Clear Sky Science · nl
Realtime identificatie van phishingaanvallen via door machine learning verbeterde browserextensies
Waarom nepwebsites ieders probleem zijn
Iedere dag ontvangen mensen berichten die lijken te komen van hun bank, een bezorgdienst of hun werkgever—maar sommige daarvan zijn zorgvuldig opgezette valstrikken. Phishing gebruikt nagemaakte e-mails en websites om wachtwoorden, creditcardgegevens en andere persoonlijke data te stelen. Omdat criminelen steeds beter worden in het nabootsen van echte sites, zijn simpele bloklijsten en intuïtie niet langer voldoende. Dit artikel beschrijft een nieuwe browseradd‑on die stilletjes de bezochte pagina’s observeert en machine learning gebruikt om gevaarlijke sites in realtime te signaleren, met als doel gewone gebruikers sterke bescherming te bieden zonder dat ze beveiligingsexperts hoeven te worden.
Hoe moderne phishingaanvallen ons misleiden
Phishing is uitgegroeid tot een van de meest voorkomende online misdrijven wereldwijd en is verantwoordelijk voor een groot deel van gemelde cyberincidenten en financiële verliezen. Aanvallers sturen overtuigende e-mails die haastig handelen aanmoedigen—“verifieer uw account”, “werk uw betaling bij”, “volg uw pakket”—en leiden slachtoffers naar valse websites die sterk lijken op echte bank-, winkel- of clouddienstenpagina’s. Veel van deze sites gebruiken inmiddels geldige HTTPS‑certificaten en een gepolijste uitstraling, waardoor oude waarschuwingen zoals “geen hangslotsymbool” of “lelijke pagina” niet meer volstaan. Enquêtes en politierapporten tonen aan dat volwassenen van ongeveer 20 tot 40 jaar zwaar worden gericht, en beveiligingsteams blijven ernstig bezorgd over e‑mailgebaseerde scams die filters omzeilen.
Een slimmere blik op webadressen en paginavormgeving
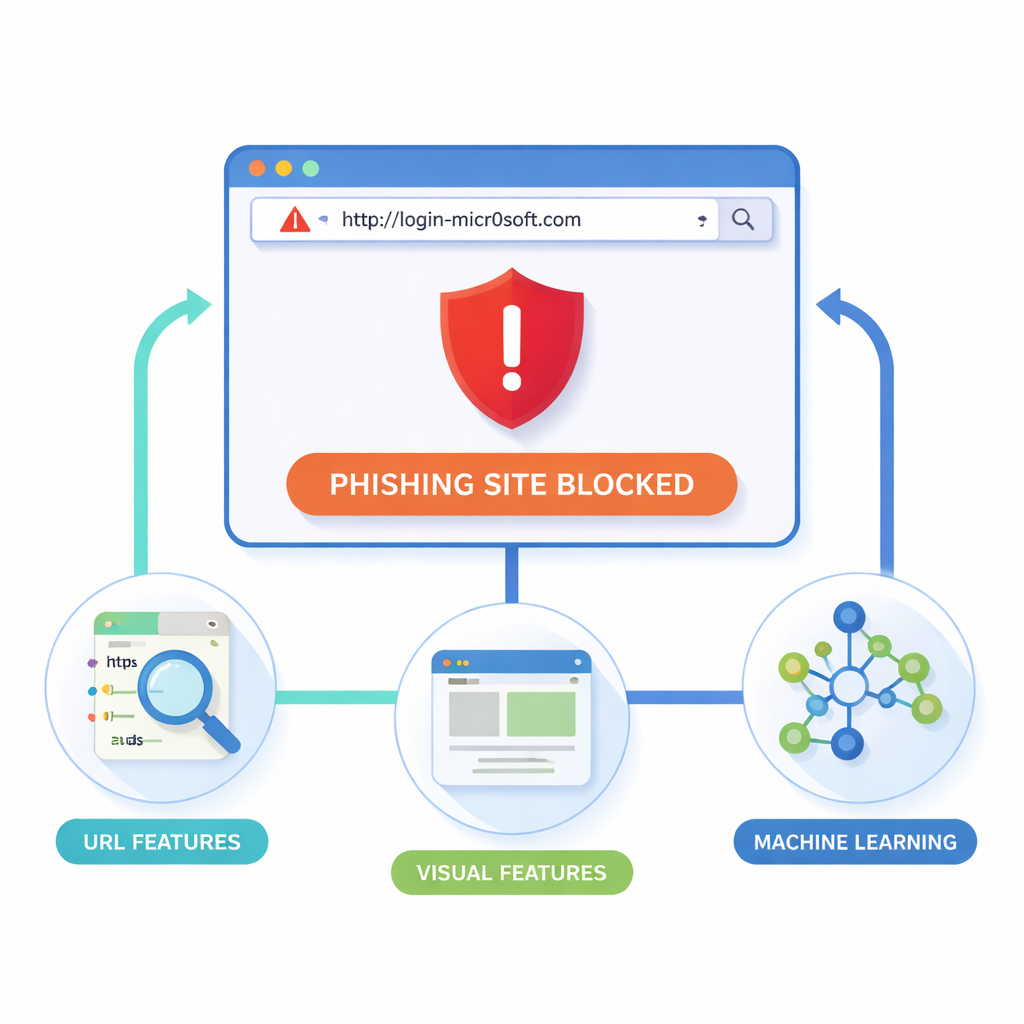
De onderzoekers betogen dat de veiligste plek om phishing te stoppen zich direct in de browser bevindt, op het moment dat een pagina wordt geladen. Hun extensie voor Google Chrome (en compatibele browsers) onderzoekt twee hoofdclues: het webadres zelf en hoe de pagina eruitziet. Van elke site verzamelen ze lexicale details uit de URL, zoals lengte, ongewone symbolen of verdachte subdomeinen; structurele en domeingerelateerde gegevens, zoals verkeer en registratiegegevens; en visuele aanwijzingen zoals lay‑outblokken, kleuren en logo’s. Een headless browser rendert elke pagina op een gecontroleerde manier, verdeelt die in rechthoekige regio’s en registreert waar formulieren, logo’s en navigatiebalken verschijnen. Vervolgens vergelijkt hij deze visuele vingerafdruk met die van vertrouwde sites om near‑copies te vinden die mogelijk frauduleus zijn.
