Clear Sky Science · nl
Van gegevens naar beslissingen: het gebruik van uitlegbare AI om de sojaopbrengst in de belangrijkste producerende landen te voorspellen
Waarom slimmer gewasvoorspellingen ertoe doen
Van supermarktprijzen tot wereldhandel: de bescheiden soja speelt een verrassend grote rol in het dagelijks leven. Overheden, handelaren en boeren moeten maanden voordat de maaidorsers de velden in gaan weten hoe groot de oogst zal zijn. Tegenwoordig kunnen krachtige kunstmatige intelligentie (AI)-tools bergen weers- en satellietgegevens doorploegen om die voorspellingen te doen — maar veel van die modellen werken als “black boxes” en geven weinig inzicht in waarom ze een bepaald antwoord geven. Deze studie onderzoekt een nieuw soort uitlegbare AI die niet alleen sojaopbrengsten in de belangrijkste producerende landen voorspelt, maar ook helder laat zien welke factoren die voorspellingen aansturen.
Drie landen die de wereld voeden
De onderzoekers concentreerden zich op de drie landen die de mondiale sojavoorraden domineren: de Verenigde Staten, Brazilië en Argentinië, die samen meer dan 80% van 's werelds soja produceren. Ze zochten in op een fijn schaalniveau — counties in de VS en equivalente kleine regio’s in Brazilië en Argentinië — en gebruikten recente data van 2018 tot 2022. Voor elke regio stelden ze een rijk beeld van groeiomstandigheden samen: gedetailleerde weersregistraties, bodemkenmerken en verschillende soorten satellietdata die plantaardige groei, waterstatus en zelfs een zwakke gloed van fotosynthese volgen, bekend als solar-induced chlorophyll fluorescence (SIF). In totaal werden 154 verschillende numerieke kenmerken geëxtraheerd om elk groeiseizoen te beschrijven voordat die in de modellen werden gevoerd.
Van datapijplijnen naar leermachines
Om deze informatiestroom te verwerken bouwde het team een gestandaardiseerde verwerkingspijplijn. Ze lijnen alle datasets in ruimte en tijd uit met behulp van teeltkalenders, verzachtten ruis in satellietsignalen en vatten het groeiseizoen samen met statistieken zoals gemiddelden, extremen en variabiliteit. Vervolgens trainden ze drie typen modellen om opbrengsten te voorspellen: Random Forest (RF), een veelgebruikt machine learning-werkpaard; Multilayer Perceptron (MLP), een klassiek neuraal netwerk; en Kolmogorov–Arnold Networks (KAN), een nieuwere architectuur die van meet af aan is ontworpen om beter interpreteerbaar te zijn. Om zichzelf te behoeden voor te optimistische scores splitsten de auteurs de data zorgvuldig in ruimtelijke blokken zodat de modellen getest werden op regio’s die ze tijdens de training niet hadden “gezien”.
De zwarte doos van AI openen
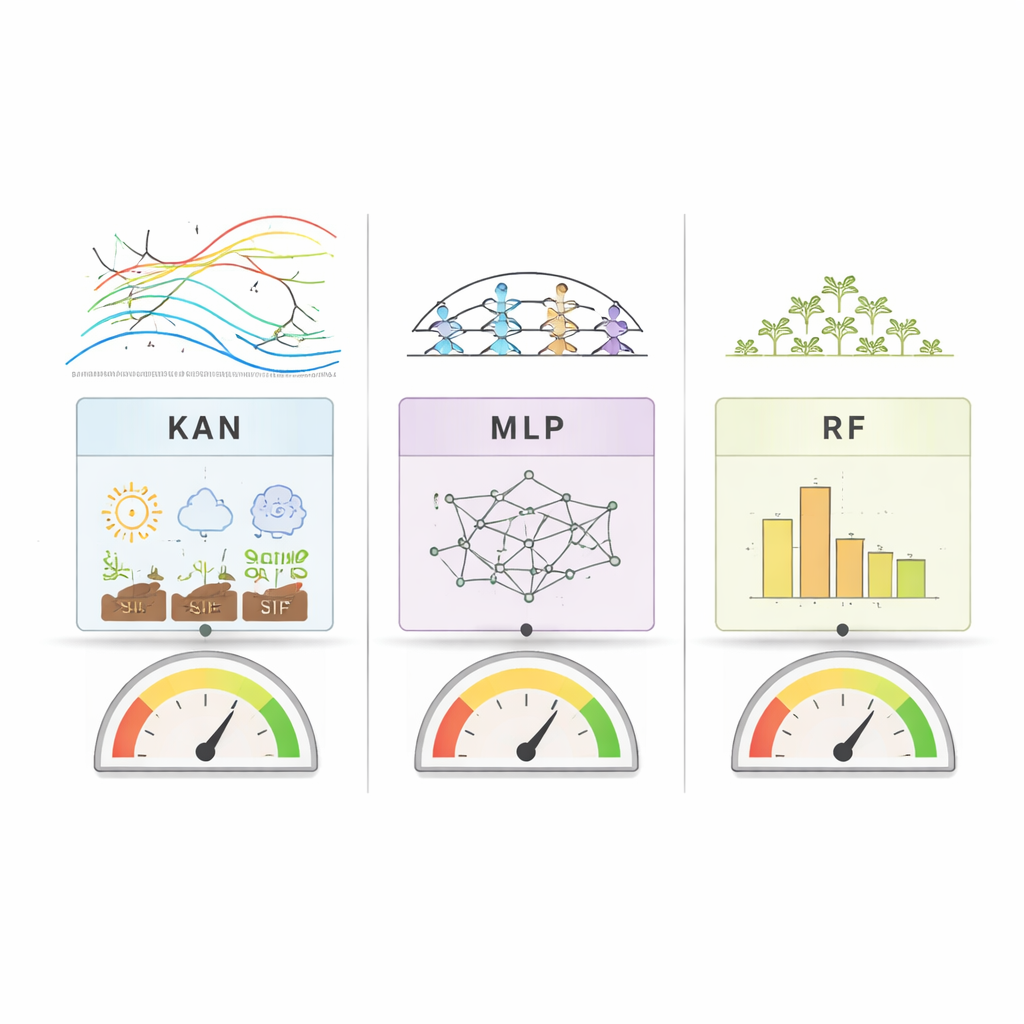
