Clear Sky Science · nl
Machine learning voor snelle inschatting van macroseismische intensiteit uit seismometrische gegevens in Italië
Waarom snelle schokbeoordelingen ertoe doen
Wanneer de grond begint te schudden, hebben hulpdiensten slechts enkele minuten om te beslissen waar ze reddingswerkers en middelen moeten inzetten. Toch komt de gebruikelijke manier om te beschrijven hoe sterk een aardbeving aan het oppervlak wordt gevoeld — macroseismische intensiteit, zoals de Mercalli-schaal die in Italië wordt gebruikt — vaak pas uren, dagen of zelfs maanden later, nadat mensen vragenlijsten hebben ingevuld en deskundigen de schade hebben onderzocht. Dit artikel onderzoekt hoe moderne machine learning de eerste seismometerlezingen kan omzetten in snelle, redelijk nauwkeurige kaarten van hoe sterk een aardbeving is gevoeld, zodat autoriteiten sneller en met meer vertrouwen kunnen reageren.
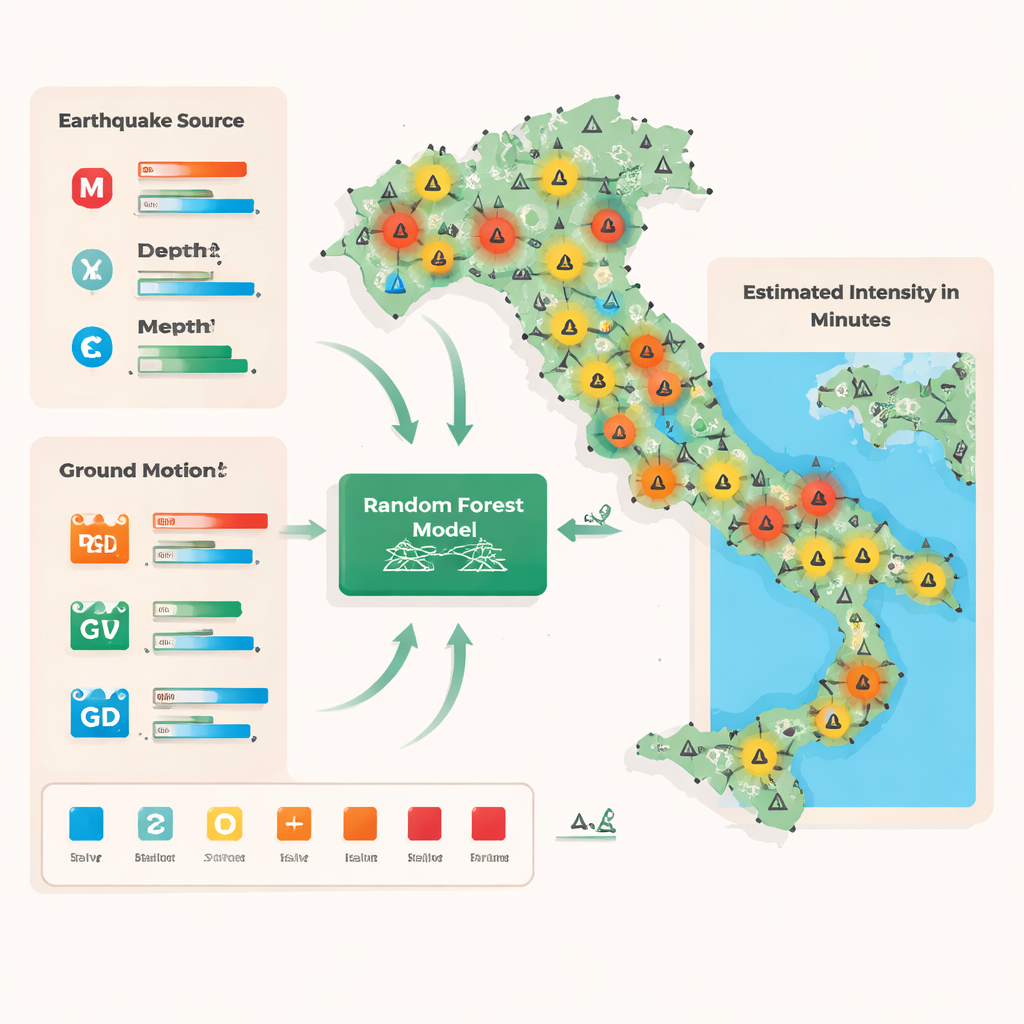
Van meldingen van gevoelde bevingen naar snelle schattingen
Traditionele intensiteitsschattingen in Italië steunen op twee hoofdgegevensstromen. De ene bestaat uit deskundige veldinspecties vastgelegd in een officiële database, die zich richten op beschadigde locaties maar tijd vergen om te organiseren. De andere komt van het online systeem “Hai Sentito Il Terremoto”, waar burgers melden wat ze hebben gevoeld en gezien, en dat veel waarnemingen van lage en gemiddelde intensiteit oplevert. Beide bronnen meten intensiteit op de Mercalli-Cancani-Sieberg-schaal, die de trillingen van zeer zwak tot destructief rangschikt op basis van menselijke waarnemingen en gebouwreacties. Om deze mensgerichte maatstaven aan instrumentlezingen te koppelen, hebben de auteurs de twee datasets rond elk seizmisch station samengevoegd, daarbij alle gerapporteerde intensiteiten binnen 5 km gemiddeld tot één representatieve waarde voor dat gebied en deze afgerond op een geheel getalsklasse van 1 tot 8.
