Clear Sky Science · nl
Fusie van infrarood- en zichtbaar beeld via visuele verbetering en semantische koppeling
Scherpere visie van dag- en nachtcamera’s
Moderne auto’s, drones en beveiligingssystemen hebben vaak twee soorten ‘ogen’: een gewone camera die kleur en textuur vastlegt en een infraroodcamera die warmte waarneemt. Beide hebben sterke en zwakke punten, en ze combineren tot een enkele heldere afbeelding blijkt verrassend moeilijk. Dit artikel presenteert een nieuwe manier om deze twee gezichtspunten samen te voegen tot één beeld dat niet alleen prettiger is om naar te kijken, maar ook gemakkelijker te verwerken is voor computersystemen.
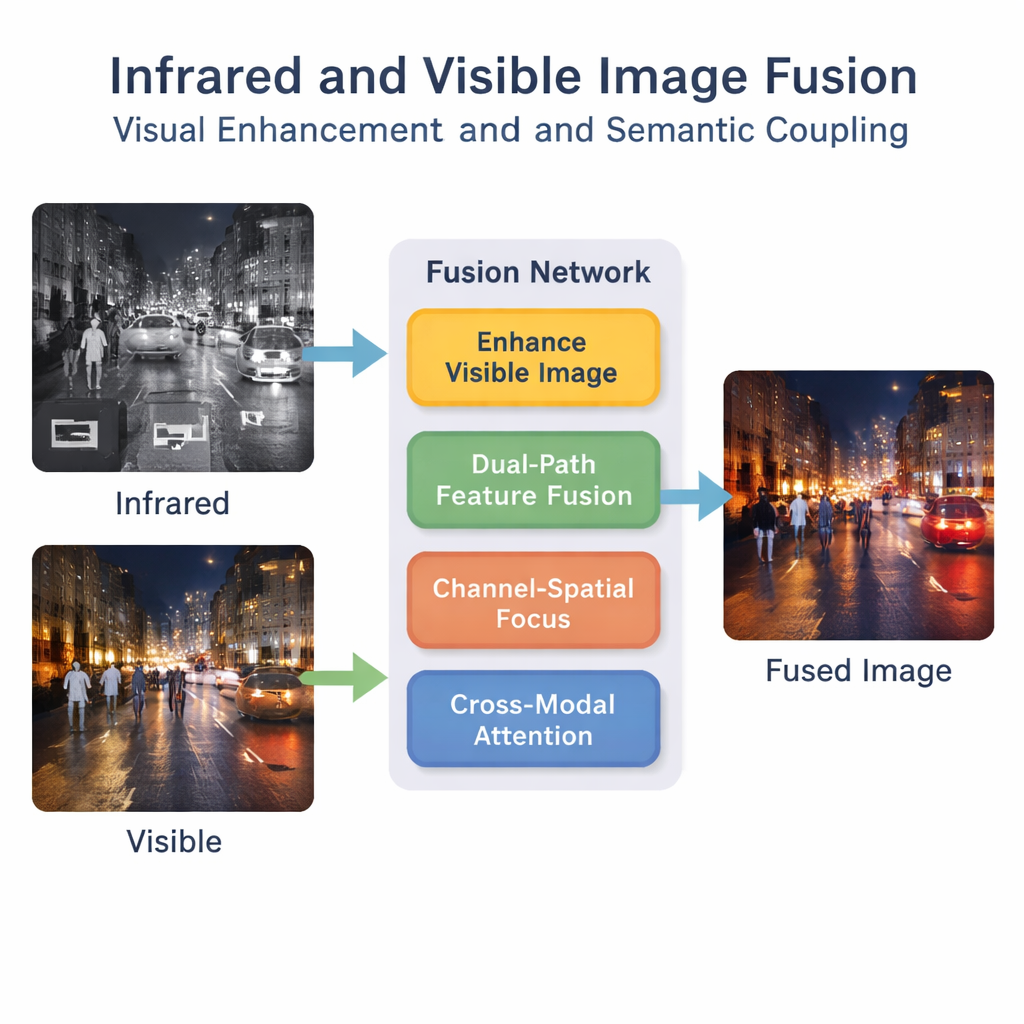
Waarom twee ogen beter zijn dan één
Camera’s voor zichtbaar licht leggen scherpe details vast zoals wegmarkeringen, gebouwranden en kleding, maar ze hebben moeite ’s nachts, bij mist of wanneer objecten in de achtergrond opgaan. Infraroodcamera’s doen het omgekeerde: ze accentueren warme objecten zoals mensen en voertuigen, zelfs in het donker, maar hun beelden zijn vaak onscherp en missen fijne details. Het samensmelten van deze twee beelden tot een ‘het beste van beide werelden’-afbeelding kan helpen bij taken variërend van voetgangersdetectie in rijhulpsystemen tot bewaking en zoek- en reddingsacties. Veel bestaande fusie-methoden concentreren zich echter alleen op oppervlakkige kenmerken — felle vlekken uit infrarood en texturen uit zichtbare beelden — en negeren het diepere, scene-niveau betekenis dat van belang is voor intelligente systemen.
