Clear Sky Science · nl
Multi-feature enhancement fusion network voor semantische segmentatie van remote sensing‑beelden
Scherpere kaarten vanuit de lucht
Elke dag leggen satellieten en drones gedetailleerde beelden vast van onze steden en landbouwgebieden. Deze ruwe beelden omzetten in heldere pixel‑voor‑pixel kaarten van wegen, daken, bomen en gewassen is essentieel voor taken zoals het volgen van gewasgezondheid of het plannen van nieuwe woonwijken. Dit artikel introduceert een nieuwe methode om die kaarten nauwkeuriger te maken, vooral langs lastige grenzen waar gebouwen, velden en vegetatie in elkaar overlopen.
Waarom luchtbeelden moeilijk te lezen zijn
Remote sensing‑beelden verschillen van alledaagse foto’s. Ze worden vanuit grote hoogte gemaakt, vaak onder scherpe hoeken en bij wisselende lichtomstandigheden. Verschillende objecten kunnen vanuit de lucht erg op elkaar lijken: een betonnen parkeerplaats en een plat dak kunnen bijna dezelfde kleur hebben; verschillende gewastypen kunnen verwarrend gelijkende patronen vertonen. Tegelijk kan hetzelfde soort object er heel anders uitzien door schaduw, vochtigheid of camera‑instellingen. Traditionele algoritmen, en zelfs veel moderne deep‑learning‑systemen, worstelen om randen scherp te houden onder deze omstandigheden. Ze vervagen vaak de grenzen tussen categorieën of missen kleine details zoals geparkeerde auto’s of smalle irrigatiekanalen.
Het grote beeld en de fijne lijnen tegelijk zien
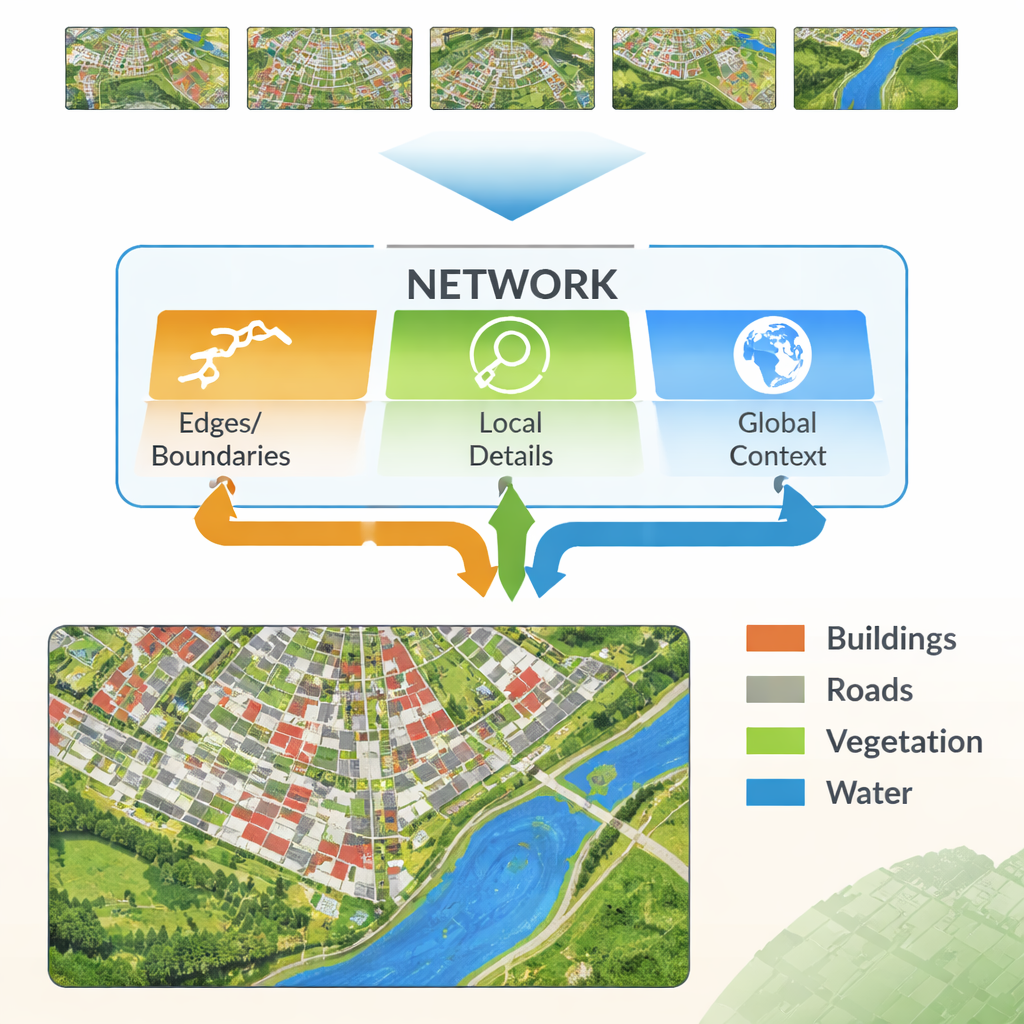
Moderne neurale netwerken leren door een afbeelding door vele lagen te leiden. Vroege lagen pikken fijne details op zoals lijnen en texturen, terwijl diepere lagen brede patronen leren, bijvoorbeeld “dit gebied is waarschijnlijk gebouwen.” De uitdaging is dat het combineren van deze twee typen informatie niet eenvoudig is. Lage‑niveau details kunnen ruisig en redundant zijn, en hoge‑niveau patronen kunnen de randen wegvloeien, wat resulteert in vage contouren. De auteurs stellen een nieuwe architectuur voor, de Multi‑Feature Enhancement Fusion Network (MFEF‑UNet), die expliciet is ontworpen om lokale details en globaal begrip in balans te brengen. Dit gebeurt door randen, lokale patronen en brede context als afzonderlijke maar samenwerkende informatielijnen te behandelen.
