Clear Sky Science · nl
Een satellietgebaseerde machine learning-benadering voor het schatten van hogeresolutie daggemiddelde luchttemperatuur in een megastad in Brazilië
Waarom de hitte in een stad niet overal hetzelfde is
Op een hete dag in een grote stad kan de temperatuur die u voelt in een met bomen omzoomde straat heel anders zijn dan wat iemand ervaart op een betonnen plein een paar straten verderop. Toch behandelen de meeste gezondheids- en klimaatstudies een hele stad alsof die één uniforme temperatuur heeft. Dit artikel laat zien hoe wetenschappers satellieten, weermodellen en machine learning gebruikten om dagelijkse temperaturen in detail in kaart te brengen voor São Paulo, Brazilië — waardoor duidelijk wordt wie daadwerkelijk wordt blootgesteld aan gevaarlijke hitte en waar verkoelingsmaatregelen het meest nodig zijn.
De temperatuur van de stad opnemen in hoge resolutie
Traditionele temperatuurregistraties steunen op een beperkt aantal weerstations, vaak geconcentreerd bij luchthavens of in welvarendere wijken. Daardoor is het moeilijk te zien hoe warmte zich over echte buurten verdeelt, vooral in grote steden en in landen met lage en middelhoog inkomen, waar meetnetwerken schaars zijn. De onderzoekers concentreerden zich op São Paulo, een uitgestrekte en sterk gevarieerde megastad met meer dan 22 miljoen inwoners. Hun doel was de dagelijkse gemiddelde luchttemperatuur te schatten voor elk 500 bij 500 meter groot vak in het metropolitaan gebied over vijf jaar, van 2015 tot 2019, waarmee een van de meest gedetailleerde stadsbrede temperatuurdatasets in Zuid-Amerika werd gecreëerd.
Satellieten, weermodellen en grondsensoren combineren
Om dit hogeresolutiebeeld op te bouwen, combineerde het team verschillende soorten vrij beschikbare gegevens. Ze verzamelden metingen van 48 grondstations, die de meest directe metingen van luchttemperatuur leveren maar slechts op specifieke punten. Daarnaast gebruikten ze satellietwaarnemingen van landoppervlaktetemperatuur, de hoek van de zon en hoe reflecterend de ondergrond is, samen met informatie over vochtigheid, wind en druk uit een wereldwijde weerréanalyseproduct dat elk uur het weer reconstrueert op een grof raster. Deze ingrediënten werden hertaald naar het 500‑meter raster en opgeschoond om gaten te vullen die door wolken of missende satellietpasses ontstonden. In totaal testten ze 23 mogelijke voorspellende variabelen die zouden kunnen helpen verklaren hoe warmte zich over ruimte en tijd varieert.
Een leerend systeem trainen om de hitte te lezen
In plaats van een eenvoudige rechte lijn (lineaire) vergelijking gebruikten de wetenschappers een Random Forest, een veelgebruikte machine learning-methode die vele beslisbomen bouwt en hun resultaten gemiddeld. Deze aanpak is goed geschikt om complexe, niet-lineaire relaties te ontdekken, zoals hoe temperatuur verschillend reageert op oppervlaktetemperatuur, vochtigheid en wind in verschillende delen van de stad of in verschillende jaargetijden. Om overfitting aan de eigenaardigheden van enkele stations te vermijden, gebruikten ze een stapsgewijs proces voor kenmerkselectie dat alleen variabelen behoudt die de voorspellingen daadwerkelijk verbeteren, en ze valideerden het model op twee manieren: door herhaaldelijk groepen stations uit de training weg te laten en door vijf volledige stations apart te houden als een strikte externe test voor de prestaties van het model op nieuwe locaties.
