Clear Sky Science · nl
Beoordeling van beïnvloedende factoren op de onderwijsresultaten van hogescholen en universiteiten met behulp van fuzzy- en deep-learningtechnieken
Waarom betere meetmethoden voor onderwijs ertoe doen
Iedereen die zowel uitstekende als minder goede colleges heeft gevolgd, weet dat de kwaliteit van het onderwijs een studie-ervaring kan maken of breken. Toch vertrouwen de meeste universiteiten nog steeds op grof gereedschap zoals testscores en eindejaarsenquêtes om te beoordelen wat werkt. Dit artikel onderzoekt een slimmere manier om te meten hoe goed universiteiten lesgeven door twee computergebaseerde methoden te combineren — één die goed omgaat met vage, menselijke data en een andere die uitblinkt in het opsporen van verborgen patronen. Samen beloven ze betrouwbaardere aanwijzingen voor het verbeteren van cursussen en het ondersteunen van studenten.
Het idee van een ‘goed college’ heroverwegen
Hogeronderwijsonderwijs wordt gevormd door veel bewegende onderdelen: hoeveel studenten er in de zaal zitten, hoe ervaren de docent is, hoe zwaar de cursus is, de sfeer in het lokaal en het gebruik van technologie, om er maar een paar te noemen. Traditionele beoordelingssystemen reduceren dit vaak tot één testscore of een numerieke cursusbeoordeling. Die oversimplificatie mist belangrijke context en negeert de rommelige, subjectieve kant van leren. De auteurs betogen dat als we willen begrijpen waarom sommige colleges studenten laten floreren terwijl andere tekortschieten, we tools nodig hebben die met vele factoren tegelijk kunnen omgaan en kunnen werken met onvolmaakte, op meningen gebaseerde informatie.
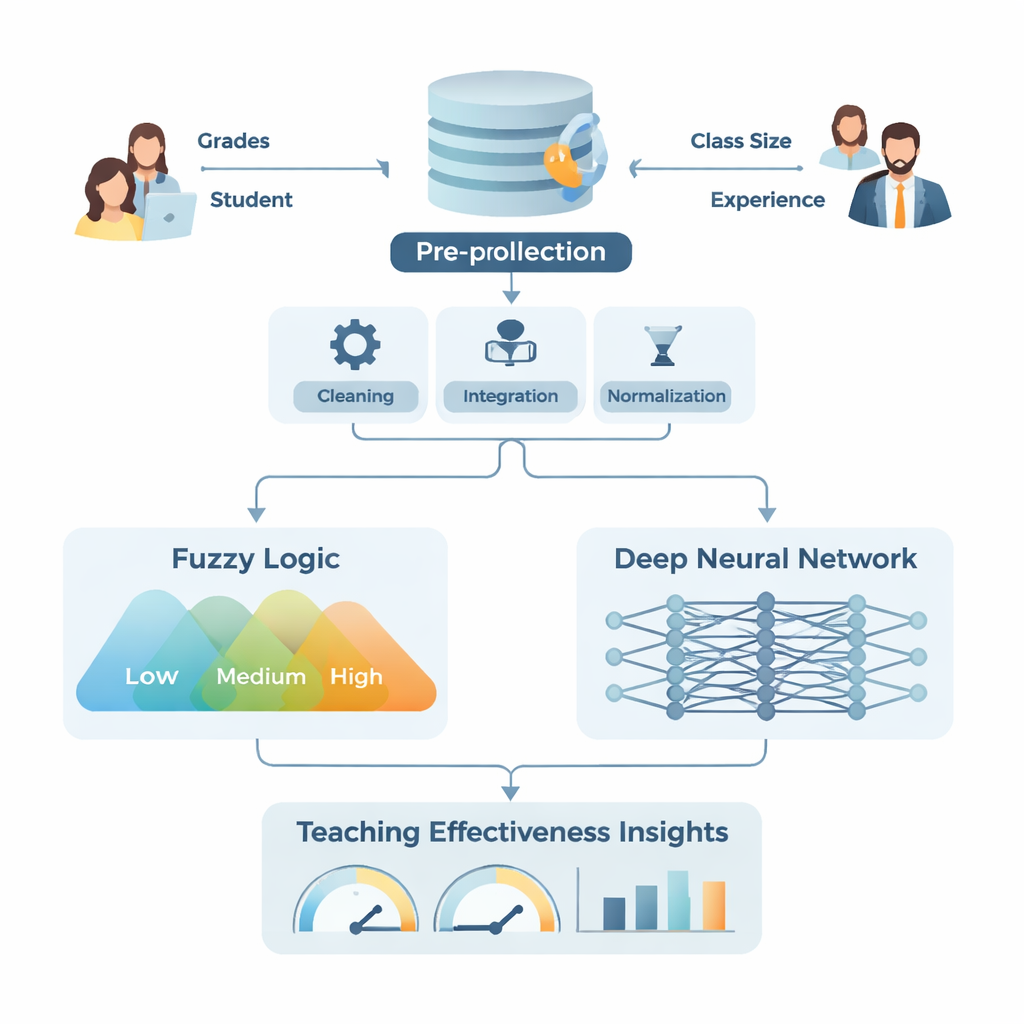
Een hybride aanpak: ‘menselijk-achtig’ en ‘patroonherkenning’
