Clear Sky Science · nl
Akoestische wachter: hiërarchische classificatie van voetstapsgeluid met fijne en grove akoestische kenmerkrepresentaties voor tactische bewaking
Luisteren naar verborgen voetstappen
Stel je voor dat je mensen kunt detecteren die door een donker bos lopen of langs een afgelegen grens zonder een enkele camera in zicht—alleen door naar hun voetstappen te luisteren. Deze studie onderzoekt hoe subtiele geluiden die bij lopen ontstaan kunnen worden omgevormd tot een krachtig vroegwaarschuwingsinstrument voor militairen, politie en onderzoekers, vooral op plekken waar camera’s falen of stroom schaars is.
Waarom camera’s niet voldoende zijn
Moderne beveiliging leunt vaak op videobewaking, maar camera’s hebben duidelijke beperkingen: ze hebben een directe zichtlijn nodig, verbruiken veel stroom en zijn moeilijk snel te plaatsen in ruig of vijandig terrein. Mobiele controleposten, grenspatrouilles en antiterrorisme-eenheden opereren vaak ’s nachts, onder dichte begroeiing of in bergachtige gebieden waar het installeren en onderhouden van cameranetwerken onpraktisch is. In die situaties wordt geluid een aantrekkelijk alternatief. Microfoons zijn lichtgewicht, goedkoper qua energie en kunnen “om hoeken heen luisteren”, waardoor ze mensen detecteren voordat ze zichtbaar zijn. Voetstappen zijn, hoewel relatief zacht, vaak goed hoorbaar in tactische omgevingen met weinig achtergrondgeluid, wat ze tot een veelbelovend signaal maakt voor vroegtijdige waarschuwing en forensische reconstructie van gebeurtenissen.
Een voetstappenbibliotheek uit de echte wereld opbouwen
Om dit idee om te zetten in een werkend systeem moesten de onderzoekers eerst een basisprobleem oplossen: er bestond geen geschikte verzameling voetstapopnames uit de echte wereld. Bestaande geluidsdatabases bevatten een paar voetstappen, hoofdzakelijk voor algemene geluidsherkenning of identiteitsvergelijking, vaak opgenomen onder gecontroleerde laboratoriumomstandigheden. Ze geven meestal niet aan of het geluid in een bos, op een weg of binnen is opgenomen, noch of het door één persoon of meerdere personen is gemaakt. Het team creëerde daarom een nieuwe bron genaamd de EWFootstep 1.0-dataset. Deze bevat 1.650 audioclips van 176 vrijwilligers die natuurlijk liepen over bossen, wegen en binnenruimtes in drie verschillende regio’s van India. De opnames vangen een mix van zachte en harde zolen, verschillende terreinen en realistische veldcondities zoals ongelijke microfoonplaatsing. Elke clip bevat minstens 15 voetstappen en is gelabeld zowel naar type omgeving als naar of het één persoon of een groep betreft.
Een machine leren luisteren als een verkenner
Met deze dataset ontwierpen de auteurs een luisteringssysteem dat nabootst hoe een ervaren verkenner over geluid zou redeneren. In plaats van alle taken gelijk te behandelen, beslist hun “hiërarchische multi-task” model eerst waar het geluid plaatsvindt—bos, weg of binnen—en schat vervolgens, met die context, of het om één persoon of meer dan één persoon gaat. De audio wordt omgezet in kleurrijke spectrogrammen die tonen hoe energie over frequenties in de tijd is verdeeld. Een reeks convolutionele lagen haalt fijne details naar voren die gekoppeld zijn aan ondergronden en schoeisel, zoals het kraken van bladeren of het dreunen van laarzen op beton. Deze kenmerken gaan vervolgens naar een transformermodule, een moderne sequentieverwerkingsmotor die patronen over veel stappen onderzoekt—ritme, afstand en herhaalde inslagen—in plaats van geïsoleerde geluiden. Positionele codering helpt het model de volgorde in de tijd bij te houden, wat essentieel is voor het herkennen van looppatronen.
