Clear Sky Science · nl
Zelflerend leren op grafen voorspelt associaties tussen niet-coderende RNA’s en ziekten
Waarom verborgen RNA belangrijk is voor onze gezondheid
Velen van ons leerden dat de belangrijkste taak van RNA is om te helpen bij de opbouw van eiwitten. Maar in het afgelopen decennium hebben wetenschappers een groot aantal “niet-coderende” RNA’s ontdekt die nooit eiwitten vormen en toch een rol spelen in de regulatie van cellulaire processen. Van veel van deze moleculen is inmiddels bekend dat ze kanker en andere complexe ziekten kunnen bevorderen of onderdrukken. Ontdekken welke niet-coderende RNA’s aan welke ziekten verbonden zijn, kan nieuwe wegen openen voor vroege diagnoses of nauwkeurigere behandelingen—maar elk mogelijke verband in het lab testen zou onwerkbaar traag zijn. Deze studie introduceert een krachtige computergebaseerde methode die enorme biologische netwerken kan doorzoeken en betrouwbaar de meest veelbelovende RNA–ziekteverbindingen voorstelt die onderzoekers vervolgens experimenteel kunnen verifiëren.
Van afval naar sleutelspelers in de cel
Jarenlang werden niet-coderende RNA’s afgedaan als betekenisloze restproducten van genexpressie. We weten nu dat families zoals microRNA’s, lange niet-coderende RNA’s en circulaire RNA’s belangrijke processen orkestreren, van het verpakken van DNA tot het aan- en uitzetten van genen en het doorgeven van signalen binnen cellen. Doordat ze op zoveel controlepunten zitten, kunnen zelfs kleine veranderingen in deze RNA’s het evenwicht in de richting van kanker of andere ziekten doen verschuiven. Klinische onderzoekers beschouwen ze al als potentiële biomarkers en medicijntargets. De uitdaging is schaal: er zijn duizenden verschillende RNA’s en honderden ziekten, en traditionele experimenten om elk mogelijke koppeling te testen zijn duur en tijdrovend. Hier biedt computationele voorspelling een manier om de zoekruimte te verkleinen.
Hoe je een biologisch netwerk leest
