Clear Sky Science · nl
Transformer-verrijkte dubbel-branch Siamese-tracker met betrouwbaarheidsbewuste regressie en adaptieve templatevernieuwing
Computers leren één object volgen in een drukke scène
Van zelfrijdende auto’s tot beveiligingscamera’s voor thuis en drones: veel moderne apparaten moeten één bewegend object volgen in een drukke, veranderende omgeving. Deze taak, visuele objecttracking genoemd, lijkt eenvoudig voor mensen maar is verrassend lastig voor machines: voorbijgangers lopen voor de camera, de verlichting verandert, het object krimpt door afstand of wordt kortzeitig verborgen. Dit artikel introduceert TSDTrack, een nieuw trackingsysteem dat gebruikmaakt van recente vooruitgang in deep learning en transformers om in dergelijke realistische omstandigheden betrouwbaarder op een doel te blijven gericht.
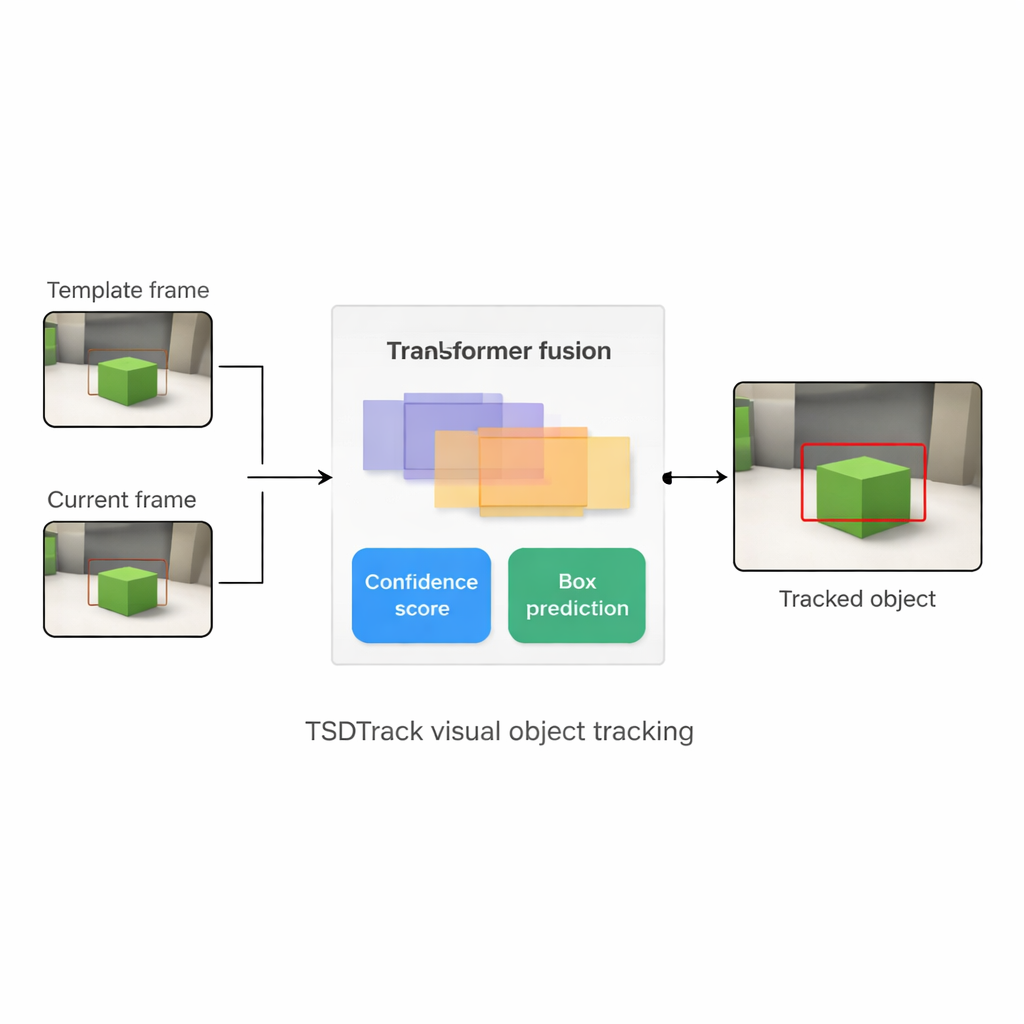
Waarom één ding volgen zo moeilijk is
Een tracker ziet het object meestal alleen duidelijk in het eerste frame van een video en moet het daarna blijven vinden terwijl de scène verandert. Traditionele methoden vertrouwden ofwel op handgemaakte beeldkenmerken of op een neuraal netwerk dat het eerste frame (de "template") met elk nieuw frame vergeleek. Deze oudere systemen hadden drie belangrijke zwakke punten. Ten eerste hielden ze doorgaans de originele template vast, waardoor de tracker moeite kreeg wanneer het object draaide, gedeeltelijk werd afgedekt of van grootte veranderde. Ten tweede richtten ze zich vaak op één detailniveau in het beeld en misten zo de combinatie van fijne randen en breder contextuele informatie die mensen helpt dingen te herkennen. Ten derde wisten ze niet wanneer ze twijfel moesten hebben: ze produceerden een kader rond het veronderstelde object zonder duidelijk gevoel voor de betrouwbaarheid van die schatting, waardoor ze geneigd waren naar de achtergrond te verdrijven.
