Clear Sky Science · nl
Door reinforcement learning aangedreven dynamische optimalisatiestrategie voor parametrisch ontwerp van 3D-modellen
Slimmere 3D-ontwerpen met minder giswerk
Van opvallende gebouwen tot kleine mechanische onderdelen in je telefoon: veel moderne objecten beginnen als 3D-computermodellen. Ontwerpers gebruiken vaak “parametrische” modellen, waarbij schuifregelaars en formules vormen, afmetingen en patronen bepalen. Dat maakt het gemakkelijk om veel opties te verkennen, maar creëert ook een doolhof aan mogelijkheden die onmogelijk handmatig te doorlopen is. Dit artikel introduceert een nieuwe kunstmatige-intelligentiebenadering genaamd HRL-DOS die computers helpt dat doolhof te navigeren en automatisch 3D-ontwerpen verbetert op sterkte, materiaalgebruik en produceerbaarheid.
De uitdaging van te veel keuzes
In parametrisch ontwerp kan een enkel object van tientallen of honderden gekoppelde parameters afhangen: wanddiktes, gatmaten, krommen en uitlijnregels. Naarmate modellen complexer worden, beïnvloeden die parameters elkaar op niet‑voor de hand liggende manieren. Traditionele optimalisatietools vertrouwen ofwel op gladde wiskundige functies, die falen wanneer ontwerpen onregelmatig of ruisachtig zijn, of op trial‑and‑error zoekmethoden, die pijnlijk traag kunnen zijn voor grote problemen. Zelfs standaard reinforcement learning — waarbij een AI-agent leert van herhaalde proeven en feedback — worstelt wanneer hij alle mogelijke combinaties van ontwerpbeslissingen tegelijk moet overwegen.
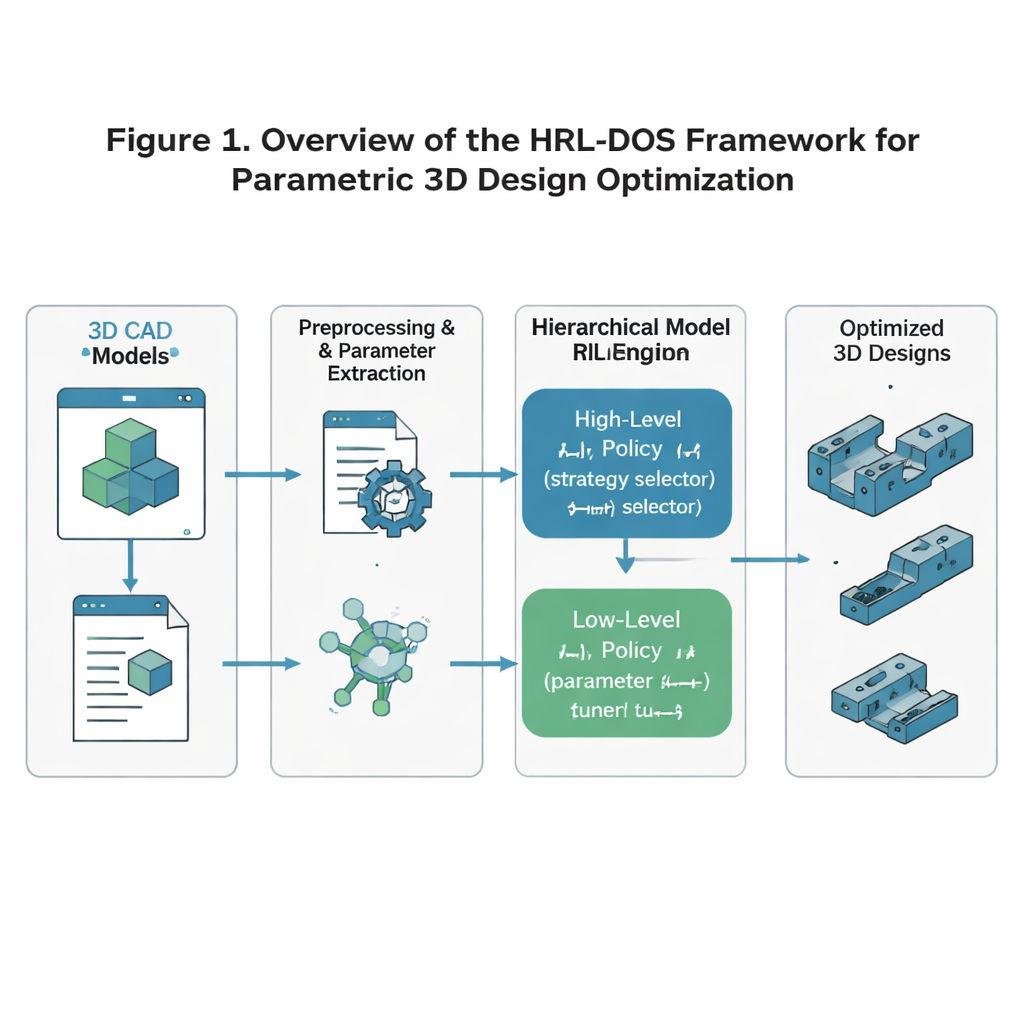
Een tweelaagse AI die denkt als een ontwerper