Wat dit werk onderscheidt is niet alleen de nauwkeurigheid van de voorspellingen, maar ook hoe de modellen zichzelf uitleggen. RF en MLP werden onderzocht met standaardtools die laten zien hoeveel elk invoerkenmerk bijdraagt aan hun voorspellingen. KAN gaat een stap verder: het vertegenwoordigt de verbanden tussen inputs en outputs als vloeiende eendimensionale krommen die geplot en geïnspecteerd kunnen worden. Dit stelt onderzoekers in staat letterlijk te zien hoe bijvoorbeeld een verandering in SIF of bodemvocht de opbrengst omhoog of omlaag duwt. Over landen en methoden heen was één patroon duidelijk — SIF, het satellietsignaal dat direct aan fotosynthese gekoppeld is, stond consequent bij de belangrijkste voorspellers van sojaopbrengst. Andere bepalende factoren verschilden per regio: in de Verenigde Staten vielen watergerelateerde vegetatiesignalen op, terwijl in Brazilië en Argentinië temperatuur en bodemvocht sterkere rollen speelden.
Hoe goed presteerden de modellen?
Toen de onderzoekers de modelnauwkeurigheid vergeleken, won geen enkele methode in elke situatie duidelijk. In de Verenigde Staten, waar de opbrengsten relatief stabiel waren van jaar tot jaar, presteerde Random Forest iets beter in het algemeen, maar KAN en MLP zaten dicht achter. In Brazilië, met meer volatiele opbrengsten en een grotere dataset, bereikten alle drie modellen hoge nauwkeurigheid, hoewel ze het wat moeilijk hadden bij het voorspellen van zeer hoge opbrengsten. In Argentinië, waar de data meer beperkt waren, presteerde KAN over het algemeen beter dan de deep learning-baseline (MLP) en kwam het dicht in de buurt van Random Forest. Deze resultaten suggereren dat KAN traditionele modellen kan evenaren op moeilijke, kleine landbouwdatasets terwijl het veel grotere transparantie biedt over hoe het tot zijn conclusies komt.
Wat dit betekent voor boeren en voedselzekerheid
Voor beslissers in de praktijk kan het vertrouwen in een model net zo belangrijk zijn als ruwe nauwkeurigheid. Deze studie toont aan dat uitlegbare AI-benaderingen zoals KAN concurrerende sojaopbrengstvoorspellingen kunnen leveren terwijl ze duidelijk onthullen welke omgevings- en gewassignalen het meest van belang zijn. Die zichtbaarheid helpt wetenschappers fouten te diagnosticeren, agronomische expertise in te brengen en modellen aan te passen aan nieuwe regio’s of een veranderend klimaat. Op de lange termijn zouden zulke transparante hulpmiddelen in nationale gewasmonitoringsystemen kunnen worden geïntegreerd en boeren, planners en markten eerder en betrouwbaarder kunnen waarschuwen voor misoogsten of recordopbrengsten — en zo bijdragen aan veerkrachtigere en duurzamere voedselsystemen.
Bronvermelding: Wang, X., He, Y., Chen, H. et al. From data to decisions: the use of explainable AI to forecast soybean yield in major producing countries. Sci Rep 16, 5103 (2026). https://doi.org/10.1038/s41598-026-35716-x
Trefwoorden: voorspelling sojaopbrengst, uitlegbare AI, remote sensing, landbouwmodellering, voedselzekerheid