Randen benadrukken en kenmerken samenvoegen
Een kernidee van de nieuwe methode is het lenen van eenvoudige, klassieke randdetectietools en deze verweven in een modern deep‑learning‑proces. Een Edge Enhancement Module neemt de vroegste features uit het netwerk en leidt ze door operatoren die bijzonder goed zijn in het vinden van grenzen—vergelijkbaar met hoe basale beeldbewerkingssoftware contouren kan detecteren. Deze verbeterde randkaarten worden op meerdere schalen geproduceerd, zodat het netwerk zowel fijne als grove grenzen ziet. Een Multi‑Feature Fusion Module brengt vervolgens drie stromen samen: de zich ontwikkelende hoge‑niveau “wat is dit gebied?” informatie, de reconstructie van details door de decoder, en de randkaarten. In plaats van ze simpelweg op te stapelen, gebruikt de module een aandacht‑achtige mechaniek zodat semantische features de rand‑ en detailstromen kunnen ‘‘vragen’’ waar grenzen en kleine structuren zich daadwerkelijk bevinden, en de uiteindelijke representatie dienovereenkomstig kunnen aanpassen.
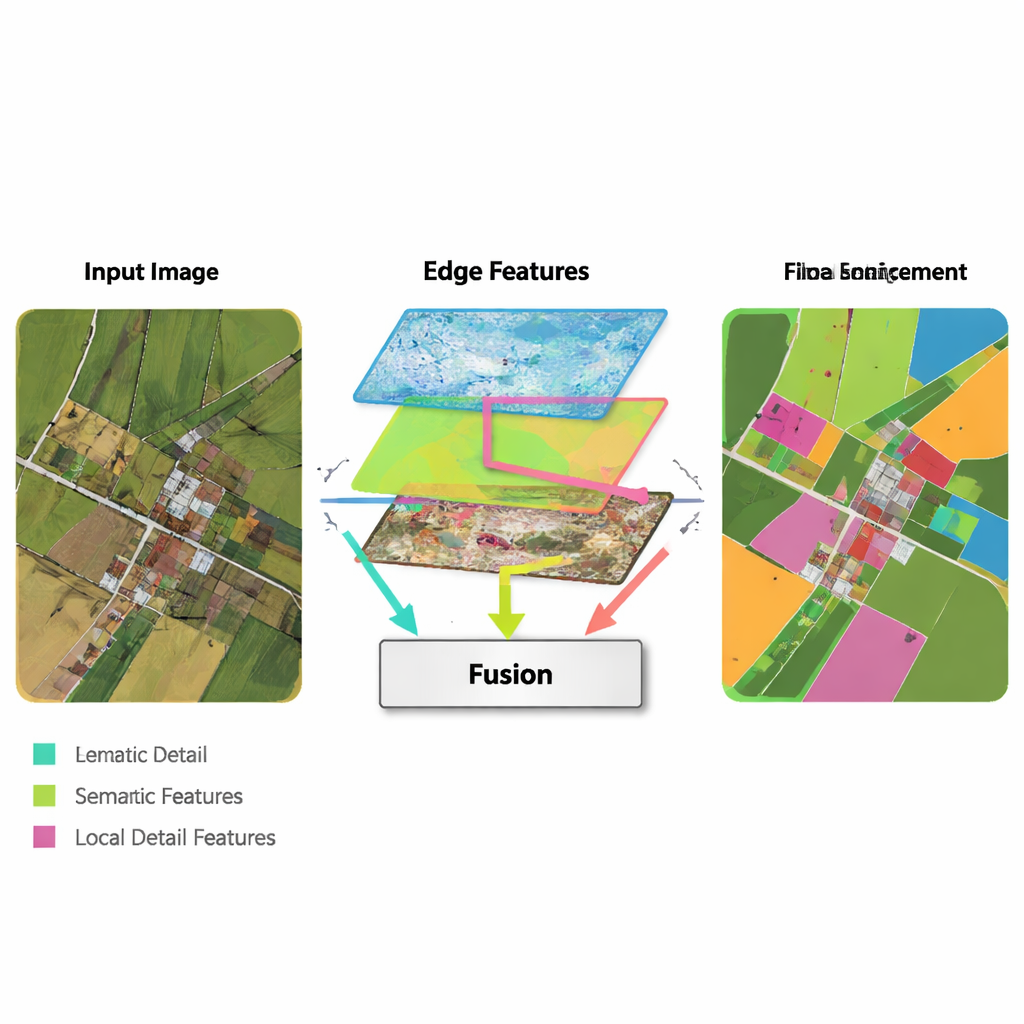
Lokale details in balans met globale context
Een ander ingrediënt van MFEF‑UNet is een Local‑Global Feature Enhancement Module. Voor niet‑specialisten is dit te zien als het deel van het netwerk dat ervoor zorgt dat het de bos niet uit het oog verliest terwijl het op de bomen let—of de stad niet vergeet terwijl het elk gebouw verfijnt. De afbeelding wordt opgesplitst in hanteerbare sub‑vensters zodat nabijgelegen pixels samen gemodelleerd kunnen worden, waardoor vormen en texturen behouden blijven. Na deze lokale modellering worden de vensters weer aan elkaar genaaid tot een volledige afbeelding, en een tweede stap laat informatie over verre gebieden stromen. Dit tweestapsproces helpt het model zowel kleine structuren, zoals auto’s en smalle veldgrenzen, als grootschalige patronen, zoals woonblokken of aaneengesloten waterlichamen, te respecteren.