De auteurs stellen de Hierarchical Reinforcement Learning‑based Dynamic Optimization Strategy voor, of HRL‑DOS, om met deze complexiteit om te gaan. In plaats van ontwerp te behandelen als één enorme beslissing, verdeelt HRL‑DOS de taak in twee lagen. Een high‑level policy kiest een algemene richting voor het ontwerp — zoals het bevoordelen van lager gewicht, meer symmetrie of extra veiligheidsmarge. Een low‑level policy past vervolgens individuele parameters aan, zoals specifieke afmetingen of plaatsing van features, binnen dat bredere plan. Beide lagen ontvangen feedback op basis van hoe goed het huidige model presteert op drie kernobjectieven: structurele stabiliteit, geometrische efficiëntie en produceerbaarheid. Deze gelaagde structuur weerspiegelt hoe menselijke ontwerpers werken: eerst een concept bepalen, daarna de details verfijnen.
Ruwe 3D-modellen omzetten in leerbare data
Om dit systeem te trainen, beginnen de onderzoekers met de ABC Dataset, een grote open verzameling gedetailleerde industriële 3D-modellen zoals beugels, tandwielen, hefbomen en montageplaten. Ze preprocessen elk model zodat de AI een schone, consistente representatie ziet: de geometrie wordt genormaliseerd naar een standaard schaal en oriëntatie; sleutelafmetingen en features worden als parameters geëxtraheerd; en fabricageregels — zoals minimale wanddikte of toelaatbare overhanghoeken — worden gecodeerd als beperkingen. Deze parameters worden vervolgens omgezet in een compacte “latent” beschrijving die op natuurlijke wijze onmogelijk of instabiele vormen ontmoedigt. Het resultaat is een numerieke toestand die de AI veilig kan aanpassen terwijl basisregels van engineering gerespecteerd blijven.
Leren om realistische onderdelen te verbeteren
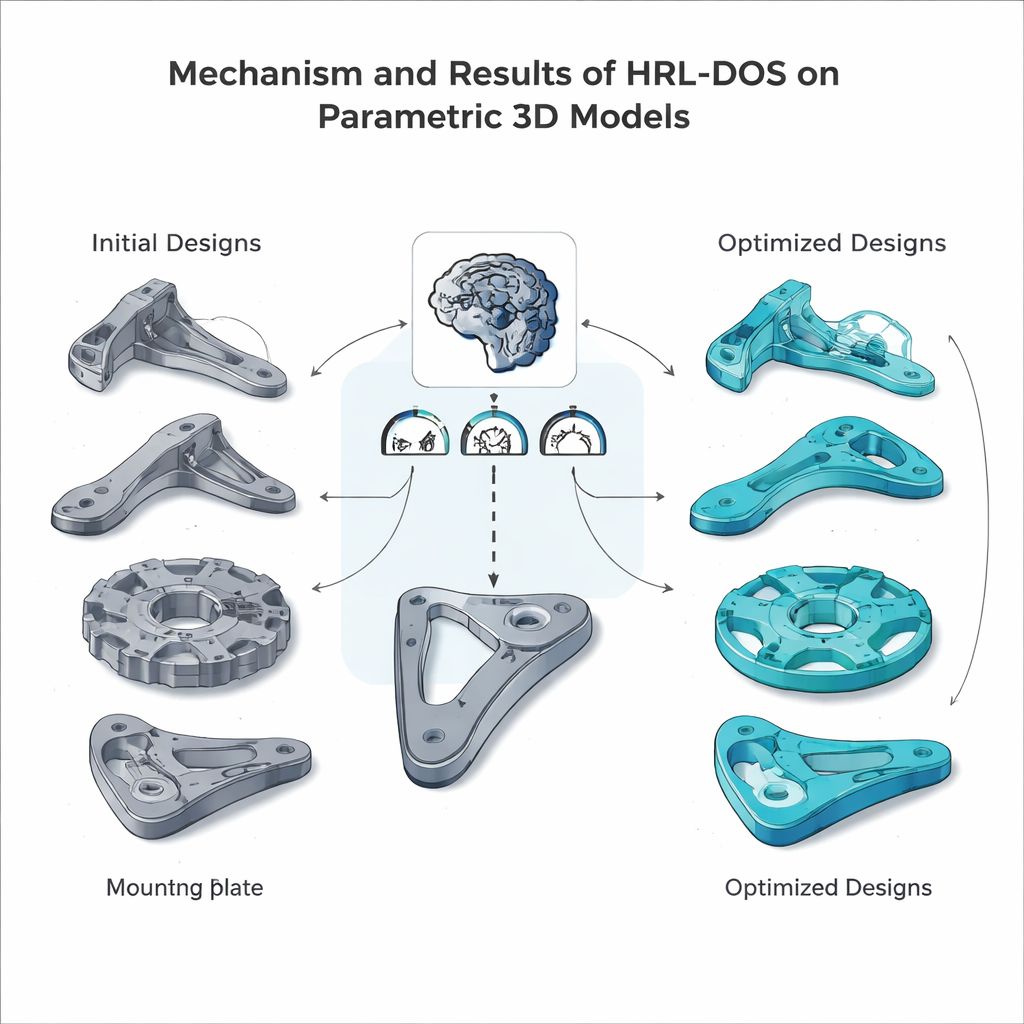
Binnen deze voorbereide omgeving doen de hiërarchische agenten herhaaldelijk nieuwe ontwerpsuggesties, voeren simulaties uit om gewicht en spanning te schatten, controleren produceerbaarheid en ontvangen een gecombineerde beloningsscore. In vele trainingsepisodes leert de high‑level