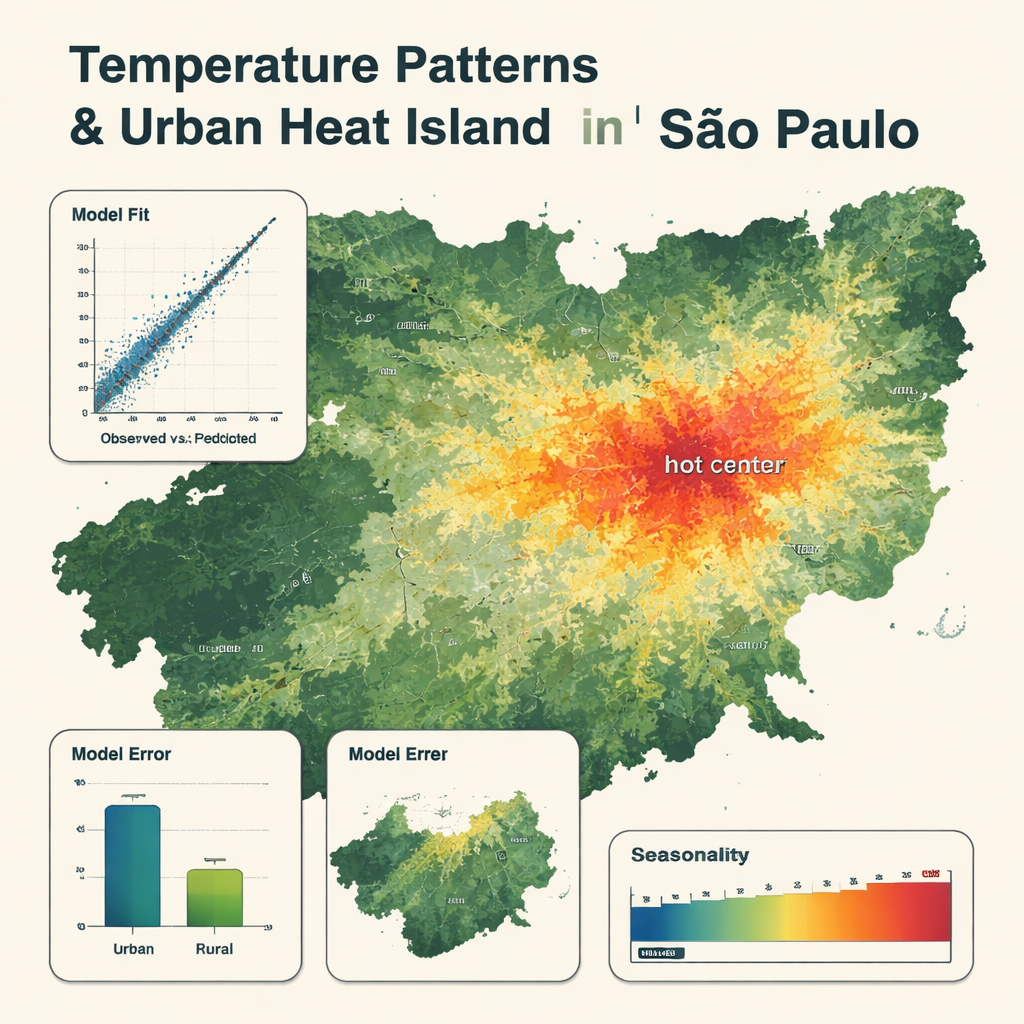
Wat de gedetailleerde kaarten onthullen
Het uiteindelijke model gebruikte slechts acht kernvariabelen, met aan het hoofd de luchttemperatuur uit het globale weerréanalyseproduct, waarbij satellietoppervlaktetemperatuur en vochtigheid ook belangrijke rollen speelden. Het reproduceerde stationmetingen zeer nauwkeurig, met een gemiddelde fout van ongeveer 0,8 °C en een zeer hoge overeenstemming tussen waargenomen en voorspelde temperaturen. De kaarten tonen duidelijke patronen: koelere zones boven bossen, bergen en grote reservoirs, en warmere zones in het dichtbebouwde stadscentrum, waar temperaturen tot 5 °C hoger kunnen zijn dan in nabijgelegen landelijke gebieden. Het model legde seizoenswisselingen vast, met de heetste omstandigheden van december tot maart en de koelste van mei tot augustus. Het was iets minder nauwkeurig in landelijke gebieden en neigde ertoe de meest extreme hete en koude dagen af te vlakken, maar presteerde nog steeds beter dan een meer traditionele meervoudige lineaire regressie met dezelfde invoervariabelen.
Waarom deze kaarten belangrijk zijn voor de gezondheid van mensen
Door verspreide metingen en satellietmomentopnames om te zetten in dagelijkse, straatnauwkeurige temperatuurinschattingen, biedt dit werk een krachtig nieuw instrument voor volksgezondheid en stedelijke planning in São Paulo en daarbuiten. Onderzoekers kunnen nu bestuderen hoe hitte verschillende wijken beïnvloedt, inclusief informele nederzettingen die vaak ontbreken in officiële registers, en identificeren waar bewoners tijdens hittegolven het meest risico lopen. Omdat de methode volledig leunt op open data en standaardsoftware, kan ze worden aangepast aan andere steden die over enkele grondstations en vergelijkbare satellietdekking beschikken. Simpel gezegd toont de studie dat we stedelijke hitte nu met veel fijnere details kunnen "zien", en daarmee een essentiële basis leggen voor eerlijkere, gerichtere klimaatadaptatie en bescherming van kwetsbare gemeenschappen.
Bronvermelding: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Trefwoorden: stedelijke hitte, machine learning, satellietgegevens, São Paulo, luchttemperatuur