De methode testen op steden en landbouwgrond
De onderzoekers testten hun aanpak op drie openbaar beschikbare datasets: twee die Europese dorpen en steden beslaan, en één grote verzameling landbouwbeelden uit de Verenigde Staten. Deze datasets bevatten een mix van daken, wegen, vegetatie, water en subtiele gewasp Patronen. Over alle drie de benchmarks produceerde MFEF‑UNet consequent nauwkeurigere kaarten dan een reeks toonaangevende methoden, waaronder klassieke convolutionele netwerken, Transformer‑gebaseerde architecturen en nieuwere “state‑space” modellen. De voordelen waren het duidelijkst rond complexe gebouwcontouren, clusters van kleine objecten zoals voertuigen, en lange, dunne structuren zoals drainagesloten of rijen gewassen—plaatsen waar andere methoden vaak de segmentatie fragmenteren of vervagen.
Wat dit in de praktijk betekent
In praktische termen zet het voorgestelde netwerk luchtbeelden om in schonere, betrouwbaardere landbedekkingskaarten. Stedenbouwkundigen kunnen bebouwde gebieden met meer vertrouwen meten, ingenieurs kunnen wegen en daken beter traceren, en agronomen kunnen velden, waterlopen en zones met gewasstress nauwkeuriger afbakenen. Hoewel de toegevoegde rand‑ en fusiecomponenten enige extra rekencapaciteit vereisen, blijft het algehele ontwerp redelijk efficiënt en levert het duidelijke verbeteringen in nauwkeurigheid en robuustheid. Voor niet‑specialisten is de conclusie dat door randen doelbewust te benadrukken en verschillende visuele aanwijzingen zorgvuldig samen te voegen, computers satelliet‑ en dronebeelden met een scherpere blik kunnen lezen—en ons dichter brengen bij actuele, nauwkeurige kaarten van de wereld.
Bronvermelding: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Trefwoorden: remote sensing, semantische segmentatie, satellietbeelden, deep learning, landbedekkingskaarten