Clear Sky Science · nl
Een algemeen kader voor adaptieve niet‑parametrische dimensiereductie
Waarom het verkleinen van big data ertoe doet
Het moderne leven draait om data: medische scans, online aankoopgeschiedenissen, foto’s, nieuwsfeeds en meer. Elk record kan honderden of duizenden metingen bevatten, waardoor het moeilijk is om ze op te slaan, te analyseren of zelfs te visualiseren. Wetenschappers gebruiken “dimensiereductie” om deze complexiteit samen te persen tot eenvoudigere beelden en modellen, terwijl ze de belangrijke patronen behouden. Maar de huidige populaire hulpmiddelen vereisen vaak veel handmatige keuzes en proberen‑en‑fouten‑afstemming. Dit artikel presenteert een manier om de data zelf te laten bepalen hoe ze het beste verkleind kunnen worden, met als doel duidelijkere beelden, nauwkeuriger leren en minder giswerk voor de gebruiker.
Van eenvoudige lijnen naar gekromde werkelijkheden
Een klassieke techniek om data te vereenvoudigen, Principal Component Analysis, werkt als het schijnen van licht op een object en het bekijken van de schaduw: het vindt de beste vlakke richtingen die het grootste deel van de variatie verklaren. Dit is krachtig wanneer de structuur van de data ruwweg recht of vlak is. Maar echte data — zoals afbeeldingen, teksten of sensormetingen — liggen vaak op gekromde oppervlakken die verborgen liggen in hoogdimensionale ruimte. In de afgelopen twee decennia zijn nieuwe “niet‑lineaire” methoden zoals Isomap, Locally Linear Embedding (LLE), spectrale embedding en UMAP ontworpen om deze kronkelende vormen bloot te leggen. Ze vertrouwen op lokale buurten: voor elk punt kijken ze naar de dichtstbijzijnde buren en proberen die kleinschalige relaties te behouden bij het tekenen van een lager‑dimensionaal beeld. Deze methoden dwingen de gebruiker echter twee belangrijke knoppen te kiezen: hoeveel buren te gebruiken en op hoeveel dimensies te projecteren. Een slechte keuze kan leiden tot misleidende resultaten of hoge rekenkosten.
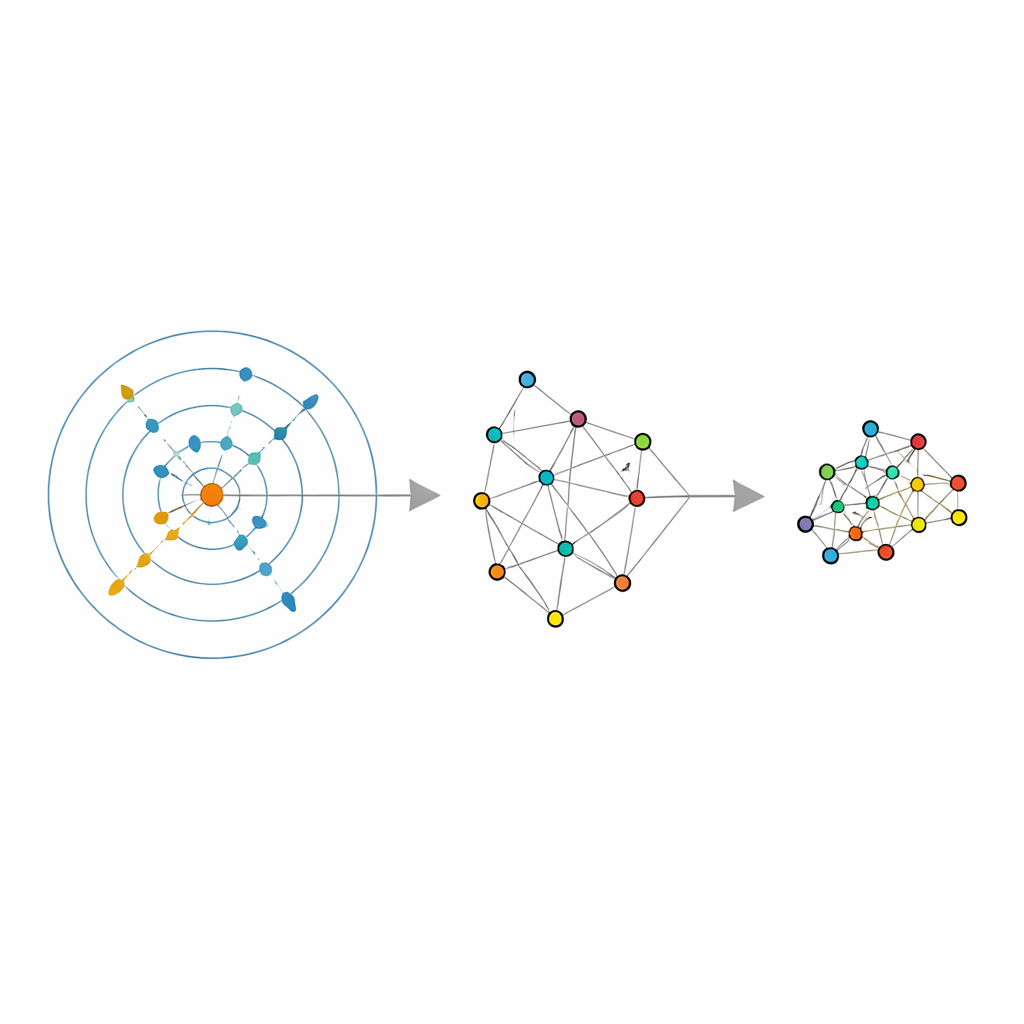