De studie introduceert een hybride model genaamd Fuzzy and Deep Learning (FDL). Het 'fuzzy'-gedeelte bootst na hoe mensen in grijstinten denken in plaats van in strikte ja/nee-categorieën — bijvoorbeeld door te zeggen dat iemands prestatie 'laag', 'gemiddeld' of 'hoog' is met vloeiende overgangen in plaats van harde grenzen. Het zet vage invoer zoals onderwijservaring, student‑docentverhouding en cursusmoeilijkheid om in flexibele categorieën en gebruikt vervolgens eenvoudige regels zoals "als studentprestaties hoog zijn en de klas klein is, dan is de onderwijseffectiviteit hoog." Het deep-learninggedeelte is een gelaagd netwerk dat grote hoeveelheden schoongemaakte en gestandaardiseerde data verwerkt en complexe verbanden blootlegt die voor menselijke beoordelaars misschien niet duidelijk zijn.
Van ruwe enquêtes naar betekenisvolle signalen
Om hun aanpak te testen gebruikten de onderzoekers gegevens van de National Survey of Student Engagement, een grote en veelgebruikte vragenlijst ingevuld door eerstejaars en laatstejaars studenten aan Noord‑Amerikaanse hogescholen en universiteiten. Ze pasten verschillende vragen aan om scherper te focussen op hoe goed docenten hun rol vervullen en controleerden vervolgens of de herziene vragenlijst betrouwbaar was. Daarna voerden ze een grondige datapreparatiepipeline uit: fouten opschonen, ontbrekende waarden invullen, informatie van studenten- en docentzijde samenvoegen en alles schalen naar een gemeenschappelijk bereik. Ze creëerden ook gecombineerde indicatoren, zoals een gewogen eindcijfer gebaseerd op tentamenscores, huiswerkinzending en aanwezigheid, en verlaagden de datacomplexiteit met een standaardtechniek genaamd hoofdcomponentenanalyse. Deze voorbereide dataset voedde zowel de fuzzy-logicamodule, die met onpreciese categorieën omging, als het deep-learningnetwerk, dat hoge-dimensionale numerieke patronen aanpakte.
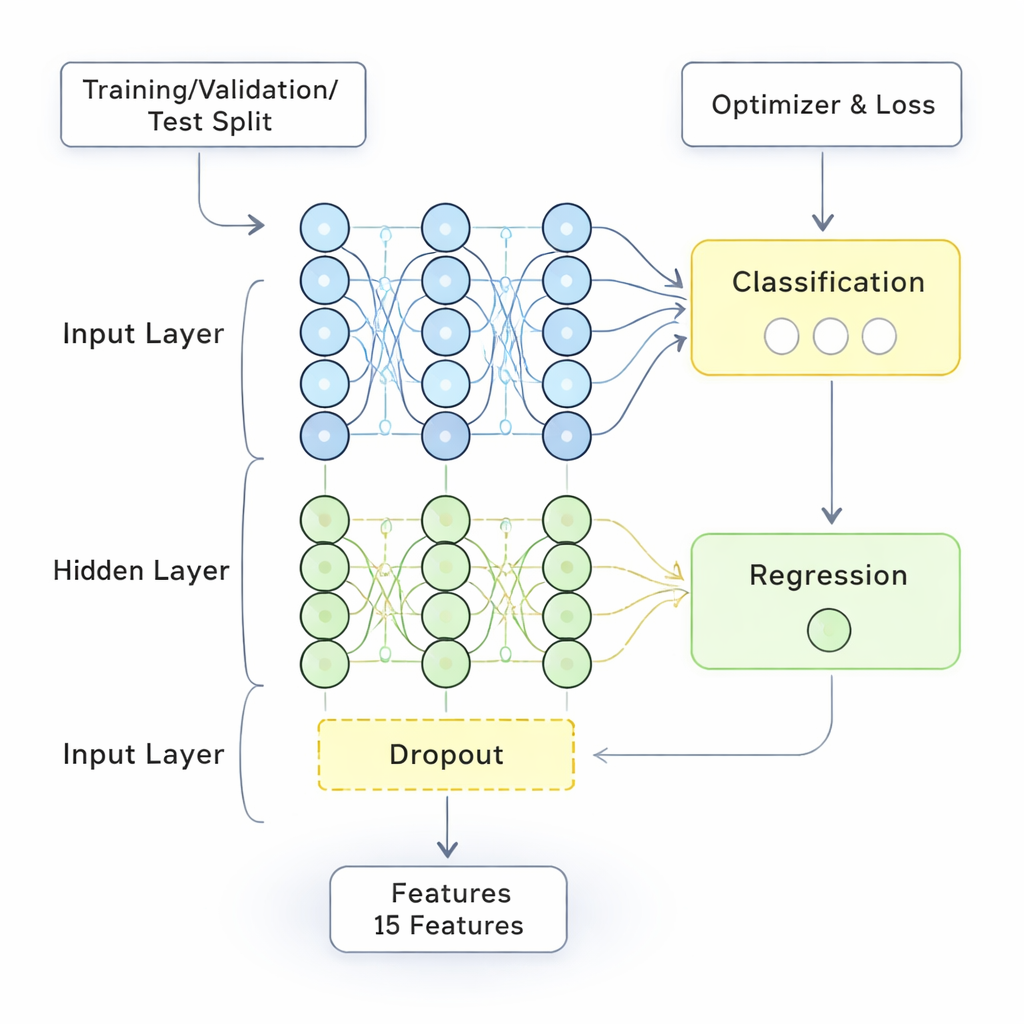
Hoe goed werkt het nieuwe model?