Een slimmer manier om beelden te mengen
De auteurs stellen een deep-learningraamwerk voor dat fusie ziet als meer dan een simpele overlay. Eerst zorgt een speciale verbeteringsstap ervoor dat het zichtbare beeld wordt opgehelderd en gebalanceerd, vooral in zwak licht, zodat waardevolle details niet verloren gaan voordat de fusie begint. Daarna verwerkt een dual-path netwerk zowel infrarood- als zichtbare input parallel. Het ene pad concentreert zich op lokale patronen zoals randen en texturen, terwijl het andere pad naar de bredere context van de scène kijkt. Door deze paden te combineren produceert het systeem een rijkere interne beschrijving van wat er in de beelden gebeurt.
Het netwerk leren waar het op moet letten
Het is niet genoeg om simpelweg veel kenmerken te extraheren; het netwerk moet leren welke belangrijk zijn. Een “kanaal–ruimtelijk” module helpt het model om cruciale gebieden en typen informatie te benadrukken, zoals voetgangers of felle koplampen, terwijl minder nuttige achtergrondruis wordt onderdrukt. Daarbovenop stimuleert een bimodale interactieve aandachtsmechanisme de infrarood- en zichtbare stromen om met elkaar te communiceren. Het leert hoe warmtesignaturen en visuele texturen over de scène op elkaar aansluiten, en legt hogere concepten vast zoals “die felle vlek in het infrarood correspondeert met die persoon in het zichtbare beeld.” Deze semantische koppeling helpt ervoor te zorgen dat het gefuseerde beeld logisch consistent blijft in plaats van slechts visueel gemengd.

De methode op de proef gesteld
Om te controleren of de gefuseerde beelden niet alleen aantrekkelijk maar ook realistisch zijn, voegen de auteurs een discriminator-netwerk toe vergelijkbaar met die in generative adversarial networks. Dit extra netwerk leert echte zichtbare beelden te onderscheiden van gefuseerde, waardoor het fusieproces wordt aangespoord output te produceren die natuurlijk oogt voor zowel mensen als machines. De methode is getraind en getest op drie uitdagende verzamelingen van infrarood–zichtbare beeldparen, met dag- en nachtroutes en militair-achtige scènes. Over een reeks standaard kwaliteitsmetingen presteert de nieuwe aanpak over het algemeen beter dan tien bestaande fusiemethodes en levert beelden op met scherpere randen, beter contrast en meer informatieve inhoud.
Betere beelden voor veiligere systemen
Naast visuele kwaliteit stellen de auteurs een praktische vraag: helpen deze gefuseerde beelden computers betere beslissingen te nemen? Met een populair objectdetectiesysteem om voetgangers te vinden, tonen zij aan dat hun gefuseerde beelden de detectie-accuratesse verbeteren vergeleken met zowel enkel-sensor beelden als eerdere fusiemethoden. In gewone bewoordingen creëert de techniek beelden die gemakkelijker te interpreteren zijn voor zowel mensen als algoritmen, vooral onder moeilijke omstandigheden zoals nachtelijk verkeer. Hoewel het systeem nog afstemming nodig heeft voor realtime gebruik op apparaten met beperkte middelen, biedt het een veelbelovende stap naar veiligere, betrouwbaardere visie in geautomatiseerde voertuigen, bewaking en andere technologieën die duidelijk moeten zien wanneer het er echt toe doet.
Bronvermelding: Yang, Y., Li, Y., Li, J. et al. Infrared and visible image fusion via visual enhancement and semantic coupling. Sci Rep 16, 5666 (2026). https://doi.org/10.1038/s41598-026-35763-4
Trefwoorden: beeldfusie, infraroodbeeldvorming, zwaklichtvisie, deep learning, objectdetectie