Clear Sky Science · nl
Quantum-kernelmethoden voor marketinganalyse met convergentietheorie en scheidingsgrenzen
Waarom slimme klantvoorspellingen ertoe doen
Bedrijven vertrouwen in toenemende mate op data om te bepalen welke klanten ze moeten benaderen met aanbiedingen, ondersteuning of retentiecampagnes. Maar naarmate de gegevens complexer worden, kunnen traditionele hulpmiddelen moeite hebben om subtiele patronen te herkennen—en elke gemiste klant met hoge waarde kan duur uitpakken. Dit artikel onderzoekt of opkomende quantumcomputers—machines die werken volgens de wetten van de kwantumfysica—deze voorspellingen voor marketingachtige problemen kunnen verscherpen, en doet dat met oog voor de huidige imperfecte, "noisy" hardware.

Van klantgegevens naar quantumcircuits
De auteurs richten zich op een praktische taak die zij consumentclassificatie noemen: voorspellen welke gebruikers met een digitale dienst zullen omgaan of deze zullen adopteren. Elke gebruiker wordt beschreven door een kleine set numerieke kenmerken, zoals demografische gegevens en gedrag op een platform. In plaats van deze gegevens direct in een standaardalgoritme te stoppen, coderen ze ze eerst in de toestanden van enkele qubits met een compact quantumcircuit. Dit circuit fungeert als een kenmerktransformatie, en herschikt de gegevens in een vorm die mogelijk gemakkelijker in twee groepen te scheiden is—"waarschijnlijk geïnteresseerd" en "waarschijnlijk niet geïnteresseerd." Bovenop deze quantumtransformatie gebruiken ze een bekende classificatiemethode, de support vector machine, in een quantumgeïnspireerde versie die een quantum-kernel SVM (Q-SVM) wordt genoemd.
Quantumideeën testen onder realistische condities
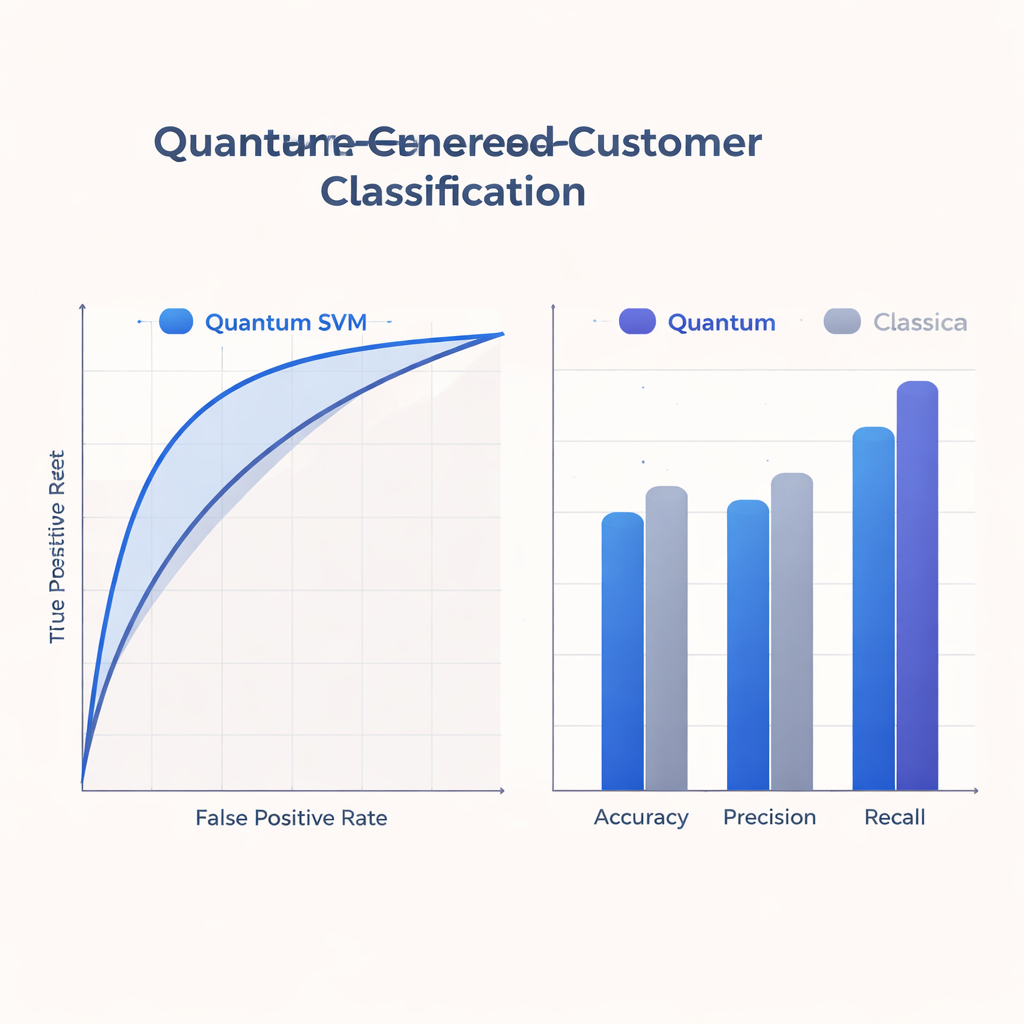
Aangezien de huidige quantumapparaten klein en foutgevoelig zijn, houden de auteurs het bij ondiepe circuits die overeenkomen met wat hardware op korte termijn aankan. Het team traint en evalueert hun Q-SVM op een echte, geanonimiseerde dataset van ongeveer 500 trainings- en 125 testgevallen met acht kenmerken per gebruiker, en simuleert zowel ideaal als ruisachtig quantumgedrag. Ze vergelijken de quantumaanpak met sterke klassieke referentiemodellen die populaire kerneltrucs op standaardcomputers gebruiken. Over nauwkeurigheid, precisie, recall en de oppervlakte onder de ROC-curve (een samenvatting van de afwegingen tussen het vinden van positieven en het vermijden van valse alarmen) levert de Q-SVM concurrerende of betere prestaties, met name op het gebied van recall: hij identificeert een hoger aandeel daadwerkelijk geïnteresseerde gebruikers dan de klassieke modellen.
Theoretische garanties achter de schermen
