Clear Sky Science · nl
Hybride deep learning-framework voor nauwkeurige classificatie van hoogdimensionale genoomgegevens
De databerg van het genoom begrijpelijk maken
Moderne DNA-technologieën kunnen tienduizenden genen in één experiment meten, wat eerder ziekteopsporing en preciezere behandelingen belooft. Toch is deze hoeveelheid data zo groot, luidruchtig en complex dat zelfs krachtige computermodellen vaak moeite hebben om duidelijke, betrouwbare patronen te vinden. Dit artikel introduceert een nieuw soort kunstmatig intelligentiesysteem dat speciaal is ontworpen om zulke overweldigende genomische gegevens aan te pakken, met als doel zowel nauwkeuriger voorspellingen te doen als te verklaren hoe die voorspellingen tot stand komen.
Waarom genomische data zo moeilijk te gebruiken zijn
Genomische studies genereren routinematig veel meer metingen dan er patiënten of monsters zijn. Veel van die metingen zijn irrelevant, overbodig of verstoord door technische ruis. Traditionele machine-learningmethoden vereisen ofwel dat menselijke experts handmatig bepalen welke genen relevant kunnen zijn, of ze proberen alles te gebruiken en lopen het risico op overfitting — dat wil zeggen goed presteren op trainingsdata maar falen bij nieuwe gevallen. Deep learning, dat gebieden als beeldherkenning heeft getransformeerd, kan automatisch patronen uit ruwe data leren. In de genomica gedraagt het zich echter vaak als een black box: het kan accurate antwoorden geven, maar biedt weinig inzicht in het waarom, wat de acceptatie in de geneeskunde beperkt waar transparantie essentieel is.
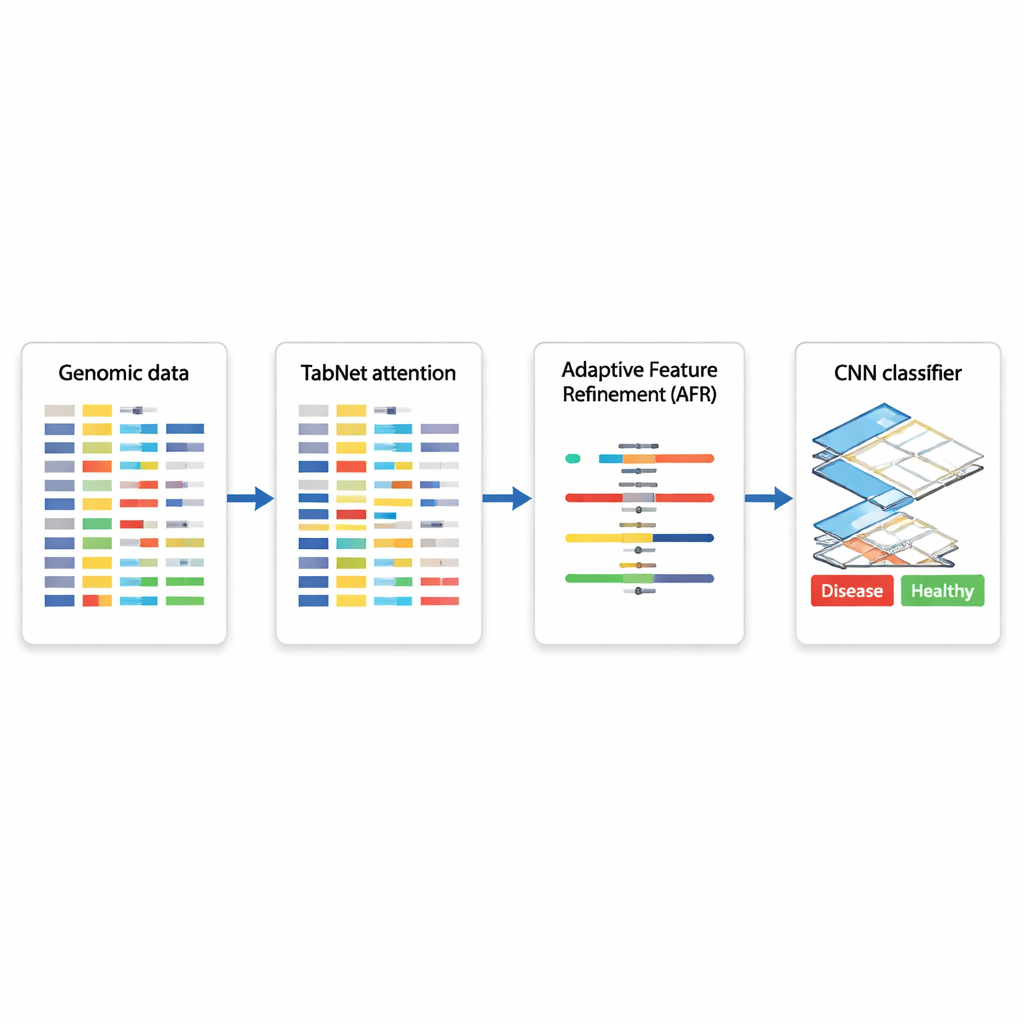
Een hybride AI-blauwdruk voor besluitvorming op genbasis
