Clear Sky Science · nl
Identificatie van diagnostische en prognostische biomarkers bij longadenocarcinoom via geïntegreerde bioinformatica-analyse en realtime PCR-validatie
Waarom het vroeg opsporen van longkanker ertoe doet
Longkanker behoort tot de dodelijkste vormen van kanker, grotendeels omdat de ziekte vaak te laat wordt ontdekt. De meest voorkomende vorm, longadenocarcinoom, kan jarenlang stil groeien voordat het klachten veroorzaakt. Deze studie onderzoekt of patronen in ons bloed en in tumorweefsel de ziekte veel eerder kunnen onthullen. Door grootschalige genetische datasets te combineren met kunstmatige intelligentie en de resultaten vervolgens te verifiëren in echte patiënten, willen de onderzoekers eenvoudige bloedmarkers vinden die artsen in de toekomst kunnen helpen longkanker eerder op te sporen en de behandeling te sturen.
Op zoek naar waarschuwingssignalen in genen
Het team begon met RNA-sequencingdata van 522 personen, waaronder 506 met longadenocarcinoom en 16 gezonde controles. RNA is de "werkende kopie" van onze genen en weerspiegelt welke genen in cellen aan- of uitgezet zijn. Na zorgvuldige kwaliteitscontrole en normalisatie van de gegevens vergeleken ze de genactiviteitsniveaus tussen kankergemonsterde en niet-kankergemonsterde weefsels. Dit bracht 3.513 genen aan het licht waarvan de activiteit significant verschilde bij patiënten. Deze genen, differentieel tot expressie gebrachte genen genoemd, vormden het ruwe materiaal voor een computermodel dat kon leren onderscheid te maken tussen kankerachtig en gezond weefsel op basis van genpatronen.

Computers leren kanker herkennen
Om door duizenden genen te gaan, gebruikten de onderzoekers een diepleerbenadering, een vorm van kunstmatige intelligentie geïnspireerd op netwerken van hersencellen. Ze bouwden een neuraal netwerk met meerdere verborgen lagen dat genactiviteitsgegevens intake en leerde elk monster als kwaadaardig of gezond te classificeren. Het model werd getraind op het grootste deel van de data en vervolgens getest op een afzonderlijk deel dat het nog nooit had gezien. De prestaties waren opvallend: het systeem identificeerde cases en controles met ongeveer 98% nauwkeurigheid, een area-under-the-curve van 1,0 (bijna perfecte score), en een extreem lage foutmarge in zijn waarschijnlijkheidsschattingen. Uit dit model haalden ze 20 genen die het sterkst bijdroegen aan de beslissingen, waarmee een korte lijst van veelbelovende kandidaten voor verder onderzoek werd benadrukt.
Van computervoorspellingen naar echte bloedtesten
Het vinden van genpatronen in grote databanken is alleen nuttig als die patronen ook bij echte mensen zichtbaar zijn. Om dit te testen verzamelden de onderzoekers bloed van 30 patiënten met longadenocarcinoom (allemaal in een vroeg- tot middenstadium en zonder eerdere behandeling) en 30 gezonde vrijwilligers, gematcht op leeftijd en geslacht. Met een laboratoriummethode genaamd realtime PCR maten ze hoe sterk verschillende voorspelde markergenen tot expressie kwamen in bloedcellen. Vooral vier genen vielen op. CYP2C9, KRT14 en PECAM1 waren veel actiever in het bloed van patiënten dan in dat van gezonde personen, terwijl A2M minder actief was. Zo waren CYP2C9-niveaus ongeveer viermaal hoger en KRT14 ongeveer achtmaal hoger bij patiënten, terwijl A2M ruwweg de helft zo veel voorkwam. Deze duidelijke verschillen suggereren dat een gecombineerde bloedtest voor deze markers kan helpen vaststellen wie longadenocarcinoom heeft.
