het schatten van waterweerstand en verzadiging in shaley-zandreservoirs
Waarom dit belangrijk is voor energie en het milieu
Aardolie- en gasbedrijven vertrouwen op metingen die in een boorput worden gedaan om te bepalen waar koolwaterstoffen zich verbergen en of een veld de ontwikkeling waard is. In veel reservoirs, vooral die rijk aan klei en slib, zijn deze metingen berucht lastig te interpreteren, waardoor ingenieurs soms onderschatten hoeveel olie of gas er daadwerkelijk aanwezig is. Deze studie presenteert een nieuwe manier om betrouwbaardere informatie uit bestaande gegevens te halen door fysica-gebaseerde optimalisatie te combineren met moderne machine learning, wat mogelijk het herstel verbetert en tegelijk de behoefte aan kostbare kernmonsters vermindert.
Het probleem met modderige gesteenten
Veel van 's werelds koolwaterstofreservoirs zijn "shaley sands" – mengsels van zandkorrels, porievloeistoffen en geleidende kleimineralen. Deze klei vervormt elektrische metingen die worden gebruikt om te schatten welk deel van de porieruimte met water in plaats van met koolwaterstoffen is gevuld. Klassieke gereedschappen en grafieken, ontwikkeld voor schonere zandformaties, gaan uit van eenvoudige gesteentefabrieken en weinig klei. In shaley sands kloppen die aannames niet, waardoor de gesteenten er vaak natter uitzien dan ze zijn, en ingenieurs lagen kunnen afschrijven die eigenlijk aanzienlijke olie of gas bevatten.
Weinig metingen veranderen in een stevige ankerwaarde
De auteurs pakken een centrale grootheid aan die vormingswaterweerstand wordt genoemd en beschrijft hoe goed het water in de poriën elektriciteit geleidt. Als deze waarde niet klopt, raakt elke daaropvolgende schatting van waterverzadiging vertekend. In plaats van te vertrouwen op een paar laboratoriummetingen of subjectieve grafische methoden, formuleren ze het probleem als een optimalisatieopgave: vind de enkele waterweerstandwaarde die een fysica-gebaseerd shaley-sand-model het beste overeen laat komen met de weerstand die langs het wellboorgat is gemeten. Ze testen verschillende zoekalgoritmen en tonen aan dat eenvoudige, afgeleide-vrije methoden zoals Powell en Nelder–Mead de werkelijke waterweerstand met extreem kleine fout kunnen terugvinden wanneer vergeleken met kern- en watermonstergegevens van 11 putten in de Noorse Noordzee en de Westelijke Woestijn van Egypte.
Een "pseudo-core"-log maken voor machine learning
Zodra deze geoptimaliseerde waterweerstand is vastgesteld, gebruikt men hetzelfde fysieke model om een continue profiel van waterverzadiging langs elke put te berekenen. Dit profiel wordt behandeld als een hoogwaardige, fysica-geïnformeerde label — een soort "pseudo-core" — dat op elke diepte bestaat, niet slechts op een paar bemonsterde intervallen. De onderzoekers voeren vervolgens standaard well-logs, zoals gamma-ray, neutronporositeit, dichtheid en diepe weerstand, in een breed scala aan machine-learningmodellen. Deze omvatten boomgebaseerde ensembles (Random Forest, XGBoost, CatBoost), support-vector machines en verschillende neurale netwerkarchitecturen, inclusief een speciaal recurrent netwerk genaamd LSTM dat patronen kan herkennen die met diepte evolueren. Zorgvuldige preprocessing, uitschietercontrole en normalisatie helpen ervoor te zorgen dat de modellen echte geologische relaties leren in plaats van ruis.