Globale context mengen met fijne details
TSDTrack pakt deze problemen aan door een klassieke "Siamese" trackingopzet te combineren met een transformer, hetzelfde type aandacht-gebaseerd model dat taal- en visietaken heeft veranderd. Het systeem gebruikt een diep netwerk om kenmerken te extraheren uit twee inputs: een klein patch dat het doel definieert en een groter patch dat het huidige zoekgebied bevat. In plaats van te vertrouwen op slechts één schalenniveau van kenmerken, haalt het informatie uit meerdere lagen van het netwerk, die randen, vormen en objectniveau-patronen representeren. Een transformer-gebaseerde fusiemodule leert vervolgens hoe deze lagen te mengen zodat de tracker zowel begrijpt waar dingen zich in het beeld bevinden als hoe ze zich tot de bredere scène verhouden. Dit helpt het doel te onderscheiden van vergelijkbare objecten en rommel, zelfs wanneer het beeld ruis bevat of gedeeltelijk geblokkeerd is.
Weten hoe zeker de tracker werkelijk is
De kern van TSDTrack is een voorspellingseenheid met twee takken die de taak opsplitst in twee verwante vragen: "Waar is het object?" en "Hoe veel vertrouwen hebben we in dit antwoord?" De ene tak schat een confidentiescore die niet alleen weerspiegelt hoe vergelijkbaar het doel eruitziet, maar ook hoe goed het voorspelde kader overlapt met waarschijnlijke objectregio’s. De andere tak behandelt de kadercoördinaten niet als één enkele gok, maar als een waarschijnlijkheidsverdeling over veel mogelijke posities, waardoor het model onzekerheid kan representeren. Als het beeld helder is, wordt de verdeling scherp en is het kader precies; als het object wazig of gedeeltelijk verborgen is, spreidt de verdeling zich uit. Deze probabilistische benadering leidt tot vloeiendere, stabielere kaderplaatsing vergeleken met oudere trackers die één starre voorspelling deden.
