Clear Sky Science · nl
De multi-parameter geoptimaliseerde belief rule base voor het voorspellen van studieresultaten met interpreteerbaarheid
Waarom het voorspellen van cijfers ieders zaak is
Rapporten lijken misschien eenvoudig, maar de krachten die iemands cijfers vormen, zijn dat allerminst. Scholen zetten in toenemende mate computermodellen in om vroegtijdig leerlingen te signaleren die worstelen en om ondersteuning te sturen. Veel van die modellen zijn echter "black boxes": ze kunnen nauwkeurig zijn, maar zelfs leraren en ouders zien niet waarom een voorspelling is gedaan. Dit artikel presenteert een nieuwe aanpak die zowel zeer nauwkeurig als gemakkelijk te begrijpen wil zijn, zodat opvoeders het resultaat kunnen vertrouwen en erop kunnen handelen.
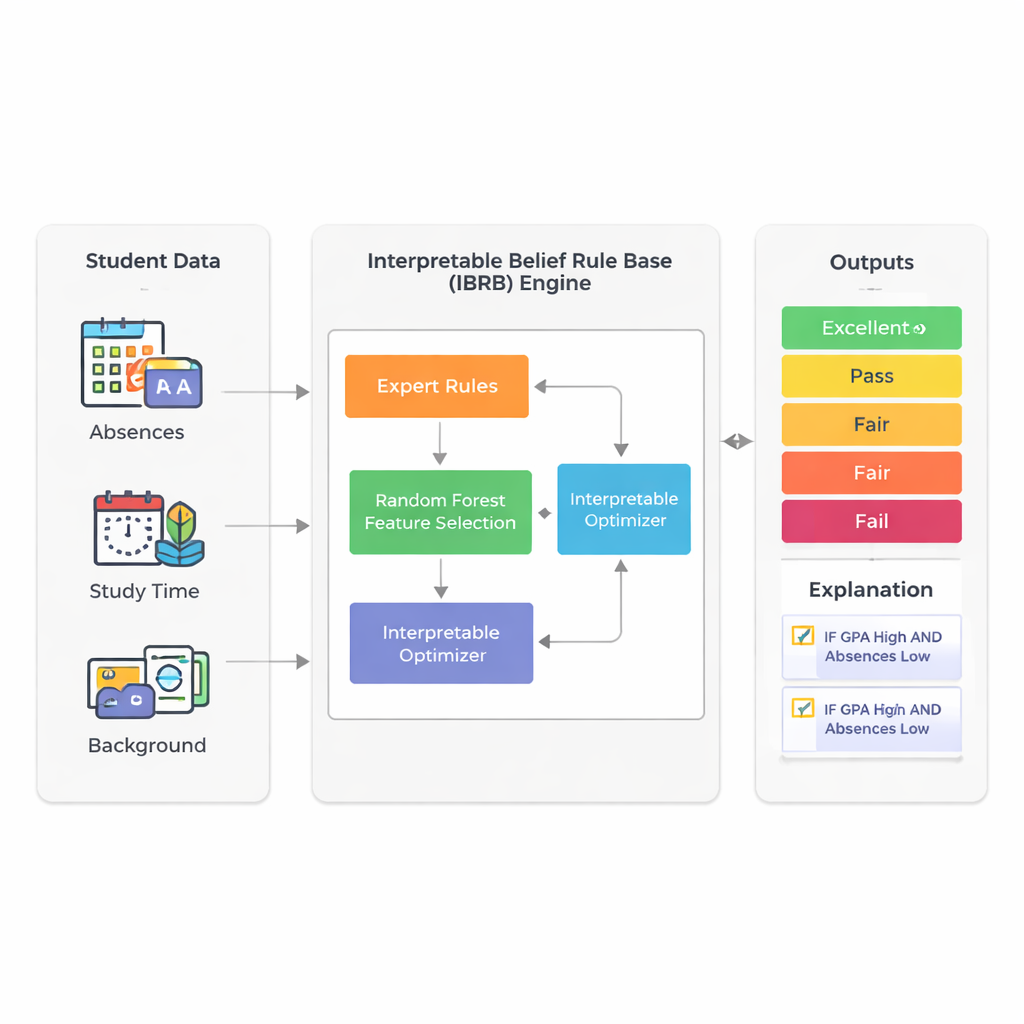
Een slimmer manier om signalen te lezen
De studie richt zich op het voorspellen van hoe goed leerlingen uiteindelijk zullen presteren door gebruik te maken van informatie die scholen al verzamelen: grade point average (GPA), afwezigheden, studietijd, achtergrond en familie- en activiteitfactoren. In plaats van te steunen op ondoorzichtige deep-learning-systemen bouwen de auteurs voort op een techniek die een belief rule base wordt genoemd. In dit kader schrijven experts regels die veel lijken op wat een docent zou zeggen: "Als GPA hoog is en afwezigheden laag, dan zal de leerling waarschijnlijk goed presteren." Elke regel draagt een mate van overtuiging over mogelijke uitkomsten zoals Excellent, Good, Pass, Fair of Fail. Dat maakt het redeneerproces zichtbaar en in beginsel uitlegbaar voor niet-experts.