Een bos van modellen leren schokken te lezen
De onderzoekers benaderden intensiteitsschatting als een classificatieprobleem: gegeven vroege metingen, voorspellen welke van acht intensiteitsklassen op de omgeving van elk station van toepassing zal zijn. Ze gebruikten een Random Forest, een ensemble van vele beslisbomen die elk een eenvoudige reeks "als–dan"-splitsingen op de gegevens uitvoeren, zoals combinaties van magnitude, diepte, afstand tot de bron en directe grondbewegingsmaatregelen zoals piekversnelling, -snelheid en -verplaatsing. Getraind op 5.466 waarnemingen van 523 aardbevingen in heel Italië (2008–2020), leerde het model complexe, niet-lineaire verbanden tussen wat seismometers registreren en wat mensen rapporteren. Om om te gaan met het feit dat sterke trillingen zeldzamer zijn in de data, pasten de auteurs de training aan zodat alle intensiteitsniveaus even zwaar meetelden, waardoor het model niet alleen op de meest voorkomende, zwakkere gebeurtenissen ging focussen.
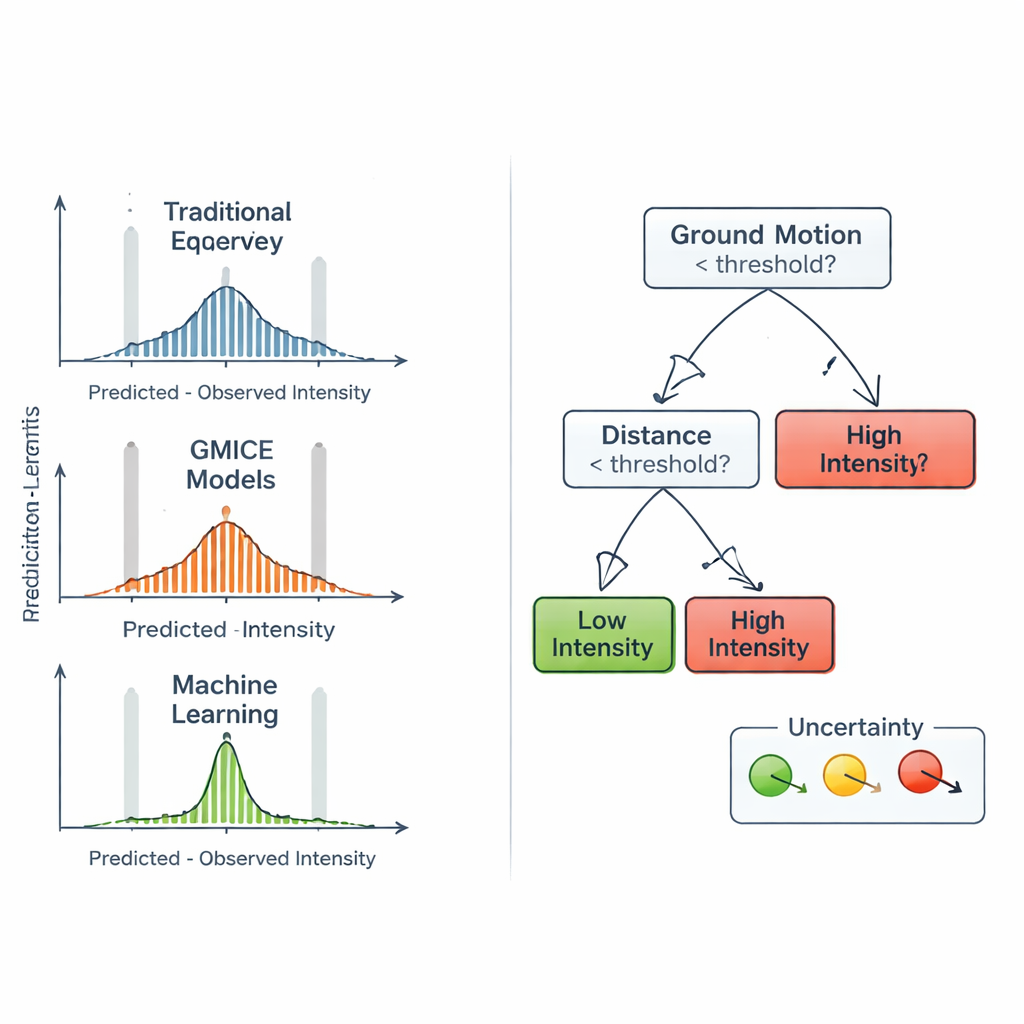
Vergelijken met gevestigde regels
Om te beoordelen of de machine-learningbenadering echt meerwaarde biedt, vergeleek het team zijn voorspellingen met twee veelgebruikte families empirische relaties. De eerste, genaamd Intensity Prediction Equations, schat intensiteit voornamelijk op basis van de magnitude, diepte en afstand van de aardbeving, met de veronderstelling dat de trillingen geleidelijk met de afstand afnemen. De tweede, Ground Motion to Intensity Conversion Equations, zet instrumentlezingen van piekbewegingen om in verwachte intensiteitsklassen. Deze formules zijn compact en makkelijk toe te passen, maar kunnen niet volledig vastleggen hoe lokale geologie, bouwvoorraad of golfrichting de ervaren trillingen beïnvloeden. De Random Forest integreert daarentegen op natuurlijke wijze zowel bronparameters als grondbewegingsmetingen en kan zich aanpassen aan subtiele patronen in de Italiaanse dataset zonder een vooraf vastgelegde rigide wiskundige vorm.
