Clear Sky Science · nl
Een hybride CNN- en reinforcement-learningkader voor sprekeridentificatie met Mel-spectrogram- en continue wavelettransformatiekenmerken
Waarom uw stem een digitale sleutel kan zijn
Stelt u zich voor dat u uw bankrekening, voordeur of telefoon ontgrendelt met alleen uw stem. Om dat veilig te laten gebeuren, moeten computers betrouwbaar één persoon van een andere kunnen onderscheiden, zelfs bij achtergrondgeluid, emotie of een slechte microfoon. Dit artikel onderzoekt een nieuwe manier om machines te leren herkennen wie er spreekt, niet alleen wat er gezegd wordt, door moderne deep-learningtechnieken te combineren met een vorm van leer-van-proef-en-fout afkomstig uit de robotica.
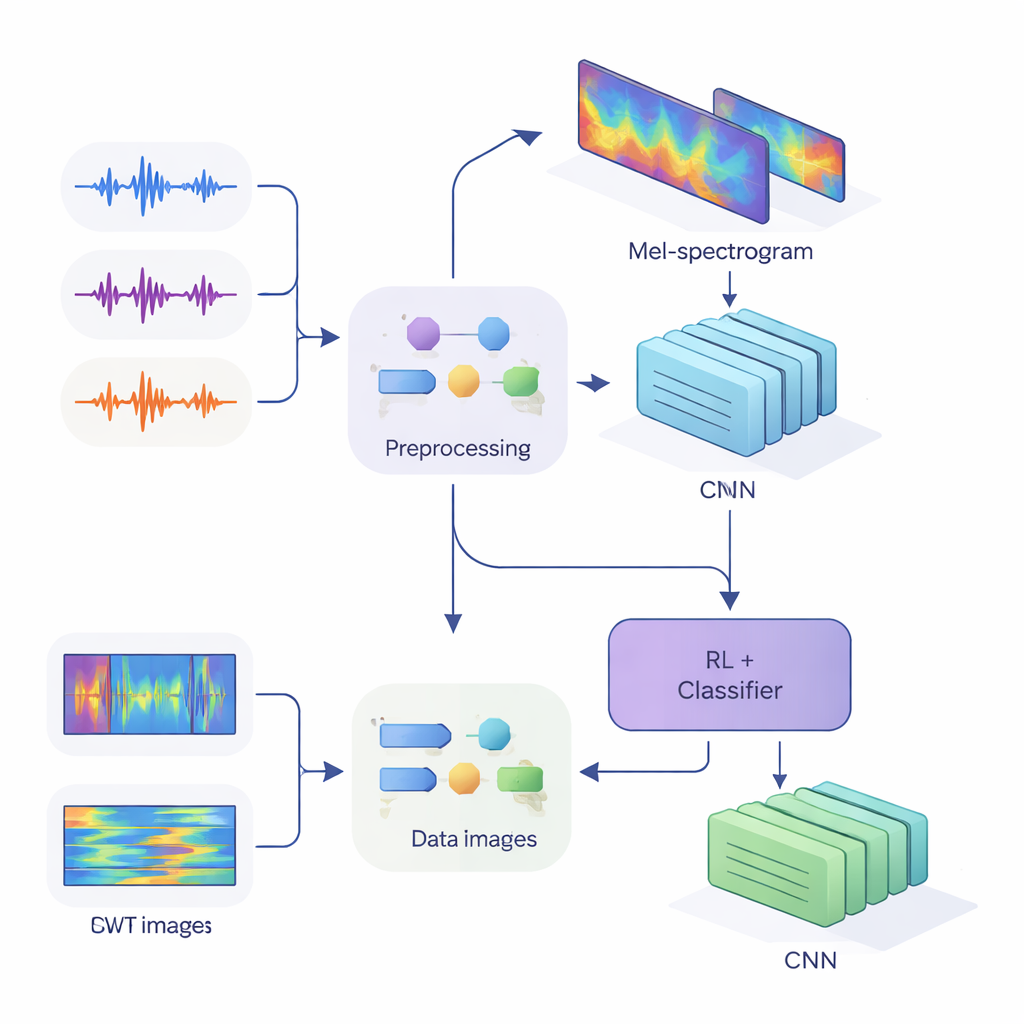
Van geluidsgolven naar stemvingerafdrukken
De stem van ieder mens bevat subtiele aanwijzingen die worden gevormd door de grootte en vorm van het vocale kanaal, hoe de stembanden trillen en iemands spreekstijl. De onderzoekers begonnen met de vraag: welke meetbare eigenschappen van opgenomen spraak verschillen daadwerkelijk tussen mensen? Met 2.703 audioclips van 40 Engelse sprekers uit de LibriSpeech-dataset analyseerden zij 22 eenvoudige akoestische kenmerken, zoals variatie in luidheid, energie in verschillende frequentiebanden, ritme, en een maat genaamd entropie die vastlegt hoe complex of onvoorspelbaar het geluid is. Statistische toetsen lieten zien dat 21 van deze 22 kenmerken sterke spreker-specifieke informatie bevatten, waarbij entropie en energie in hoge frequenties bijzonder onderscheidend waren. Met andere woorden: iemands “stemvingerafdruk” verspreidt zich over veel aspecten van het geluid, niet alleen toonhoogte of volume.
