Clear Sky Science · nl
HEViTPose: richting hoge nauwkeurigheid en efficiënte 2D-menspose-schatting met gecascadeerde gegroepeerde ruimtelijke reductie-attentie
Computers leren lichaamstaal lezen
Van fitness-apps tot bestuurdersassistentiesystemen: veel technologieën vertrouwen tegenwoordig op het vermogen van een computer om te begrijpen hoe mensen bewegen. Deze vaardigheid, human pose estimation, houdt in dat de posities van lichaamsgewrichten—zoals schouders, knieën en enkels—in een afbeelding of video worden gevonden. De uitdaging is dit zowel nauwkeurig als snel genoeg te doen voor realtime gebruik op alledaagse hardware. Dit artikel introduceert HEViTPose, een nieuwe methode die hoge nauwkeurigheid wil behouden terwijl ze minder rekenkracht vereist dan veel huidige systemen.
Waarom het vinden van gewrichten in beelden zo moeilijk is
Op het eerste gezicht lijkt het lokaliseren van lichaamsgewrichten eenvoudig: zoek gewoon naar armen en benen. In de praktijk verschijnen mensen echter in verschillende groottes, in ongewone houdingen, in drukke scènes en vaak achter objecten zoals meubels of auto’s. Moderne pose-schattingssystemen lossen dit meestal op door voor elk gewricht een gedetailleerde “heatmap” te maken, waarbij heldere plekken waarschijnlijke posities aangeven. Heatmaps zijn zeer precies maar duur om te berekenen. Traditionele systemen vertrouwen voornamelijk op convolutionele neurale netwerken, die goed zijn in het herkennen van lokale patronen maar steeds dieper en zwaarder moeten worden om langeafstandsrelaties over het hele lichaam vast te leggen. Meer recente transformer-gebaseerde modellen blinken uit in het vastleggen van zulke langeafstandsverbanden, maar ze hebben vaak grote datasets en zware berekeningen nodig, wat hun inzetbaarheid in realtime of op kleinere apparaten bemoeilijkt.
Overlappende blikvangers voor vloeiendere waarneming
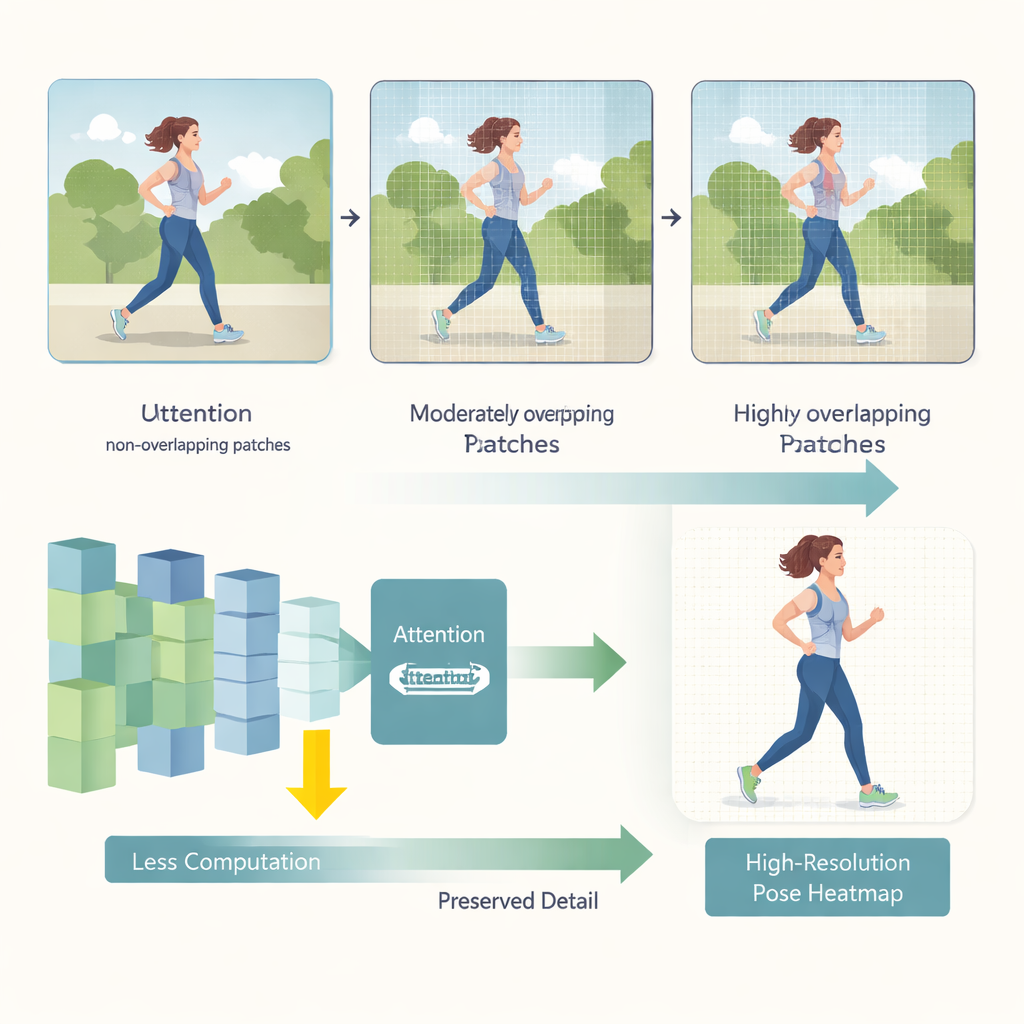
HEViTPose begint met het heroverwegen van hoe een afbeelding in stukjes wordt opgedeeld voor analyse. Eerdere transformer-modellen hakten beelden vaak in niet-overlappende tegels, wat de visuele continuïteit tussen aangrenzende regio’s kan verbreken—zoals het doorsnijden van iemands arm aan de rand van een patch. HEViTPose bouwt voort op het idee van overlappende patch-embedding en introduceert een helderdere, instelbare maat genaamd Patch Embedding Overlap Width (PEOW). PEOW telt eenvoudig hoeveel pixels aangrenzende tegels langs hun grenzen delen. Door deze overlap systematisch te variëren, laten de auteurs zien dat een matige overlap het netwerk beter in staat stelt de vloeiende verandering van kleur en vorm tussen tegels “aan te voelen”. Die rijkere lokale continuïteit leidt tot nauwkeurigere gewrichtsposities, zonder dat het model in omvang of rekencapaciteit explodeert.
Slimmere aandacht met minder werk