Complexiteit temmen zonder betekenis te verliezen
Een grote uitdaging bij regelsystemen is dat ze uit de hand kunnen lopen wanneer veel leerlingkenmerken worden opgenomen: elke extra factor vermenigvuldigt het aantal mogelijke regels. Om deze "rule explosion" te vermijden gebruiken de onderzoekers eerst een random forest—een veelgebruikt ensemble van beslisbomen—om te meten welke kenmerken het belangrijkst zijn voor het voorspellen van prestaties. In hun echte dataset van 2.392 studenten uit een openbare bron verklaren GPA en aantal afwezigheden ongeveer 73% van de voorspellende kracht van het model. Door opzettelijk slechts deze twee invoerwaarden te behouden, blijft het uiteindelijke model compact en makkelijker te interpreteren, terwijl het toch het grootste deel van de variatie in leerlinguitkomsten weerspiegelt.
Regels bouwen die mensen kunnen volgen
De kern van het nieuwe model, genoemd IBRB-m, is een zorgvuldig gestructureerde set van 25 regels die niveaus van GPA en afwezigheden combineren met geloofsgraadwaarden voor de vijf prestatielcategorieën. De auteurs formaliseren wat het betekent dat zo’n model "interpreteerbaar" is. Tot hun vereisten behoren: elk referentieniveau (zoals "lage GPA") moet een duidelijke en onderscheidende reeks bestrijken; de rule base moet alle realistische combinaties van invoer dekken; parameters zoals regelgewichten en attributengewichten moeten alledaagse betekenissen hebben; en de interne berekeningen van het systeem moeten informatie op een transparante, wiskundig consistente manier transformeren. Daarnaast voegen ze onderwijs-specifieke richtlijnen toe die de voorspellingen dwingen om redelijke vormen te volgen—bijvoorbeeld het vermijden van bizarre gevallen waarin een leerling tegelijkertijd zeer waarschijnlijk zou excelleren en zou zakken.
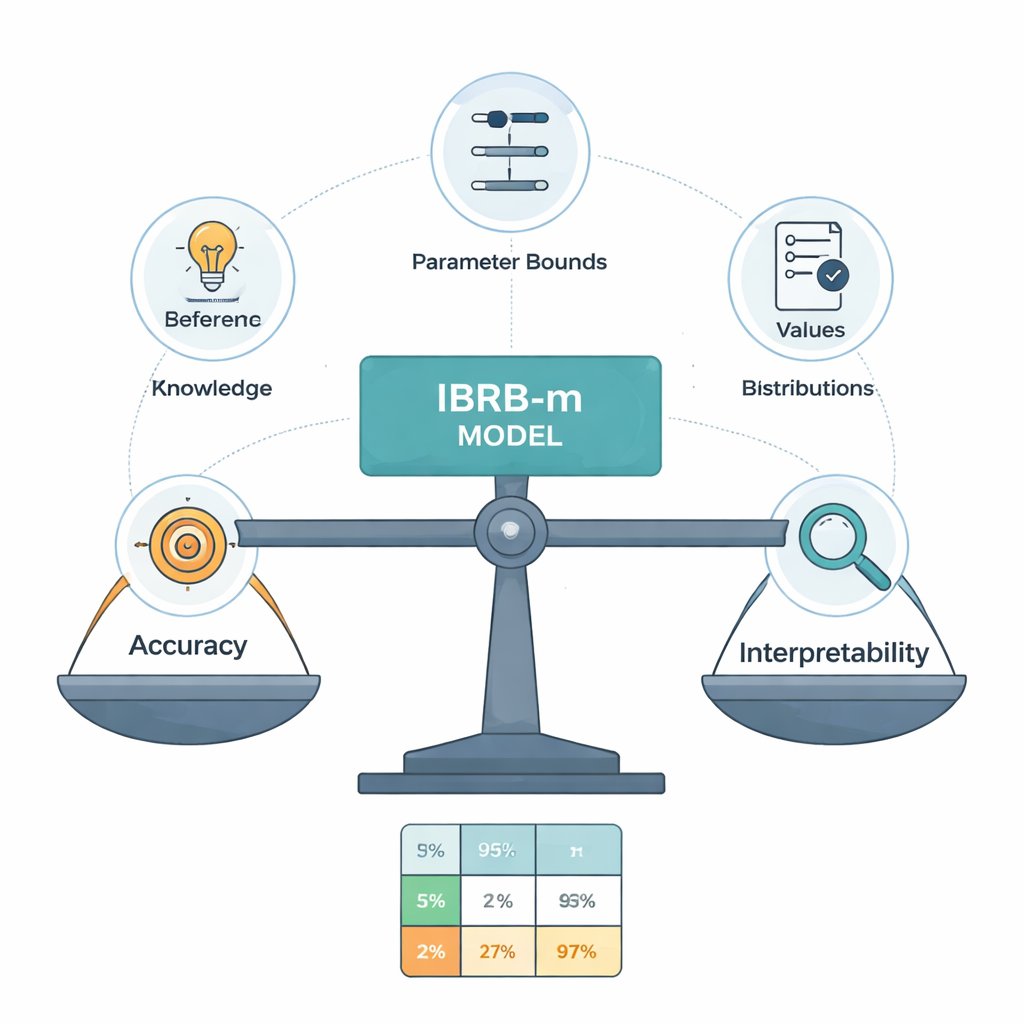
De data experts laten bijsturen
Menselijke experts zijn het niet altijd met elkaar eens en hun initiële regels kunnen onnauwkeurig zijn. Om deze regels te verfijnen zonder het model een black box te maken, ontwerpen de auteurs een verbeterd optimalisatie-algoritme dat zoekt naar betere parameterwaarden terwijl strikte interpretatiebeperkingen worden nageleefd. Dit algoritme past niet