Twee manieren om geluid in beelden te veranderen
Om deze aanwijzingen aan moderne neurale netwerken te voeden, zette het team eendimensionale audio om in tweedimensionale afbeeldingen die vastleggen hoe energie over tijd en frequentie verandert. In de eerste methode gebruikten ze Mel-spectrogrammen, die nabootsen hoe het menselijk oor frequenties groepeert en standaard zijn in spraaktechnologie. In de tweede methode gebruikten ze continue wavelettransformaties, een flexibelere manier om zowel korte, scherpe geluiden als langere klinkers te onderzoeken. Na zorgvuldige schoonmaak van de audio—stiltes verwijderen, volumenormalisatie en het toevoegen van kleine vervormingen zoals ruis en toonhoogteverschuivingen om het systeem robuuster te maken—produceerden ze Mel-"afbeeldingen" van 80 bij 313 en wavelet-"afbeeldingen" van 128 bij 128, klaar voor verwerking door convolutionele neurale netwerken (CNNs).
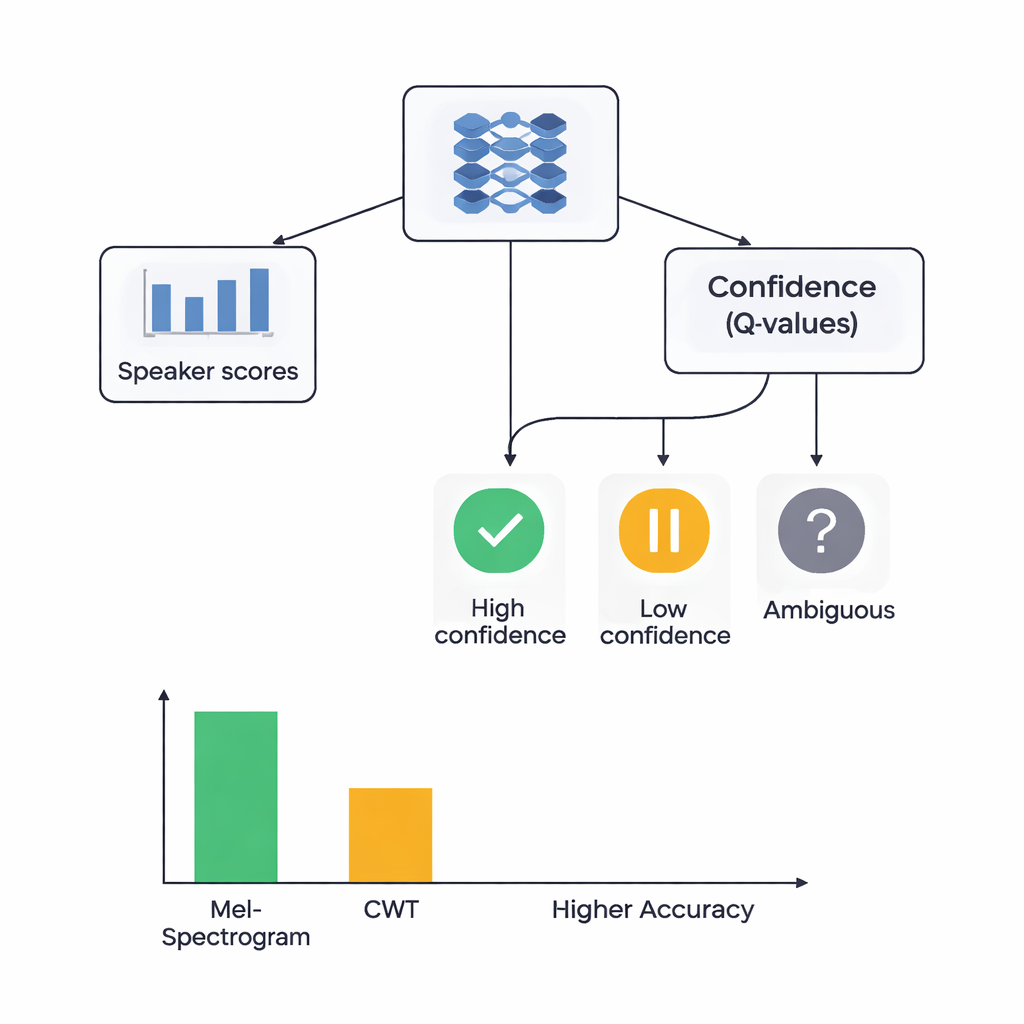
Netwerken leren luisteren en twijfelen
Het hart van de studie is een hybride architectuur die twee leerstijlen combineert. Eerst scannen CNNs de Mel- of wavelet-afbeeldingen om patronen te extraheren die typisch bij bepaalde sprekers horen, vergelijkbaar met hoe beeldherkenningsnetwerken leren ogen of randen te herkennen. Voor het Mel-gebaseerde systeem voegen de auteurs een self-attentionmodule toe die het netwerk in staat stelt zich te concentreren op de meest informatieve tijdsegmenten. Bovenop deze feature-extractors plaatsen ze een reinforcement-learning (RL) component die leert hoe zeker het systeem over elke beslissing moet zijn. In plaats van altijd een harde keuze te maken, kent het RL-gedeelte waarden toe aan acties zoals "dit als hoge zekerheid accepteren", "als lage zekerheid behandelen" of "als ambigu markeren". Over vele trainingsronden wordt het beloond wanneer zekere beslissingen correct zijn, waardoor het netwerk naar beter gekalibreerde oordelen wordt gestuurd.
Hoe goed werkt het hybride systeem?