Naast ruwe prestaties stelt het artikel een diepere vraag: wanneer mogen we überhaupt verwachten dat quantummethoden helpen? De auteurs ontwikkelen drie hoofdtheoretische resultaten. Ten eerste tonen ze aan dat, als het leerprobleem aan bepaalde gladheidscondities voldoet en de quantumcircuits ondiep blijven, het trainingsproces voor quantumkernels betrouwbaar zou moeten convergeren in een redelijk aantal stappen. Ten tweede geven ze scheidingsgrenzen die suggereren dat hun quantumkenmerkextractie, onder specifieke aannames, de kloof tussen de twee klantklassen kan vergroten vergeleken met klassieke transformaties—waardoor het probleem in essentie gemakkelijker oplosbaar wordt. Ten derde analyseren ze hoe benaderingsmethoden de kosten van het werken met grote quantumafgeleide kenruimten drastisch kunnen verlagen, zodat de aanpak rekenkundig haalbaar blijft.
Wat dit voor marketeers kan betekenen
Voor marketing- en klantanalyseteams ligt de meest concrete winst in hoe het quantummodel gemiste kansen afweegt tegen verspilde benaderingen. De hogere recall van de Q-SVM betekent dat het minder waarschijnlijk is dat gebruikers worden over het hoofd gezien die positief op een aanbieding zouden reageren, een belangrijk voordeel in retentie- of proactieve servicecampagnes. Tegelijkertijd blijven precisie en algehele nauwkeurigheid in een bereik vergelijkbaar met sterke klassieke referenties, ondersteund door een robuuste ROC-curve. Omdat de methode goed werkt over een reeks beslissingsdrempels, kunnen teams instellen hoe agressief of terughoudend ze willen zijn—met de nadruk op recall of precisie—zonder het model telkens opnieuw te hoeven trainen.
Een veelbelovende start, geen quantumrevolutie (nog niet)
De auteurs benadrukken dat hun bevindingen vroege stappen zijn, geen bewijs van verreikende quantumoverheersing. De resultaten komen uit simulaties op één dataset, niet uit grootschalige hardwareruns of vele verschillende markten. Hun wiskundige garanties berusten ook op geïdealiseerde aannames die mogelijk niet volledig opgaan op ruisachtige apparaten. Toch laat het werk zien dat zorgvuldig ontworpen quantumkernels al kunnen wedijveren met of licht beter kunnen presteren dan goede klassieke methoden op een realistische consumententaak, terwijl ze een duidelijk pad naar grotere voordelen bieden naarmate quantumhardware opschaalt. De conclusie voor lezers is dat quantum machine learning zich beweegt van abstracte belofte naar gereedschappen die op termijn klantvoorspellingen in zakelijke praktijken nauwkeuriger en flexibeler zouden kunnen maken.
Bronvermelding: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
Trefwoorden: quantum machine learning, marketinganalyse, klantclassificatie, support vector machines, quantumkernels