De data hun eigen buurt laten kiezen
De auteurs bouwen voort op een recent statistisch hulpmiddel dat een schatter voor de intrinsieke dimensie heet en dat probeert een eenvoudige vraag te beantwoorden: in hoeveel onafhankelijke richtingen varieert de data werkelijk, zodra ruis is verwijderd? Hun schatter, ABIDE genoemd, gaat verder. Rond elk punt zoekt hij automatisch naar een buurt die redelijk uniform lijkt — niet te klein en lawaaierig, maar ook niet te groot en vervormd. Daarbij levert hij twee informatiestukken op: een globale schatting van de werkelijke dimensie van de data en een op maat gemaakte buurtgrootte voor elk punt. Dit verandert het gebruikelijke vaste “aantal buren” in een lokaal adaptieve grootheid die kan groeien in dunbevolkte regio’s en krimpen in drukke, en zo past bij de werkelijke dichtheid van de data.
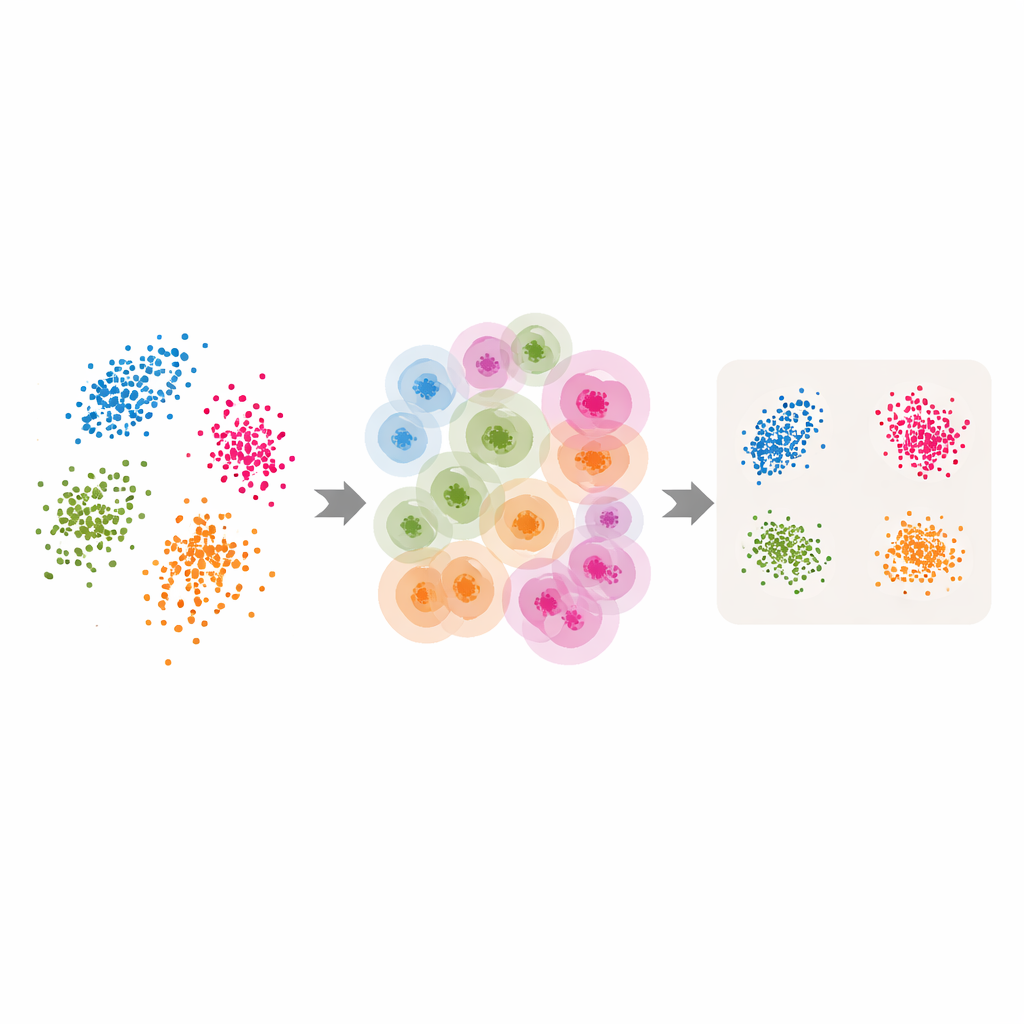
Klassieke hulpmiddelen adaptief maken
Gewapend met deze adaptieve buurten en de geschatte intrinsieke dimensie, passen de auteurs verschillende populaire methoden voor dimensiereductie en clustering aan. Voor LLE vervangen ze het enkele, door de gebruiker gekozen aantal buren door de per‑punt waarden die ABIDE teruggeeft, en ze stellen de doeldimensie gelijk aan de geschatte intrinsieke dimensie. Het algoritme leert vervolgens hoe elk punt te reconstrueren uit een zorgvuldig gekozen lokale groep voordat het een globale laag‑dimensionale ordening vindt die deze lokale reconstructies het beste behoudt. Vergelijkbare ideeën worden toegepast op spectrale clustering — waarbij een graaf van overeenkomsten tussen punten wordt gebruikt voor groepering — en op UMAP, dat een vage kaart bouwt van hoe punten met elkaar verbonden zijn. In elk geval wordt de rigide buurtgrootte ingewisseld voor een flexibele, door de data aangestuurde structuur die de natuurlijke geometrie van de data volgt.
Testen op bloemen, cijfers, tekst en synthetische vormen