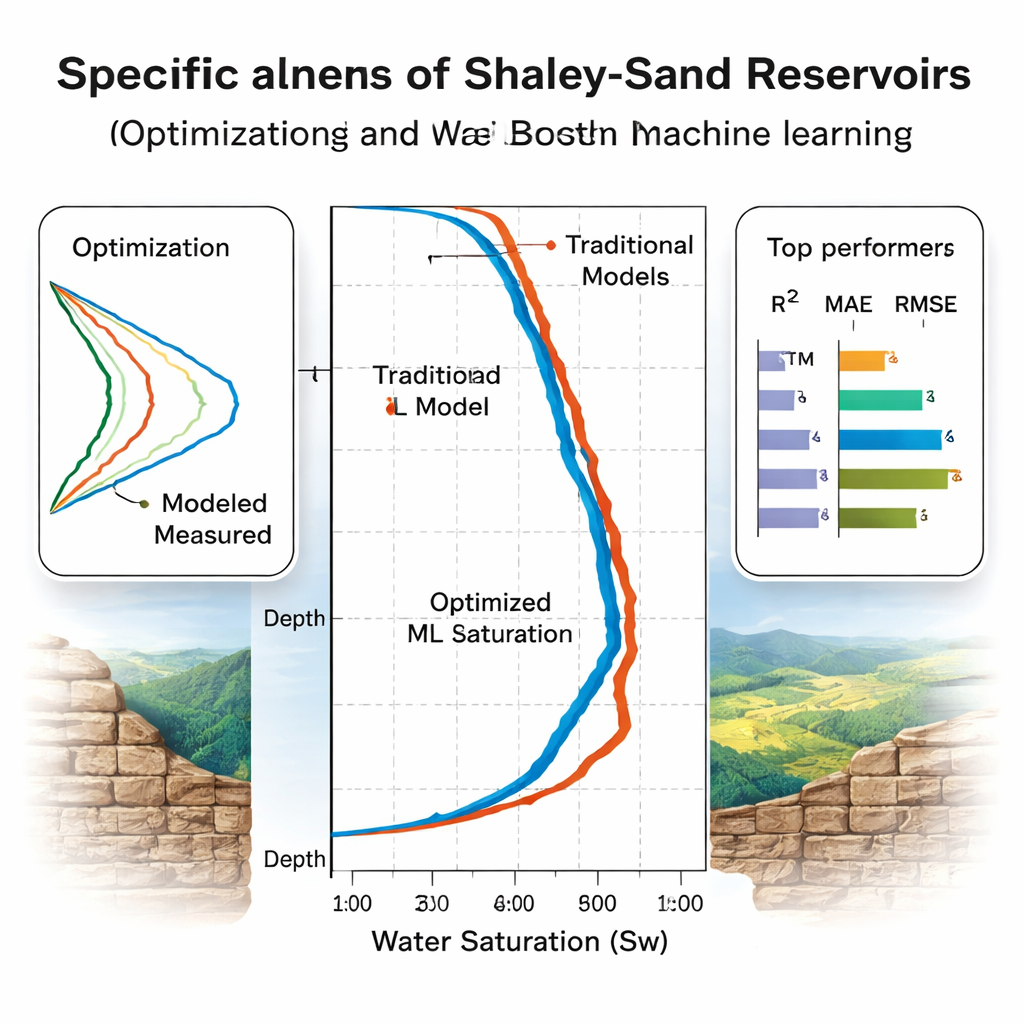
Welke modellen generaliseren echt?
Het team evalueert de modellen in twee fasen. Eerst gebruiken ze vijfvoudige cross-validatie op acht Noordzee-putten om ze te af te stemmen en te rangschikken, waarbij Random Forest op standaard nauwkeurigheidsscores als winnaar lijkt uit te komen. Daarna volgt de meer, enerverende test: drie "blinde" putten, waaronder twee uit een geologisch verschillend Egyptisch bekken die nooit in de training waren gebruikt. Hier struikelen sommige modellen. De prestaties van Random Forest dalen, wat wijst op overfitting aan het oorspronkelijke bekken. Daarentegen behouden gradient-boosted trees (CatBoost en XGBoost) en de LSTM en Bayesiaans-regulariseerde neurale netwerken een hoge nauwkeurigheid, waarbij ze meer dan 93–94% van de variatie in waterverzadiging verklaren met bescheiden fouten. Een feature-importance-analyse met SHAP, een moderne interpretatie-tool, bevestigt dat de modellen het meest leunen op fysisch zinvolle invoer zoals weerstand, porositeit en schalievolume.
Wat dit in gewone taal betekent
Voor niet-specialisten is de kernidee dat de auteurs eerst fysica gebruiken om het probleem op te schonen en te verankeren, en pas daarna machine learning toepassen. Door een optimalisatieroutine de best passende waterweerstand te laten vinden en dat vervolgens om te zetten in een dicht, fysica-respecterend trainingsbestand, vermijden ze het gebruikelijke knelpunt van schaarse en dure kerngegevens. Hun resultaten laten zien dat deze "optimalisatie-eerst, ML-tweede" aanpak betrouwbare schattingen kan opleveren van welk deel van een shaley-reservoir met water versus koolwaterstoffen is gevuld, zelfs in nieuwe bekken die niet voor training zijn gebruikt. In praktische termen kan dit operators helpen om betaalbare zones betrouwbaarder in kaart te brengen, onnodig koren te verminderen en de schattingen van aanwezige koolwaterstoffen te verbeteren — allemaal door slimmer gebruik te maken van gegevens die ze al verzamelen.
Bronvermelding: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Trefwoorden: shaley-zandreservoirs, waterverzadiging, vormingwaterweerstand, machine learning in petrofysica, reservoirkarakterisering