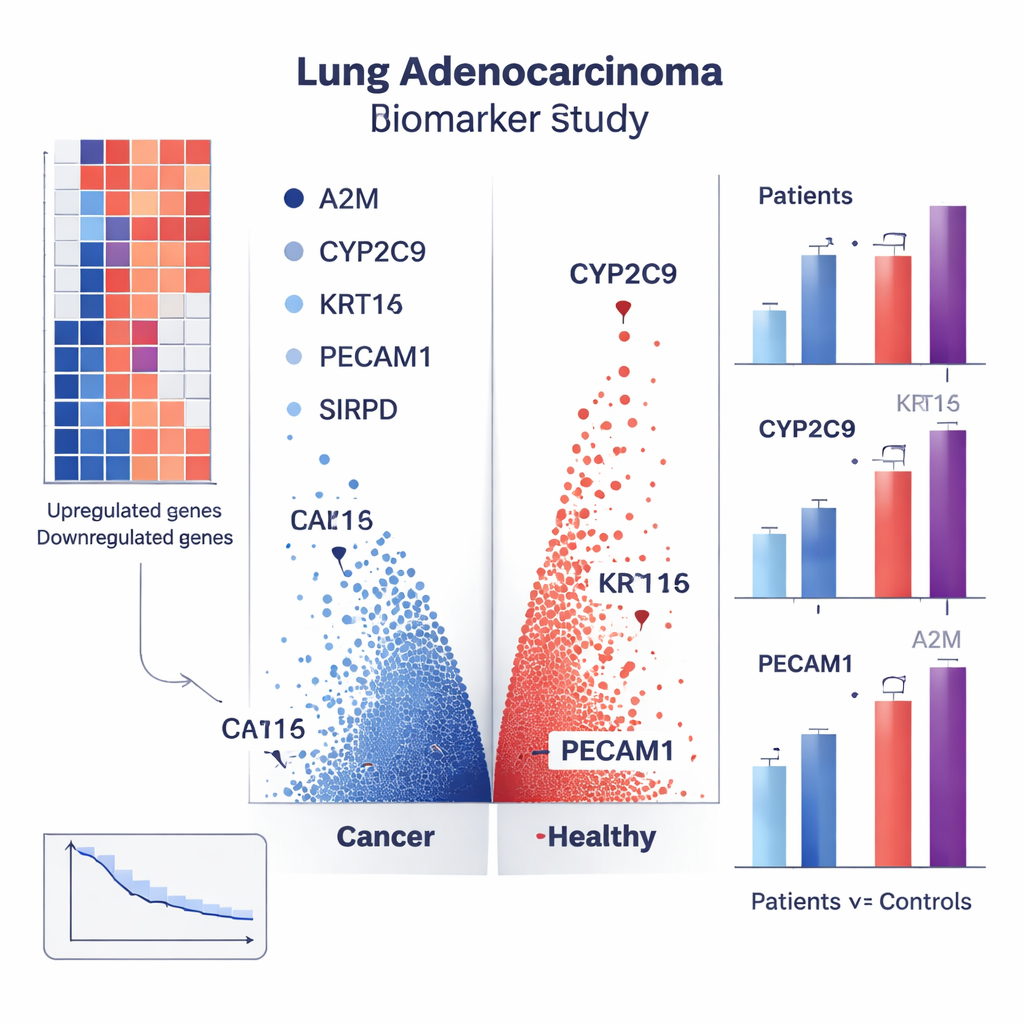
Aanwijzingen over prognose en ziektegedrag
De studie ging verder dan een eenvoudige ja-of-nee-diagnose. Door genactiviteit te koppelen aan klinische informatie zoals tumorgrootte, uitzaaiing, stadium en patiëntoverleving, identificeerde het team genen die mogelijk voorspellen hoe iemands kanker zich zal gedragen. Verschillende genen, waaronder CYP2C9, KCNV1, KRT24, SIRPD, PECAM1 en een niet-coderend gen genaamd LOC730668, waren geassocieerd met uitkomsten bij patiënten. Sommige lijken gerelateerd aan bloedvatgroei die tumoren voedt, terwijl andere te maken hebben met hoe kankercellen omgaan met het immuunsysteem of weerstand bieden tegen celdood. Externe controles in meerdere onafhankelijke datasets toonden aan dat de meeste van deze kandidaatmarkers zich consistent gedroegen, wat het vertrouwen vergroot dat de bevindingen geen toevalstreffer uit één dataset zijn.
Wat dit voor patiënten zou kunnen betekenen
In eenvoudige bewoordingen laat dit werk zien dat een slimme combinatie van vijf genen—A2M, CYP2C9, KCNV1, KRT24 en SIRPD—longadenocarcinoom met hoge gevoeligheid kan signaleren in genetische data, en dat ten minste vier van deze genen duidelijke, meetbare veranderingen in bloed laten zien. Hoewel deze markers nog niet klaar zijn voor routinematige screening, bieden ze een veelbelovend uitgangspunt voor toekomstige bloedtests die longkanker vroeger zouden kunnen detecteren, wanneer de ziekte beter te behandelen is. Ze zouden artsen ook kunnen helpen inschatten hoe agressief een tumor is en de behandeling daarop afstemmen. Verdere studies in grotere en diversere patiëntengroepen zijn nodig, maar de resultaten suggereren dat kunstmatige intelligentie, gecombineerd met zorgvuldige laboratoriumvalidatie, het zoeken naar praktische, minimaal invasieve middelen om longkanker te bestrijden kan versnellen.
Bronvermelding: Hossein Zadeh, R., Hossein Zadeh, R., Hajimoradi, M. et al. Identification of diagnostic and prognostic biomarkers in lung adenocarcinoma through integrated bioinformatics analysis and real time PCR validation. Sci Rep 16, 6679 (2026). https://doi.org/10.1038/s41598-026-35971-y
Trefwoorden: longadenocarcinoom, biomarkers, diep leren, bloedtest, vroegtijdige kankeropsporing