De onderzoekers vergeleken vier modellen: Mel-gebaseerd met RL, Mel-gebaseerd zonder RL, wavelet-gebaseerd met RL en wavelet-gebaseerd zonder RL. Allen werden getest met zorgvuldige vijfvoudige cross-validatie, wat betekent dat elke audioclip in verschillende ronden zowel voor training als voor testen werd gebruikt. Het Mel-plus-RL-systeem presteerde het best, met ongeveer 88% correcte sprekeridentificatie en een bijna perfecte scheiding tussen sprekers volgens een standaardmaat voor discriminatieve kracht. Het wavelet-plus-RL-systeem behaalde ongeveer 78% nauwkeurigheid. Cruciaal is dat het toevoegen van de RL-component de prestaties voor beide featuretypes met ongeveer 3 procentpunt verbeterde en de resultaten consistenter maakte over verschillende datasplitsingen. Meer sprekerklassen bereikten hoogwaardige herkenning wanneer RL was opgenomen, wat suggereert dat de zekerheid-gevoelige beslissingen vooral hielpen bij moeilijke, gemakkelijk te verwarren stemmen.
Wat dit betekent voor dagelijkse spraakbeveiliging
Voor niet-specialisten is de belangrijkste conclusie dat betrouwbare op stem gebaseerde identiteitscontroles zowel rijke representaties van het geluid als een gezonde mate van twijfel van de machine vereisen. Dit werk laat zien dat oor-geïnspireerde Mel-spectrogrammen, gecombineerd met attention en een reinforcement-learner die kan zeggen "ik weet het niet zeker", beter presteren dan meer exotische wavelet-afbeeldingen voor de taak van sprekeronderscheiding. Hoewel de studie een relatief kleine, schone dataset gebruikt en nog niet is afgestemd op lawaaierige, realistische omstandigheden, toont het aan dat het toevoegen van een zekerheid-gevoelige laag bovenop diepe neurale netwerken spraakauthenticatie zowel nauwkeuriger als betrouwbaarder kan maken—een belangrijke stap als onze stemmen veilige digitale sleutels moeten worden.
Bronvermelding: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Trefwoorden: sprekeridentificatie, spraakbiometrie, deep learning, reinforcement learning, Mel-spectrogrammen