Clear Sky Science · nl
Integratie van random forest-gebaseerde regressie-kriging voor de analyse van ruimtelijke variabiliteit van neerslag in aride en semi-aride gebieden
Waarom het in kaart brengen van regen in droge gebieden ertoe doet
In landen waar water schaars is, kan het verschil tussen voedselzekerheid en crisis afhangen van precies te weten waar en wanneer het regent. Pakistan beslaat bergen, woestijnen en vruchtbare vlakten, en zijn neerslag is onder klimaatverandering onregelmatiger geworden. Toch zijn weerstations op de grond zeldzaam en ver uit elkaar gelegen. Deze studie stelt een praktische vraag: met beperkte gegevens, kan moderne machine learning gecombineerd met klassieke kaarttechnieken scherpere, betrouwbaardere neerslagkaarten maken om landbouw, overstromingsplanning en waterbeheer te ondersteunen?
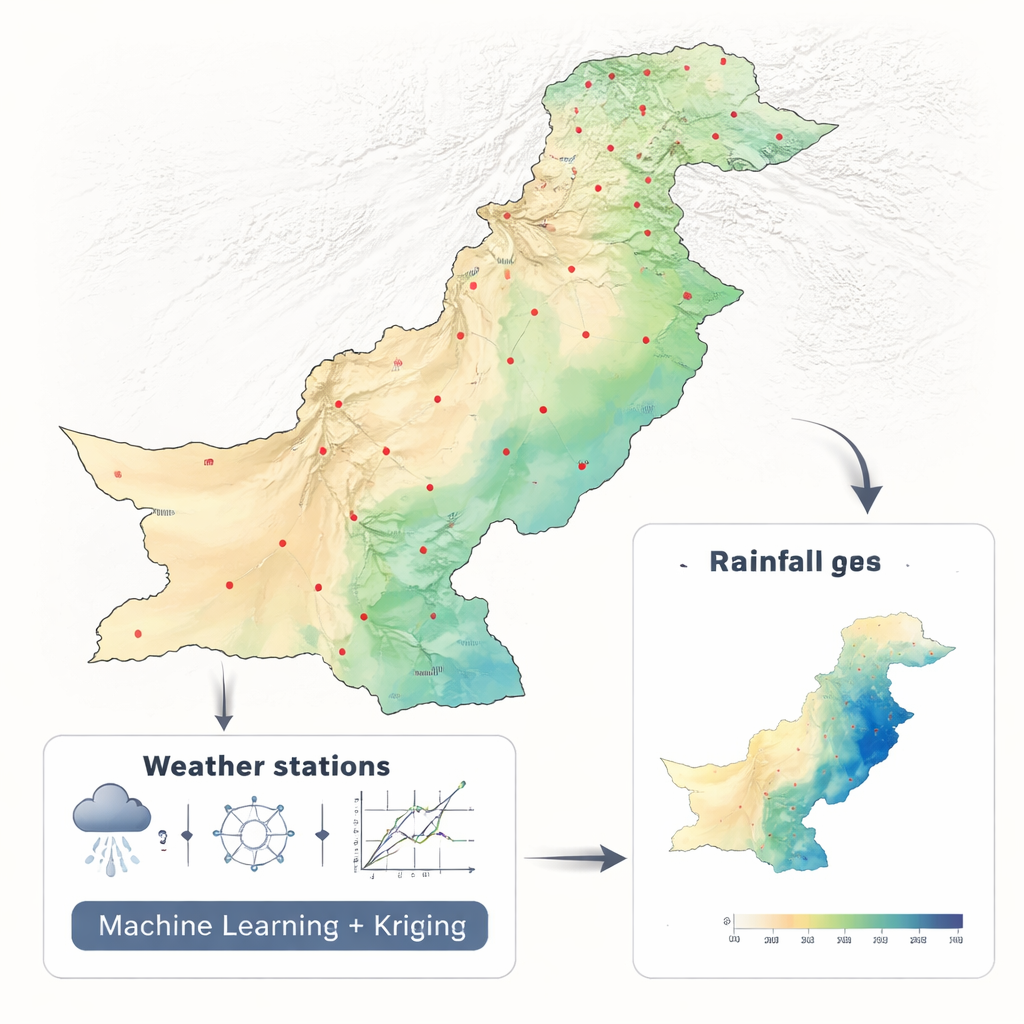
Verspreide regenmeters omzetten in volledige kaarten
De onderzoekers werkten met twee decennia maandelijkse neerslaggegevens (2001–2010 en 2011–2021) van 42 stations verspreid over Pakistan, gebruikmakend van een consistent klimaatdataset van NASA. In plaats van tientallen omgevingsvariabelen in een complex model te stoppen, gebruikten ze bewust alleen breedte- en lengtegraad. Dit uitgeklede ontwerp stelde hen in staat zich te concentreren op één kernprobleem: welke wiskundige benadering zet verspreide puntmetingen het beste om in een continue kaart. Ze vergeleken zes machine-learningmethoden—Random Forest, Support Vector Machine, K-Nearest Neighbors, Neuraal Netwerk, Elastic Net en Polynomiale Regressie—elke ingebed in een raamwerk dat regressie-kriging heet en veel gebruikt wordt in de geowetenschappen.