De auteurs stellen een hybride deep learning-architectuur voor die drie gespecialiseerde modules achter elkaar schakelt. Ten eerste fungeert een component genaamd TabNet als een schijnwerper: die scant alle beschikbare genomische metingen en leert welke kenmerken het meest informatief zijn voor een bepaalde taak — bijvoorbeeld het onderscheiden van kwaadaardig en goedaardig weefsel. In plaats van elk gen gelijk te behandelen, richt TabNet de aandacht op een spars subset die het meest relevant lijkt. Vervolgens neemt een Adaptive Feature Refinement (AFR)-laag deze geselecteerde signalen en herweegt ze, versterkt consistente, zinvolle patronen en dempt verder de ruis. Ten slotte onderzoekt een convolutioneel neuraal netwerk (CNN), veelgebruikt in beeldanalyse, hoe de verfijnde kenmerken lokaal met elkaar interageren, waarmee subtiele relaties tussen groepen genen worden vastgelegd die kunnen wijzen op een bepaald ziektetype of biologische toestand.
Het model op de proef stellen
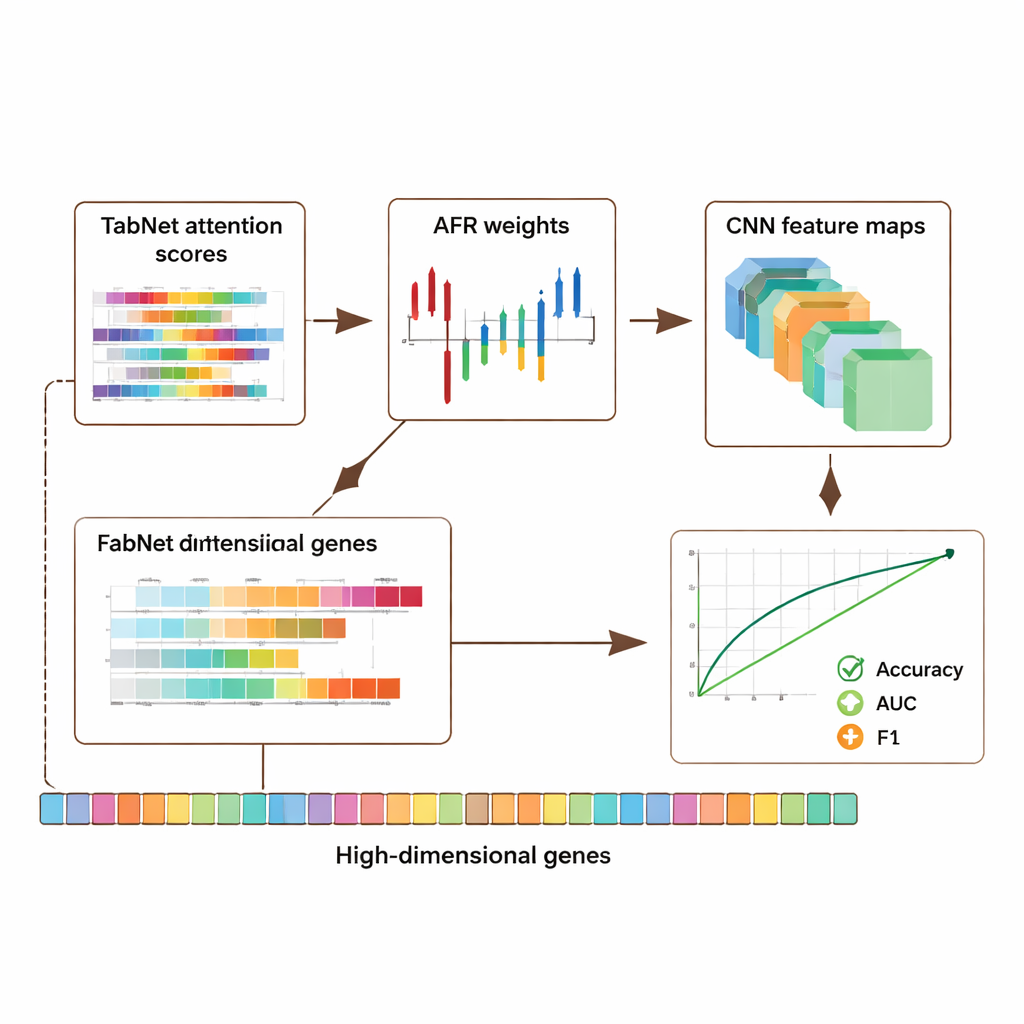
Het framework is geëvalueerd op drie grote openbare bronnen: een borstkanker-dataset van The Cancer Genome Atlas, een single-cell melanomadataset van de Gene Expression Omnibus en een epigenomica-dataset van het ENCODE-project. Gezamenlijk bevatten deze collecties duizenden monsters en tienduizenden kenmerken per monster, met gegevens over genactiviteit en chemische markers op DNA. Over alle datasets heen presteerde het hybride model beter dan verschillende state-of-the-art benaderingen en verbeterde het de nauwkeurigheid en belangrijke classificatiematen zoals de area under the receiver operating characteristic curve (AUC) en de F1-score met ongeveer 5–8 procentpunt. Belangrijk is dat deze winst niet ten koste ging van transparantie: het model produceert attentiekaarten van TabNet en activatiekaarten van de CNN die aangeven welke genen en regio’s het meest doorslaggevend waren bij elke voorspelling.
Balanceren van nauwkeurigheid, privacy en vertrouwen