In de zwarte doos kijken en de beperkingen ervan
Aangezien hulpverleningsmanagers de basis van geautomatiseerde beslissingen moeten begrijpen, bouwden de auteurs eenvoudigere "surrogaat"-beslisbomen die het gedrag van de Random Forest nadoen. Deze kleinere bomen kunnen als diagrammen worden getekend en tonen welke grondbewegingsdrempels lage van hoge intensiteit scheiden en waar variabelen zoals acceleratie en snelheid domineren. Deze analyse toonde aan dat directe grondbewegingsmetingen, vooral piekversnelling en -snelheid, zwaarder wegen dan magnitude of diepte alleen. De auteurs introduceerden ook een eenvoudige manier om aan te geven hoe onzeker elke surrogaat-boomvoorspelling is, met behulp van maten van hoe gemengd de trainingsvoorbeelden zijn binnen elk uiteindelijke takje. Tegelijkertijd vonden ze dat zeer sterke intensiteiten moeilijk blijven te voorspellen, deels omdat ze van nature zeldzaam zijn in het historische record, wat soms leidt tot onderschatting van de hoogste trillingsniveaus.
Praktische proef tijdens een recente Italiaanse aardbeving
Het team evalueerde hun raamwerk op een opvallende recente gebeurtenis: een aardbeving van magnitude 5,5 voor de Adriatische kust nabij Pesaro-Urbino in 2022. Binnen ongeveer 15 minuten hadden seismologen de benodigde bron- en grondbewegingsinformatie, maar waren er pas ongeveer 90 openbare intensiteitsmeldingen ingediend, wat een zeer fragmentarisch beeld gaf. Alleen met de instrumentele gegevens genereerden de Random Forest en zijn surrogaatboom gedetailleerde intensiteitschaattingen rond honderden stations in minder dan twee seconden op een standaardcomputer. Wanneer deze later werden vergeleken met de veel dichtere kaart die was opgebouwd uit meer dan 12.000 burgermeldingen verzameld over meerdere dagen, legden de machine-learningkaarten zowel het algemene gevoelde gebied als de verspreiding van matige trillingen opmerkelijk goed vast en evenaarden of overtroffen ze de klassieke vergelijkingen.
Wat dit betekent voor mensen die met aardbevingen leven
Alles bij elkaar laat de studie zien dat een zorgvuldig getraind machine-learningsysteem de eerste minuten aan seismometergegevens kan nemen en snelle, redelijk transparante kaarten van aardbevingseffecten kan produceren. Deze kaarten vervangen geen gedetailleerde inspecties of crowdsourced meldingen, maar ze kunnen de gevaarlijke vroege kloof overbruggen wanneer autoriteiten moeten kiezen waar ze ambulances, brandweerlieden en constructeursinspecteurs sturen met zeer beperkte informatie. Door geavanceerde algoritmen te combineren met interpreteerbare vereenvoudigde modellen en eenvoudige onzekerheidsindicatoren biedt het raamwerk een praktische stap richting snellere, beter onderbouwde respons op aardbevingen in Italië en kan het worden aangepast aan andere regio's met vergelijkbare seismische risico's.
Bronvermelding: Patelli, L., Cameletti, M., De Rubeis, V. et al. Machine learning for prompt estimation of macroseismic intensity from seismometric data in Italy. Sci Rep 16, 7265 (2026). https://doi.org/10.1038/s41598-026-35740-x
Trefwoorden: aardschokintensiteit, machine learning, random forest, seismisch risico, Italië