Groot-data-achtige leeralgoritmen mengen met ruimtelijke intuïtie
Regressie-kriging werkt in twee stappen. Eerst voorspelt een regressiemodel de neerslag op elke locatie uit de coördinaten, waarmee brede patronen worden vastgelegd zoals nattere bergen en drogere woestijnen. Ten tweede vult een ruimtelijke methode, kriging genoemd, de resterende lokaal patroongebonden verschillen tussen waarnemingen en voorspellingen in. Om die tweede stap betrouwbaar te maken, bestudeerde het team eerst hoe gelijk of verschillend neerslag was tussen paren stations op verschillende afstanden—een instrument dat een variogram heet. Ze vonden dat eenvoudige “circulaire” en “lineaire” wiskundige vormen het beste beschreven hoe de overeenkomst in neerslag met afstand afneemt over seizoenen en tussen de twee decennia, een aanwijzing voor zachte, regiobrede neersystemen in plaats van abrupte sprongen.
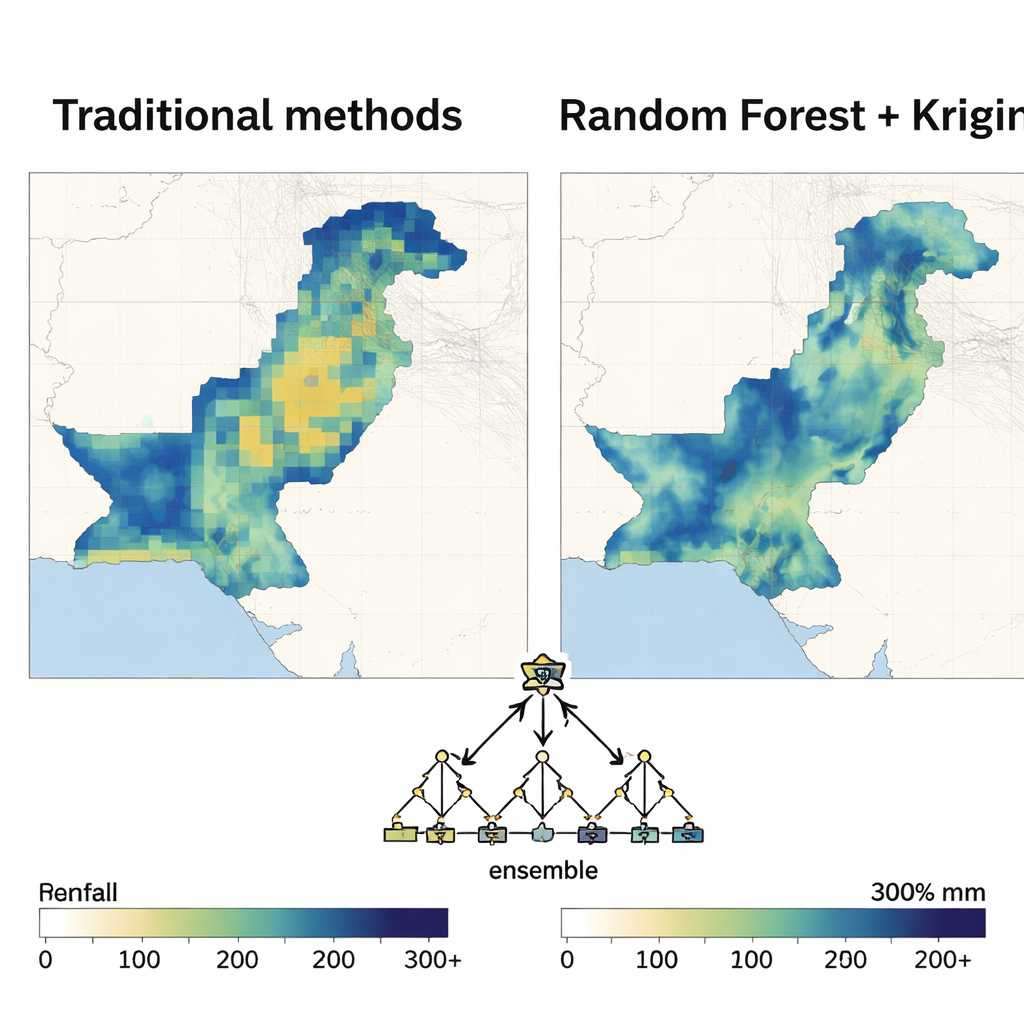
Random Forest blijkt koploper
Zodra de ruimtelijke structuur was vastgelegd, kreeg elke machine-learningmethode een beurt als regressiemotor binnen het hybride model. De auteurs beoordeelden de prestaties met gangbare maatstaven voor fout en hoeveel variatie in neerslag het model kon verklaren. In bijna alle maanden en beide decennia gaf de Random Forest–gebaseerde aanpak de meest nauwkeurige en stabiele kaarten. Het verminderde voorspellingsfouten veel meer dan polynomiale regressie en bleef consequent beter dan support vector machines, neurale netwerken en andere methoden, vooral tijdens de moessonmaanden wanneer de neerslag het hevigst en meest variabel is. De resulterende kaarten waren glad waar dat passend was, maar legden toch scherpe contrasten tussen droge en natte zones vast, met relatief lage onzekerheid.