Vorigere computermethoden probeerden RNA–ziektekoppelingen te voorspellen door grote datatabellen in eenvoudigere delen te splitsen of door machine-learningmodellen te trainen op bekende voorbeelden. Deze benaderingen hielpen, maar ze negeerden vaak hoe RNA’s en ziekten in netwerken met elkaar verweven zijn. Moderne “graph neural networks” behandelen RNA’s en ziekten als knooppunten verbonden door lijnen, vergelijkbaar met een sociaal netwerk. Ze kunnen patronen leren in wie met wie verbonden is. Echter, de meeste van deze grafmethoden hebben veel betrouwbare trainingsvoorbeelden en zorgvuldig ontworpen invoerkenmerken nodig. Dat maakt ze gevoelig voor ontbrekende data, ruis in metingen en overfitting—ze presteren goed op bekende data maar falen bij het voorspellen van nieuwe associaties.
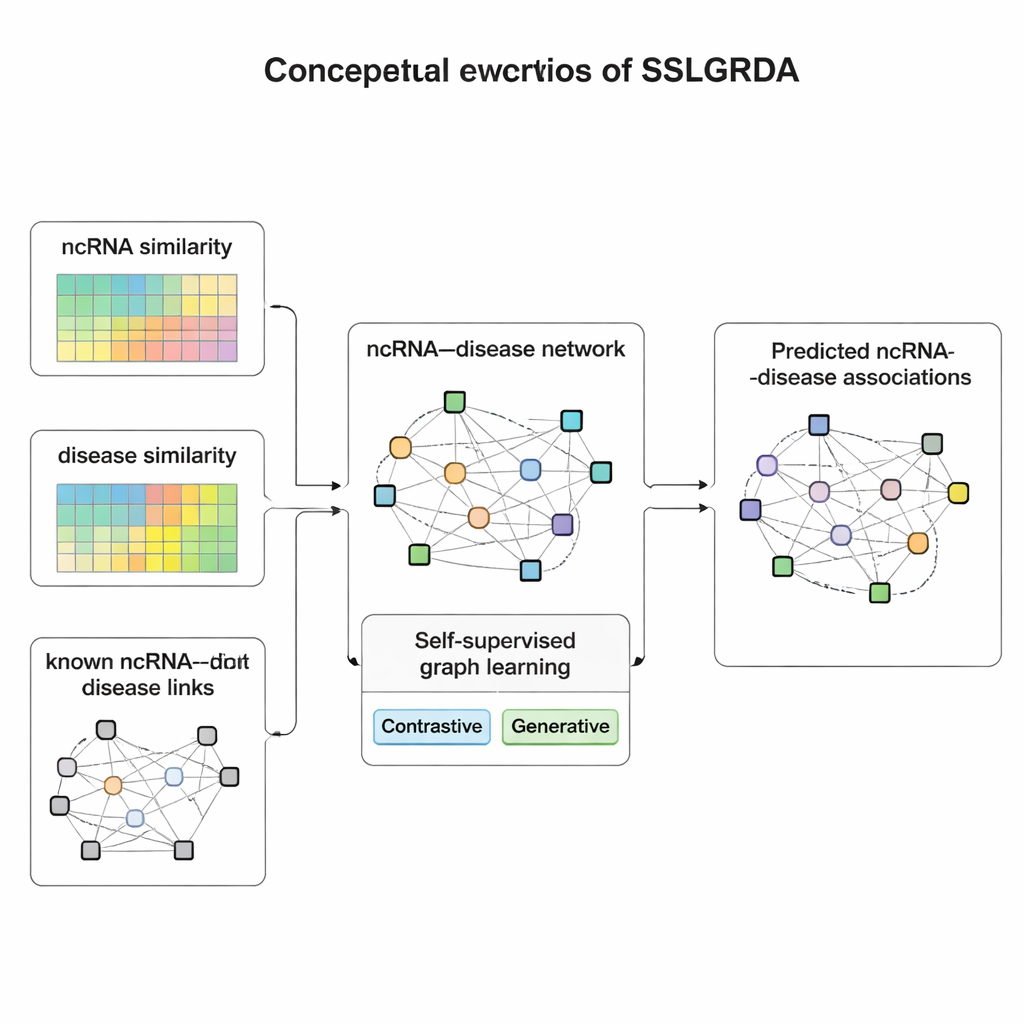
Leren vanuit de data zelf
De auteurs presenteren SSLGRDA, een nieuw raamwerk dat een grafmodel leert nuttige patronen te vinden zonder sterk te leunen op gelabelde trainingsdata. Het kernidee is “zelflerend leren”: in plaats van te vertellen welk RNA bij welke ziekte hoort, verzint het model zijn eigen oefentaken die uitsluitend zijn gebaseerd op de structuur en attributen van het netwerk. De onderzoekers bouwen twee typen grafen. De ene houdt RNA’s en ziekten als verschillende knooppunttypen gescheiden, verbonden door bekende links. De andere mengt ze tot één groot homogeen netwerk dat ook vergelijkbaarheidsinformatie bevat—hoe gelijk twee RNA’s of twee ziekten aan elkaar zijn—zodat zelfs zwak verbonden onderdelen ondersteunende buren krijgen. Bovenop deze grafen gebruikt SSLGRDA twee stijlen van zelftraining. Contrasterende strategieën vragen het model te herkennen dat verschillende “weergaven” van hetzelfde knooppunt (bijvoorbeeld zijn verbindingen versus zijn attributen) tot vergelijkbare interne representaties moeten leiden, terwijl niet-gerelateerde knooppunten duidelijk van elkaar gescheiden worden. Generatieve strategieën verbergen opzettelijk delen van de invoerkenmerken en dagen het model uit om die te reconstrueren, waardoor het wordt aangemoedigd diepere structuren te vatten in plaats van ruis te memoriseren.
