Clear Sky Science · nl
Aandachtsgestuurde spatio-temporele featurefusie voor robuuste anomaliedetectie in videobewaking
Waarom slimere camera's ertoe doen
Van drukke treinstations tot winkelcentra: het moderne leven is gevuld met beveiligingscamera's die stilletjes alles vastleggen wat gebeurt. Toch worden de meeste van deze beelden—als ze al bekeken worden—door vermoeide menselijke ogen gezien die gemakkelijk een cruciaal moment kunnen missen. Dit artikel onderzoekt een nieuw soort ‘slim’ surveillancesysteem dat automatisch ongebruikelijk of risicovol gedrag kan herkennen, zoals diefstal of vandalisme, in realtime door zowel te begrijpen wat in een scène verschijnt als hoe het zich in de tijd verandert.

Meer zien dan pixels
Een traditionele camerastroom is slechts een opeenvolging van afbeeldingen. Oudere computersystemen probeerden problemen te detecteren door elk frame afzonderlijk te bekijken en te zoeken naar vormen en randen die op mensen of objecten leken. De auteurs testen eerst een moderne versie van dit idee die een compact beeldherkenningsnetwerk combineert met klassieke randdetectors. Deze opzet werkt redelijk goed in netjes ingekaderde scènes, vooral bij het opmerken van duidelijke visuele signalen zoals iemand die een voorwerp pakt. Omdat het echter op afzonderlijke snapshots is gericht, heeft het moeite wanneer mensen elkaar blokkeren, wanneer menigten dicht worden, of wanneer dezelfde houding normaal of verdacht kan zijn afhankelijk van hoe die zich in de tijd ontvouwt.
Begrijpen van beweging en gedrag
Om het verhaal achter een handeling vast te leggen, en niet alleen het uiterlijk van één frame, evalueert de studie vervolgens een videogericht model dat korte clips analyseert in plaats van stilstaande beelden. Dit model leert hoe beweging vloeit over meerdere frames en kan beter plotselinge veranderingen identificeren zoals rennen, vechten of wegrukken. Het blijkt goed in het opvangen van veel abnormale gebeurtenissen, wat leidt tot hoge gevoeligheid. Toch lijdt het ook aan een klassiek probleem in de echte wereld: echt ongewone gebeurtenissen zijn zeldzaam vergeleken met alledaagse activiteit. Als gevolg kan het model instabiel worden, te veel valse alarmen geven en zorgvuldig vooraf gesneden videosegmenten vereisen die de rommelige, continue aard van echte bewakingsbeelden niet weerspiegelen.
Blenden van waar en wanneer
Voortbouwend op de sterke en zwakke punten van deze twee basislijnen, stellen de auteurs een nieuw hybride systeem voor, genoemd HybridModel-1, dat probeert zowel in ruimte als tijd tegelijk te ‘denken’. Het combineert een netwerk dat zeer goed is in het begrijpen welke objecten in elk frame aanwezig zijn met een snelle detector die die objecten in de scène lokaliseert. Een speciaal fusiemodule leert om de meest informatieve visuele details te benadrukken—zoals mensen en sleutelobjecten—terwijl achtergrondruis zoals muren, bomen of passerende auto’s wordt teruggeschroefd. Tegelijkertijd bestraft een nieuwe trainingsstrategie het systeem zachtjes wanneer de vertrouwensscore wild springt van het ene naar het andere frame, waardoor het wordt aangemoedigd naar vloeiender, consistentere beslissingen over een hele video toe te werken.