agent welke strategische doelen vaak lonen, terwijl de low‑level agent ontdekt welke parameterwijzigingen die doelen daadwerkelijk opleveren. Het team testte HRL‑DOS op meerdere representatieve onderdelen uit de dataset — een geribde beugel, een tandwielschijf, een hefboomgreep en een montageplaat — en vergeleek de prestaties met verschillende geavanceerde alternatieven, waaronder platte reinforcement learning, hybride genetische algoritmen en andere AI‑geassisteerde ontwerp‑tools. HRL‑DOS bereikte goede oplossingen ongeveer 27% sneller en produceerde modellen met ruwweg 18% hogere totale kwaliteitscores.
Ontwerpen die sterk, maakbaar en flexibel zijn
Buiten de ruwe prestaties bleek HRL‑DOS beter in het binnen blijven van strikte engineeringlimieten. Het genereerde veel minder ontwerpen die veiligheids‑ of productielimieten overschreden en behaalde hogere produceerbaarheidsscores bij controles zoals overhanghoeken, interne holtes en toleranties. De methode generaliseerde ook goed naar nieuwe, niet eerder geziene onderdeeltypes en bleef robuust wanneer de invoergegevens ruisig of gedeeltelijk ontbraken — een belangrijke eigenschap voor werkwijzen in de echte wereld. Gezamenlijk suggereren deze resultaten dat hiërarchische reinforcement learning kan dienen als een praktische motor voor intelligent computerondersteund ontwerp, waarmee architecten en ingenieurs meer opties in minder tijd kunnen verkennen en tegelijkertijd hun modellen veilig, efficiënt en klaar voor fabricatie houden.
Bronvermelding: Zhong, G., Vijay, V.C. Reinforcement learning-driven dynamic optimization strategy for parametric design of 3D models. Sci Rep 16, 5041 (2026). https://doi.org/10.1038/s41598-026-35863-1
Trefwoorden: parametrisch 3D-ontwerp, reinforcement learning, ontwerpoptimalisatie, computerondersteund ontwerp, generatieve engineering