Het FDL-model werd getraind en getest op aparte delen van de data om te voorkomen dat het zichzelf zou misleiden met bekende voorbeelden. De prestaties werden vergeleken met verschillende sterke alternatieven, waaronder standaard neurale netwerken en meer geavanceerde deepmodellen. Over belangrijke maten — algemene nauwkeurigheid, precisie, recall en F1-score — evenaarde of overtrof de hybride methode de concurrerende benaderingen, met ongeveer 98% nauwkeurigheid en een lage foutmarge van iets meer dan 10%. Even belangrijk maakten de fuzzy-regels de beslissingen interpreteerbaarder dan bij black-boxmodellen. Het systeem kon aangeven welke combinaties van factoren — zoals grote klassen in combinatie met weinig onderwijservaring, of veeleisende cursussen ondersteund door sterke feedback — het sterkst gekoppeld waren aan betere of slechtere onderwijsprestaties.
Wat dit betekent voor studenten en instellingen
Simpel gezegd laat de studie zien dat het nu mogelijk is om een geautomatiseerde 'onderwijsbarometer' te bouwen die zowel zeer nauwkeurig als redelijk begrijpelijk is. In plaats van voornamelijk te leunen op grove gemiddelden en eenmalige enquêtes, zouden instellingen een dergelijk systeem kunnen gebruiken om zwakke onderwijssituaties vroegtijdig te signaleren, te identificeren welke docenten of cursussen gerichte ondersteuning nodig hebben, en te testen of nieuwe beleidsmaatregelen daadwerkelijk bijdragen aan meer leren. De auteurs benadrukken dat het model niet perfect is — het hangt af van de datakwaliteit, kan veel rekencapaciteit vereisen en vereenvoudigt onvermijdelijk de rijke menselijke kant van onderwijs. Toch biedt het, mits zorgvuldig gebruikt, een krachtig nieuw perspectief om collegevakken effectiever, eerlijker en responsiever op de behoeften van studenten te maken.
Bronvermelding: He, Z., Zhang, X., Zhang, Z. et al. Assessment of influencing factors of college and universities’ teaching effects using fuzzy and deep learning techniques. Sci Rep 16, 5168 (2026). https://doi.org/10.1038/s41598-026-35940-5
Trefwoorden: onderwijseffectiviteit, hoger onderwijs, studentprestaties, fuzzy-logica, deep learning