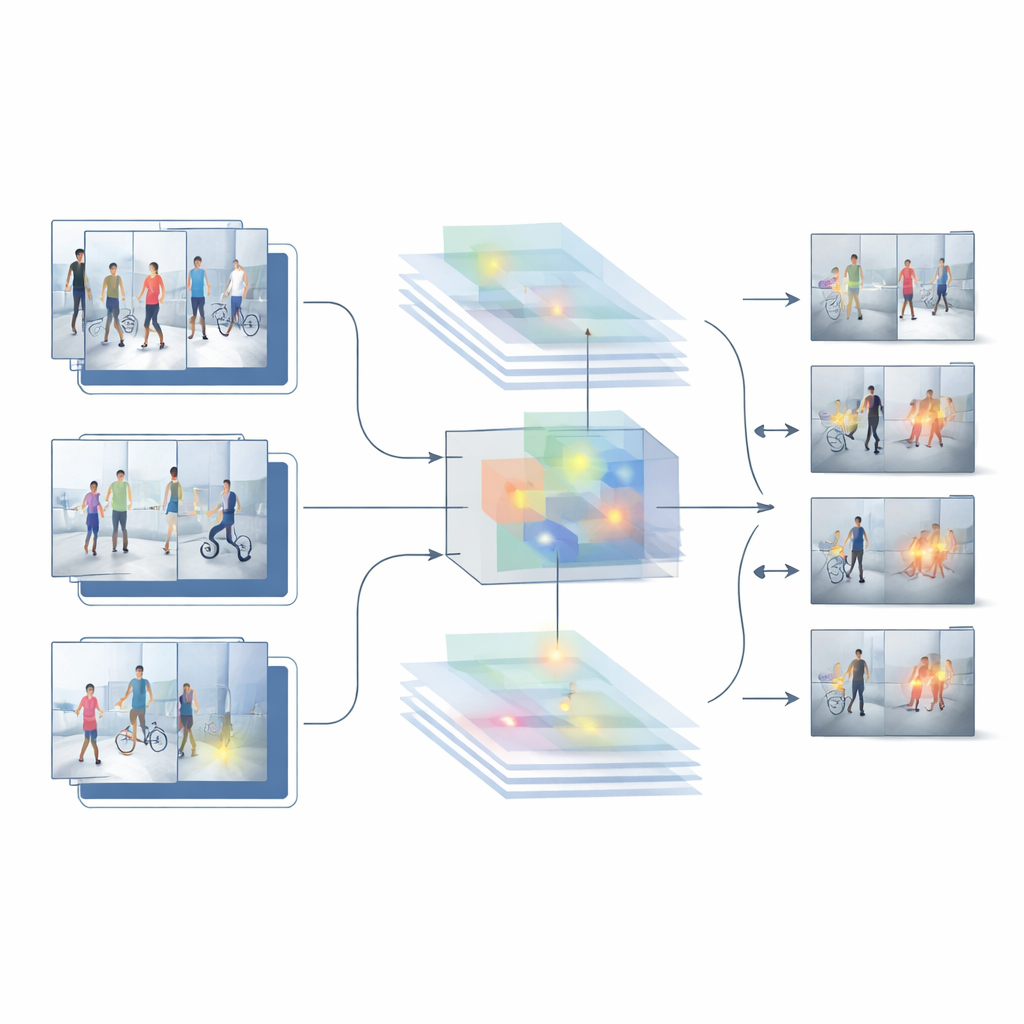
Het systeem op de proef stellen
Om te zien of dit ontwerp buiten het lab werkt, testen de onderzoekers het op verschillende uitdagende openbare datasets met echte bewakingsbeelden. Deze verzamelingen bevatten alles van binnendiefstallen tot buitenlooproutes op campussen, met wisselende cameraposities, verlichting, menigtes en soorten incidenten. Over deze benchmarks presteert het hybride model beter dan zowel de beeld‑alleen als de video‑alleen baselines. Het behaalt een hogere algehele nauwkeurigheid, geeft veel minder valse alarmen en behoudt sterke prestaties zelfs wanneer het wordt geëvalueerd op beelden waarop het niet getraind is. Gedetailleerde vergelijkingen en ablaties—waarbij delen van het systeem worden verwijderd of aangepast—tonen aan dat zowel de feature‑fusiemodule als de op vloeiendheid gerichte trainingsstap wezenlijk bijdragen aan deze verbeteringen.
Wat dit betekent voor de dagelijkse veiligheid
In eenvoudige bewoordingen toont dit werk aan dat surveillancesystemen betrouwbaarder worden wanneer ze leren aandacht te besteden aan de juiste delen van een scène en consistent te blijven in hun oordelen door de tijd heen. In plaats van elk frame als een geïsoleerd beeld te behandelen of uitsluitend te vertrouwen op ruwe beweging, brengt de voorgestelde benadering ‘wat’ en ‘wanneer’ samen in een enkel, zorgvuldig afgestemd kader. Hoewel uitdagingen blijven bij extreem donkere of zwaar geblokkeerde gezichten, wijzen de resultaten op een praktische weg naar cameranetten die stilletjes grote hoeveelheden video kunnen screenen, werkelijk verdachte gebeurtenissen naar voren kunnen brengen en de last van valse alarmen voor menselijke operatoren verminderen. Voor het publiek kan dat veiligere ruimtes betekenen die worden gemonitord door systemen die niet alleen kijken, maar echt begrijpen wat ze zien.
Bronvermelding: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Trefwoorden: videobewaking, anomaliedetectie, slimme camera's, misdaaddetectie, machine learning