alleen regelgewichten en geloofsgraadwaarden aan, maar ook de afkappunten die categorieën zoals Excellent of Pass definiëren. Het houdt alle wijzigingen binnen door experts goedgekeurde grenzen en dwingt redelijke, vloeiende geloofspatronen over de cijfers heen. In wezen "duwt" de computer het expertsysteem naar hogere nauwkeurigheid, maar mag het geen regels verzinnen die een ingewijde docent zouden verbijsteren.
Hoe goed werkt het in de praktijk?
Getest op de Kaggle student performance-dataset voorspelt het IBRB-m-model in meer dan 99% van de gevallen correct de uiteindelijke prestatieniveaus, en overtreft daarmee zowel eerdere belief-rule-systemen als gangbare machine-learningtools zoals neurale netwerken, random forests en k-nearest neighbors. Even belangrijk blijft de geoptimaliseerde set regels dicht bij de oorspronkelijke expertbeoordelingen wanneer gemeten met een eenvoudige afstandsmaatstaf, wat betekent dat het redeneren achter elke voorspelling nog steeds kan worden herleid en gerechtvaardigd. Cross-validatie over meerdere verdelingen van de data toont aan dat de prestaties van het model stabiel zijn en geen gelukstreffer door een gelukkige partitionering.
Wat dit betekent voor klaslokalen
Voor niet-specialisten is de belangrijkste conclusie dat het mogelijk is om voorspellingsinstrumenten voor leerlingen te hebben die zowel krachtig als begrijpelijk zijn. In plaats van mysterieuze risicoscores te geven kan het model concrete patronen benadrukken, zoals "matige GPA maar frequente afwezigheden", en laten zien hoe deze leiden tot een Fair- of Fail-voorspelling. Leraren en counselors kunnen dan reageren met gerichte maatregelen—zoals ondersteuning bij aanwezigheid of studievaardigheidstraining—terwijl ze leerlingen en ouders overtuigend kunnen uitleggen waarom het model tot die conclusie kwam. De auteurs betogen dat deze mix van nauwkeurigheid en transparantie essentieel is als op data gebaseerde systemen een vertrouwde rol willen spelen in het bevorderen van rechtvaardig en effectief onderwijs.
Bronvermelding: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Trefwoorden: voorspelling van studieresultaten, interpreteerbare AI, belief rule base, educational data mining, Explainable machine learning