Clear Sky Science · nl
Verbeterde gegeneraliseerde normaleverdelingsoptimizer met Gaussiaanse herstelmethode en Cauchy omgekeerd leren voor featureselectie
Waarom het kiezen van de juiste gegevens ertoe doet
Het moderne leven draait op data, van medische scans en bankgegevens tot socialmediastromen. Meer data is echter niet altijd beter. Wanneer computers tegelijkertijd uit duizenden ruwe metingen moeten leren, kunnen ze trager worden, duurder in gebruik en verrassend minder nauwkeurig. Dit artikel presenteert een slimere manier om al die metingen te doorzoeken en alleen die te behouden die echt van belang zijn, met een nieuw algoritme dat Binary Adaptive Generalized Normal Distribution Optimizer of BAGNDO heet.
Het probleem van te veel aanwijzingen
Stel je voor dat je een ziekte probeert te diagnosticeren met honderden laboratoriumtests, scans en vragenlijstantwoorden. Veel van deze “features” kunnen ruis bevatten, overbodig zijn of simpelweg irrelevant, en ze allemaal in een classifier voeren kan eerder verwarren dan helpen. Featureselectie heeft tot doel een kleinere, informatievere subset van invoer te kiezen zodat machine-learningmodellen sneller, goedkoper en betrouwbaarder worden. Eenvoudige statistische filters kunnen duidelijk onbruikbare kenmerken verwijderen, maar ze stemmen hun keuzes niet af op het gebruikte model en missen vaak subtiele combinaties van variabelen. Geavanceerdere “wrapper”-methoden beoordelen featuresets door direct te testen hoe goed een classifier presteert, maar dat creëert een enorm zoekprobleem: het aantal mogelijke subsets explodeert naarmate het aantal features toeneemt.
Slim zoeken in plaats van blind
Om met deze explosie om te gaan, vertrouwen onderzoekers op metaheuristische algoritmen — zoekstrategieën geïnspireerd op natuurlijke of fysieke processen die brede verkenning in balans brengen met gerichte verfijning. Een dergelijke methode, de Generalized Normal Distribution Optimizer (GNDO), behandelt kandidaat-oplossingen alsof ze uit een flexibele klokvormige verdeling komen en verschuift deze verdeling geleidelijk naar betere oplossingen. GNDO heeft goed gewerkt in engineering- en energie-toepassingen, maar heeft de neiging te vroeg vast te lopen op louter redelijke oplossingen en worstelt met het in balans brengen van globale verkenning en lokale fijnregeling bij toepassing op featureselectie. De auteurs zien dit als een kritisch knelpunt: de elegante wiskunde van GNDO vertaalt zich niet automatisch in sterke prestaties bij hoog-dimensionale ja/nee-beslissingen over welke features te behouden.
Een driedelige upgrade voor een klassieke motor
Het voorgestelde BAGNDO-kader verbetert GNDO met drie gecoördineerde ideeën. Ten eerste genereert een Adaptive Cauchy Reverse Learning-strategie regelmatig “spiegel”versies van huidige oplossingen met behulp van een heavy-tailed kansverdeling. Dit stimuleert gedurfde sprongen naar ongekende gebieden van de zoekruimte en voorkomt dat het algoritme vastloopt in lokale kuilen. Ten tweede houdt een Elite Pool-strategie niet slechts één beste oplossing bij, maar een kleine groep toppresteerders plus een geblend "gids"-kandidaat. Deze rijkere leiderschapsgroep helpt diversiteit te behouden terwijl de zoektocht toch naar veelbelovende regio’s wordt gestuurd. Ten derde bekijkt een op Gaussiaanse verdeling gebaseerde worst-solution repair-methode de zwakste kandidaten en duwt deze in de richting van patronen die van de elitegroep zijn geleerd, waardoor slechte oplossingen effectief worden gerecycled tot betere in plaats van volledig te worden verworpen.