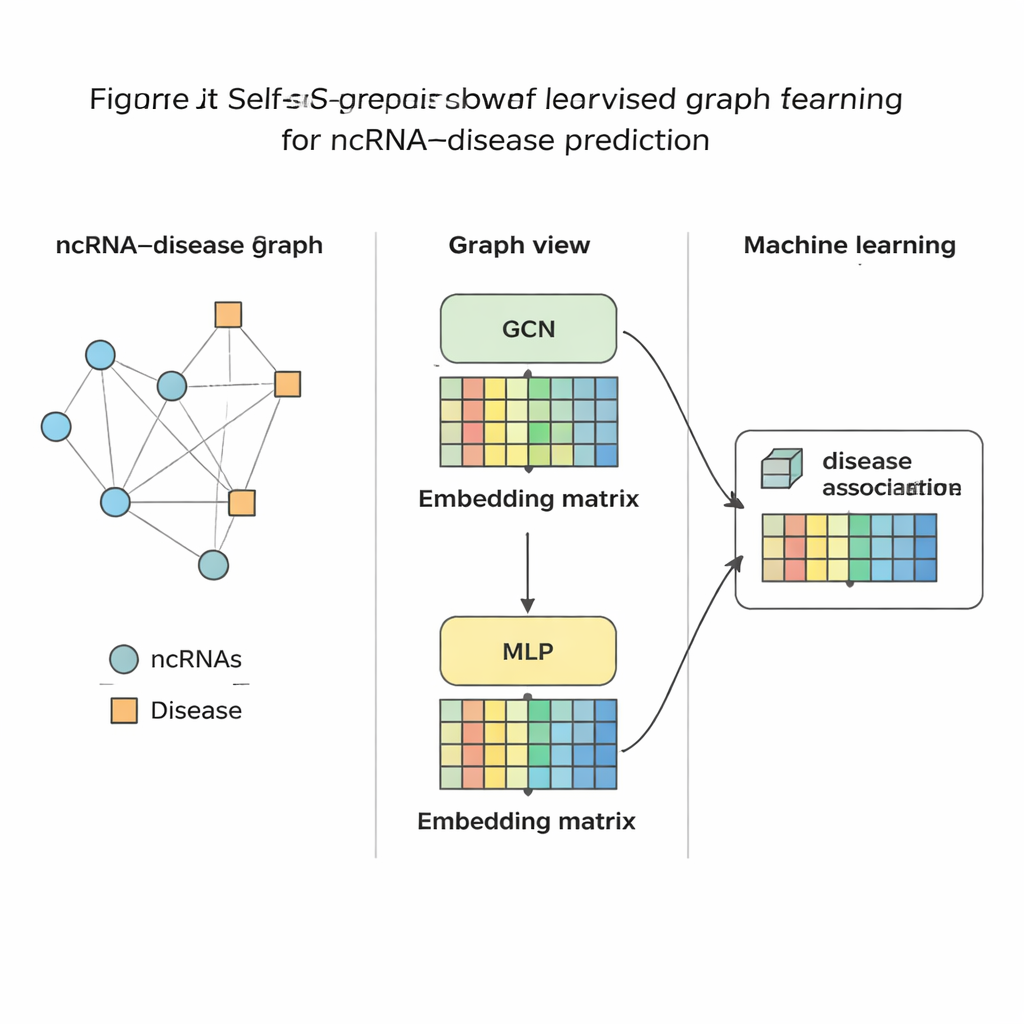
De methode op de proef gesteld
Wanneer SSLGRDA elk RNA en elke ziekte heeft teruggebracht tot een compacte numerieke vingerafdruk, wordt een standaard machine-learningclassifier getraind om te beoordelen of een link tussen hen waarschijnlijk is. De auteurs evalueerden deze aanpak op negen verschillende datasets die drie belangrijke RNA-typen en honderden ziekten beslaan. Over de hele linie presteerden hun contrasterende zelflerende varianten op het gemengde (homogene) netwerk het beste, en versloegen ze een reeks bestaande tools, inclusief sterke grafgebaseerde baseline-methoden. De methode behaalde niet alleen hogere nauwkeurigheid in globale tests, maar rangschikte bij focus op één RNA of één ziekte ook de correcte partners naar de top—cruciaal voor praktisch gebruik waarbij een bioloog vanaf één kanker start en wil weten welke RNA’s te bestuderen. Ze toonden verder aan dat dezelfde ideeën goed overdraagbaar zijn naar andere biomedische netwerken, zoals die microben met ziekten of geneesmiddelen verbinden.
Van voorspellingen naar potentiële therapieën
Om praktische waarde te demonstreren paste het team SSLGRDA toe om nieuwe niet-coderende RNA’s te zoeken die betrokken zijn bij borstkanker, darmkanker en verschillende andere aandoeningen. Veel van de hoogst gerangschikte suggesties werden later bevestigd in onafhankelijke databases of wetenschappelijke rapporten, wat de capaciteit van het model ondersteunt om biologisch betekenisvolle patronen te herkennen. Voor niet-specialisten is de kernboodschap dat dit werk een slimmere manier biedt om de steeds complexer wordende warboel van biologische data te doorzoeken op verborgen ziekte-indicaties. Door automatisch te leren hoe RNA’s en ziekten clusteren en interacteren, kunnen zelflerende grafmethoden zoals SSLGRDA laboratoriumonderzoekers naar de meest veelbelovende doelen leiden en zo mogelijk het traject van ruwe data naar betere diagnostiek en behandelingen versnellen.
Bronvermelding: Wu, Q., Tang, S. Self-supervised learning on graphs predicts non-coding RNA and disease associations. Sci Rep 16, 5231 (2026). https://doi.org/10.1038/s41598-026-36030-2
Trefwoorden: niet-coderend RNA, ziekte-associatie, graph neural networks, zelflerend leren, computationele biologie