Wat veranderende neerslagpatronen onthullen
Door de twee decennia te vergelijken, zag de studie ook tekenen van verschuivend neerslaggedrag. Gemiddeld was het latere decennium (2011–2021) natter, met grotere maand-tot-maand en plaats-tot-plaats variabiliteit, met name in het voorjaar en tijdens de moesson. De ruimtelijke structuur van neerslag werd meer verspreid, wat wijst op bredere schommelingen in waar water valt. Belangrijk is dat de combinatie Random Forest–kriging zowel met het eerdere, enigszins mildere klimaat als met de meer variabele recente periode omging zonder nauwkeurigheid te verliezen, wat suggereert dat zulke flexibele hulpmiddelen goed passen bij een opwarmende, minder voorspelbare wereld.
Van kaarten naar beslissingen op de grond
Concreet laat het artikel zien dat slimme algoritmen meer waarde uit beperkte neerslagrecords kunnen halen en hoge-resolutiekaarten produceren die nuttig zijn, zelfs in gebieden met weinig data. Voor Pakistan kunnen deze kaarten betere planning van irrigatie, reservoirbeheer en overstromingsverdediging ondersteunen en helpen gemeenschappen te identificeren die het meest worden blootgesteld aan droogte of hevige buien. De auteurs benadrukken dat hun werk een proof of concept is gericht op de kaarttechnieken zelf, nog niet op een volledig waarschuwingssysteem voor overstromingen of droogte. Toch is hun conclusie duidelijk: het combineren van ensemble-machine learning, geleid door Random Forest, met geostatistische kaartvorming biedt een krachtige, praktische manier om te volgen hoe regen verandert in droge en semi-droge gebieden wereldwijd.
Bronvermelding: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Trefwoorden: neerslagkaarten, random forest, regressie-kriging, Pakistan klimaat, watervoorraden