De tweede belangrijke innovatie is een nieuw attentieblok genaamd Cascaded Group Spatial Reduction Multi-Head Attention (CGSR-MHA). Attentiemechanismen vertellen het netwerk welke delen van de afbeelding elke voorspelling zouden moeten beïnvloeden, maar ze schalen doorgaans slecht naarmate afbeeldingen groter worden. CGSR-MHA pakt dit op drie manieren aan. Ten eerste splitst het kenmerken in groepen, zodat elke groep slechts een deel van de informatie verwerkt in plaats van alles tegelijk. Ten tweede verkleint het de ruimtelijke resolutie binnen elke groep voordat attentie wordt berekend, waardoor het aantal bewerkingen sterk wordt verminderd. Ten derde gebruikt het meerdere kleine attentiehoofdjes in plaats van een paar grote, waardoor diversiteit in waar het model op kan “richten” behouden blijft terwijl de kosten laag blijven. Zorgvuldig gekozen instellingen voor het aantal groepen, de mate van verkleinen en het aantal hoofden vinden een balans tussen snelheid en nauwkeurigheid.
Ultralichte modellen die toch meedoen aan de top
Om HEViTPose te testen, evalueren de auteurs het op twee veelgebruikte benchmarks: de MPII-dataset van alledaagse menselijke activiteiten en de grotere COCO-dataset met mensen in vele verschillende scènes. Over meerdere modelgroottes bereikt HEViTPose de nauwkeurigheid van toonaangevende pose-schattingssystemen of komt er dicht bij, terwijl het veel minder parameters en rekencapaciteit gebruikt. Zo bereikt een versie vergelijkbare nauwkeurigheid met een populair hogeresolutienetwerk (HRNet) terwijl het aantal geleerde parameters met meer dan 60% wordt verminderd en de hoeveelheid berekeningen met meer dan 40% daalt. Vergeleken met een ander modern hybride model dat convoluties en transformers combineert, levert HEViTPose vergelijkbare prestaties maar draait het ongeveer 2,6 keer sneller op een grafische processor. Deze besparingen vertalen zich direct naar vloeiendere realtimeprestaties en lagere hardware-eisen.
Wat dit betekent voor alledaagse toepassingen
In eenvoudige bewoordingen laat HEViTPose zien dat we niet hoeven te kiezen tussen nauwkeurigheid en efficiëntie bij het leren van computers om menselijke lichaamstaal te lezen. Door zorgvuldig de afbeeldingsdelen die het onderzoekt te laten overlappen en door te herontwerpen hoe attentie binnen het netwerk wordt berekend, kan het systeem gewrichten met hoge precisie lokaliseren terwijl het compact en snel blijft. Dit maakt het aantrekkelijk voor toepassingen in de echte wereld zoals sporttracking, videobewaking, mens-robotinteractie en monitoring in de auto, waar zowel snelheid als energieverbruik van belang zijn. De ideeën achter HEViTPose—slimmere overlap en efficiënte attentie—kunnen ook worden aangepast aan verwante taken zoals het volgen van dierlijke poses of gezichtslandmarkdetectie, wat mogelijk scherper “digitaal zicht” naar veel apparaten brengt zonder supercomputer-hardware.
Bronvermelding: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Trefwoorden: menspose-schatting, computer vision, vision transformer, efficiënt deep learning, attentiemechanisme