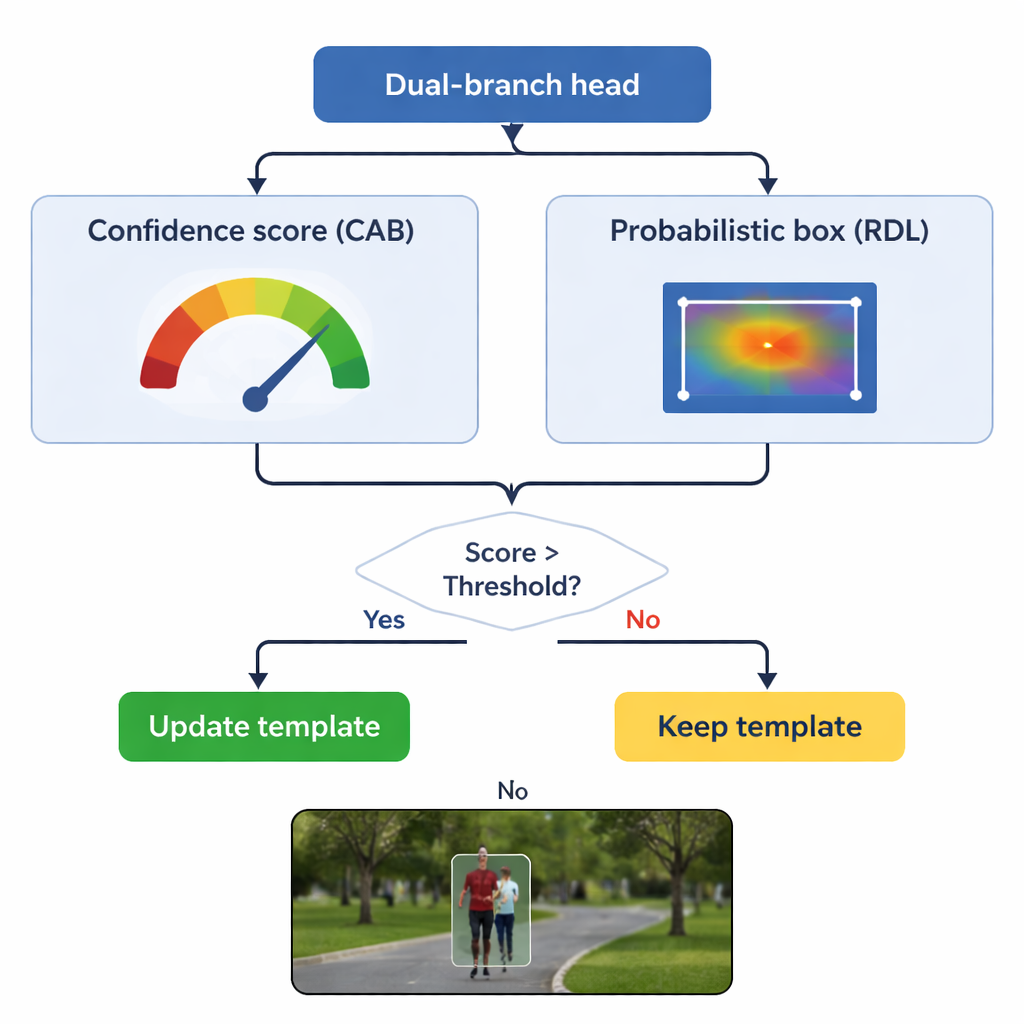
Geheugen bijwerken zonder het origineel te vergeten
Een belangrijk risico bij tracking is "template drift": als het model zijn idee van het object blijft bijwerken met slecht gekeurde frames, kan het geleidelijk de achtergrond leren. TSDTrack pakt dit aan door zijn confidentietak als poortwachter te laten fungeren. Het systeem werkt zijn interne template alleen bij wanneer de confidentiescore boven een gekozen drempel ligt, en zelfs dan mengt het nieuwe informatie voorzichtig met de originele weergave in plaats van die volledig te vervangen. Deze selectieve bijwerking laat de tracker zich aanpassen aan echte veranderingen, zoals een persoon die zich omdraait of een auto die roteert, zonder misleid te worden door tijdelijke occlusies of afleidingen. De originele template wordt ook als reserve bewaard als stabiele referentie voor het geval latere updates misleidend blijken.
Wat de resultaten praktisch betekenen
De auteurs testten TSDTrack op verschillende veelgebruikte tracking-benchmarks, waaronder lange video's, snelle bewegingen, luchtbeelden van drones en scènes met veel rommel. Over deze tests heen versloeg de nieuwe methode consequent veel toonaangevende trackers zowel in nauwkeurigheid (hoe dicht het kader bij het werkelijke object ligt) als in robuustheid (hoe zelden het object geheel verloren raakt), terwijl hij nog steeds snel genoeg draait voor realtime gebruik op moderne hardware. Voor niet-specialisten is de kernboodschap dat TSDTrack zijn aandacht voor een gekozen doel betrouwbaarder kan vasthouden in de rommelige omstandigheden van echte camera’s. Door multi-scale transformer-redenering, een gevoel voor eigen confidentie en zorgvuldige template-updates te combineren, biedt het een betrouwbaarder bouwblok voor toepassingen zoals autonoom rijden, slimme surveillance en intelligente robots.
Bronvermelding: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Trefwoorden: visuele objecttracking, transformer-gebaseerde tracking, Siamese-netwerken, computer vision, autonome systemen