Aangezien genomische data sterk persoonlijk zijn, onderzochten de auteurs ook hoe privacy te beschermen blijft terwijl nuttig signaal behouden wordt. Ze introduceerden een adaptief privacymecanisme dat meer ruis toevoegt aan zeer gevoelige kenmerken en minder aan andere, gecombineerd met maskering van geselecteerde invoerwaarden. Tests toonden aan dat het model zelfs bij het introduceren van matige ruis sterke nauwkeurigheid en discriminatie behield, waarbij de prestaties geleidelijk verslechterden naarmate de bescherming werd aangescherpt. Tegelijkertijd wezen de interpreteerbare attentie- en activatiepatronen vaak naar genen die al bekend zijn om hun rol in kanker en immuunregulatie, wat suggereert dat het systeem niet simpelweg data onthoudt maar biologisch betekenisvolle signalen opvangt. Een ablatied studie — waarbij delen van de architectuur systematisch werden verwijderd — bevestigde dat elke module, vooral de AFR-laag, een meetbare bijdrage leverde aan de prestaties.
Wat dit betekent voor de geneeskunde van de toekomst
In eenvoudige bewoordingen biedt dit werk een slimmere manier om enorme genomische spreadsheets te doorzoeken om patronen te vinden die met ziekte samenhangen, terwijl ook wordt getoond welke velden in de spreadsheet het belangrijkst waren. Door gerichte featureselectie, zorgvuldige verfijning en patroonherkenning te combineren, verbetert het hybride model de voorspellingsnauwkeurigheid, blijft het computationeel beheersbaar en levert het visuele aanwijzingen die clinici en biologen kunnen interpreteren. Hoewel meer tests nodig zijn op bredere en diversere patiëntengroepen, zouden dergelijke frameworks kunnen helpen bij het identificeren van nieuwe biomarkers, het verfijnen van ziektesubtypes en het ondersteunen van klinische beslissingshulpmiddelen in precisiegeneeskunde — waardoor AI-analyse van DNA een stap dichter bij praktisch gebruik komt.
Bronvermelding: Swain, M.K., Kamila, N.K., Jena, L. et al. Hybrid deep learning framework for accurate classification of high dimensional genomic data. Sci Rep 16, 5919 (2026). https://doi.org/10.1038/s41598-026-36128-7
Trefwoorden: genomische deep learning, ontdekking van kanker-biomarkers, interpreteerbare AI, precisiemedicatie, privacy-beschermende genomica