Om te zien of deze adaptieve aanpak rendeert, voeren de auteurs experimenten uit op verschillende benchmarks: de klassieke Iris‑bloemmetingen, handgeschreven cijferafbeeldingen (MNIST), nieuwsartikelen voorgesteld door taalmodel‑embeddings, en synthetische driedimensionale vormen met toegevoegde ruis. Ze vergelijken de adaptieve versies met standaardsoftware‑instellingen en met zorgvuldig afgestelde roosterzoektochten van hyperparameters. In unsupervised taken zoals clustering en visualisatie leveren de adaptieve methoden doorgaans duidelijkere clusters, strakkere groepsvorming en betere scores op gangbare kwaliteitsmaten. Bijvoorbeeld, op complexe manifolds met ongelijke puntdichtheid herstellen de adaptieve methoden de ware structuur veel beter dan versies met vaste buren. In supervised tests, waar de gereduceerde data aan een classifier worden gevoerd, doet de adaptieve aanpak het wederom even goed of beter dan de beste vaste instellingen, zonder uitputtende afstemming.
Wat dit betekent voor alledaagse data‑analyse
Voor niet‑experts en beoefenaars is de hoofdboodschap dat het verkleinen van data niet op giswerk hoeft te berusten. Door de eigen geometrie van de data te gebruiken om te beslissen “hoeveel buren” en “hoeveel dimensies”, verandert dit kader veelgebruikte hulpmiddelen zoals LLE, spectrale clustering en UMAP in slimmer, robuuster gereedschap. Het resultaat zijn betrouwbaardere laag‑dimensionale weergaven — grafieken en features die de werkelijke vorm van de data beter weerspiegelen — terwijl vaak ook de tijd voor handmatig zoeken naar hyperparameters afneemt. In praktische termen betekent dit dat taken zoals het visualiseren van grote afbeeldingsverzamelingen, het groeperen van documenten of het voorbereiden van invoer voor voorspellende modellen zowel eenvoudiger als betrouwbaarder kunnen worden, simpelweg door de data adaptief te laten bepalen hoe ze gecomprimeerd wordt.
Bronvermelding: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Trefwoorden: dimensiereductie, manifold‑leren, nabijste buren, intrinsieke dimensie, datavisualisatie