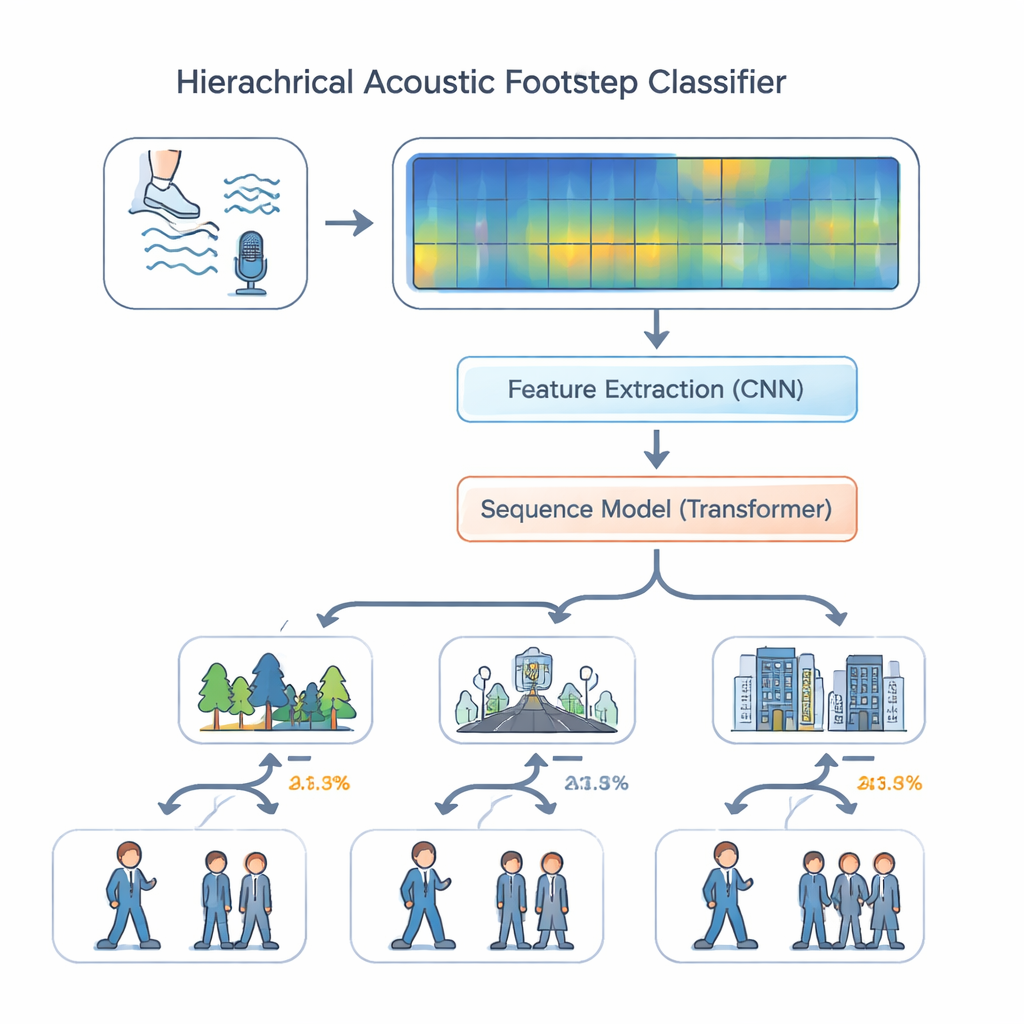
Hoe goed werkt de akoestische wachter?
De onderzoekers vergeleken hun hiërarchische model met eenvoudigere benaderingen, zoals een enkel alles-in-één classificatiemodel en een standaard multi-task ontwerp waarbij omgeving en aantal personen onafhankelijk worden voorspeld. Ze testten ook varianten waarbij belangrijke componenten zoals de convolutionele lagen of de transformer waren weggelaten. Algeheel presteerde het volledige ontwerp met beide modules en positionele codering het beste. Op de EWFootstep 1.0-dataset identificeerde het model de omgeving in ongeveer 96 procent van de gevallen correct en het aantal personen met vergelijkbare nauwkeurigheid—aanzienlijk beter dan getrainde menselijke luisteraars, die 25 tot 30 procentpunt achterbleven. Aanvullende experimenten op een hoestgeluid-dataset toonden dat dezelfde architectuur goed generaliseert buiten voetstappen, wat suggereert dat het zeer verschillende soorten alledaagse audio kan verwerken.
Van slagveld tot plaats delict
Voor niet‑specialisten is de kernboodschap dat zwakke, alledaagse geluiden zoals voetstappen veel meer informatie bevatten dan we gewoonlijk opmerken. Door grote, realistische datasets te combineren met geavanceerde patroonherkenningstools tonen de auteurs aan dat een compact systeem betrouwbaar kan bepalen naar wat voor soort locatie het luistert en hoeveel mensen er zijn, bijna in real time en zonder camera’s. Deze “akoestische wachter” kan patrouilles en afgelegen faciliteiten helpen beschermen, en het vermogen om subtiele geluidspatronen te ontleden kan ook nuttig zijn voor audioforensisch onderzoek, bijvoorbeeld bij het reconstrueren van bewegingen op een plaats delict wanneer video niet beschikbaar of onbetrouwbaar is.
Bronvermelding: Agrahri, A., Maurya, C.K., Tiwari, R.S. et al. Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance. Sci Rep 16, 5635 (2026). https://doi.org/10.1038/s41598-026-35756-3
Trefwoorden: akoestische bewaking, voetstapdetectie, vroegtijdige waarschuwingssystemen, deep learning audio, tactische beveiliging