De methode aan de tand voelen
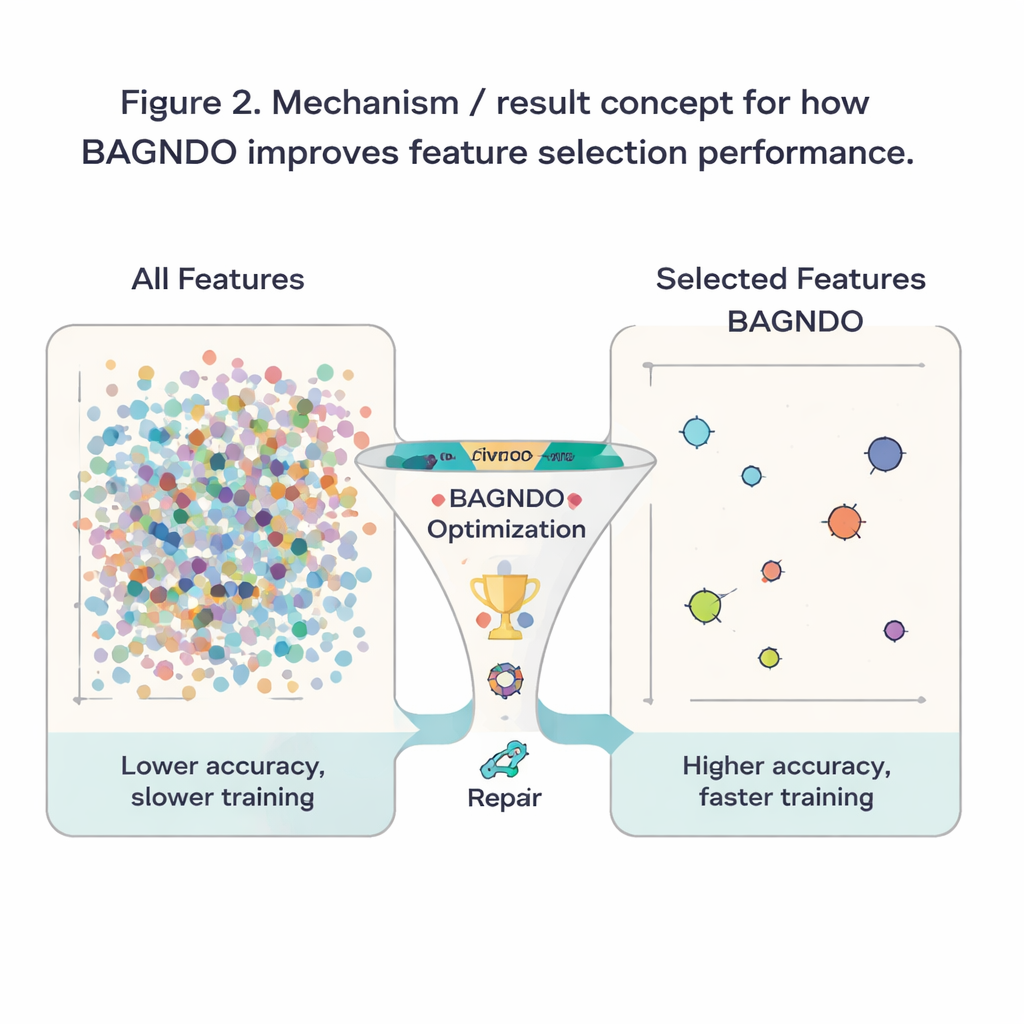
Om te onderzoeken of deze ideeën in de praktijk helpen, pasten de auteurs BAGNDO toe op 18 bekende benchmarkdatasets uit de UCI-repository, variërend van medische diagnoses en spellen tot signalen en meer. In elk geval zocht het algoritme naar een subset van features die een standaard k-nearest neighbors-classifier in staat stelde nauwkeurige voorspellingen te doen. BAGNDO werd vergeleken met negen sterke concurrenten, waaronder particle swarm-optimisatie, genetisch georiënteerde methoden en verschillende moderne zwerm-geïnspireerde algoritmen. Over deze tests vond BAGNDO consequent kleinere feature-sets terwijl het de voorspellingsnauwkeurigheid behield of vaak verbeterde. Het behaalde de beste nauwkeurigheid met de meest compacte feature-subsets in 14 van de 18 datasets, en statistische toetsen bevestigden dat deze verbeteringen niet door toeval verklaard konden worden.
Wat dit betekent voor alledaags machinaal leren
Voor de niet-specialist is de uitkomst eenvoudig samen te vatten: de auteurs hebben een meer gedisciplineerde “featurekiezer” gebouwd die leeralgoritmen helpt zich te concentreren op wat echt belangrijk is in een dataset. Door beter te jongleren met brede verkenning, elite-geleiding en herstel van zwakke kandidaten, snoeit BAGNDO onnodige invoer weg terwijl de nauwkeurigheid behouden blijft of toeneemt. Dit betekent snellere modellen, minder opslag- en rekenkosten en vaak duidelijkere inzichten in welke metingen of vragen het meest informatief zijn. Hoewel de methode computationeel zwaarder is dan sommige eenvoudigere alternatieven, biedt het een krachtig instrument voor problemen waar nauwkeurigheid en interpreteerbaarheid vooropstaan, van medische beslissingsondersteuning tot industriële monitoring en verder.
Bronvermelding: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Trefwoorden: featureselectie, metaheuristische optimalisatie, machinaal leren, dimensionaliteitsreductie, classificatieaccuratesse