Digitale ‘wolven’ gebruiken om de meest sprekende kenmerken te kiezen
Aangezien het systeem tientallen metingen van elke site verzamelt, moet het beslissen welke daarvan echt helpen om scams van veilige pagina’s te scheiden. Hiervoor lenen de auteurs een algoritme dat is geïnspireerd op hoe grijze wolven jagen. In deze “Grey Wolf Optimizer” concurreren veel kandidaat‑kenmerensets, en het algoritme convergeert geleidelijk naar een compacte subset die het beste evenwicht biedt tussen het vangen van phishing‑sites en het vermijden van valse alarmen. Deze geselecteerde kenmerken worden vervolgens gevoed aan drie machine‑learningmodellen—Support Vector Machine, Decision Tree en vooral Random Forest, dat veel beslissingsbomen combineert tot een sterk ensemble. De training gebruikt 80.000 websites uit openbare verzamelingen zoals PhishTank en academische archieven, met extra technieken om de onbalans tussen legitieme en kwaadaardige sites aan te pakken.
Laboratoriummodellen omzetten in een nuttige browse‑tool
Het geoptimaliseerde Random Forest‑model bereikte ongeveer 98–99% nauwkeurigheid en een Matthews Correlation Coefficient rond 0,96, een strikte maat die zowel gemiste aanvallen als valse meldingen meeneemt. In live tests met een Chrome‑extensie scant het systeem elke URL in ongeveer 200 milliseconden, snel genoeg zodat gebruikers geen vertraging merkten. Wanneer een risicovolle pagina werd gedetecteerd, toonde de add‑on een duidelijke waarschuwing en konden gebruikers kiezen om terug te gaan of op eigen risico door te gaan. Vergeleken met populaire tools zoals Google Safe Browsing en bestaande anti‑phishingextensies toonde het nieuwe systeem hogere detectieratio’s, minder foutieve waarschuwingen en het vermogen misleidende adressen te herkennen—zelfs wanneer die verkort, licht geobfusceerd of recent aangemaakt waren.
Wat dit betekent voor dagelijks browsen
Voor niet‑specialisten is de belangrijkste conclusie dat phishingverdediging niet langer alleen op giswerk of handmatige zwarte lijsten hoeft te steunen. Door te combineren hoe een link is geschreven met hoe een pagina eruitziet, en door automatisch de meest informatieve signalen te selecteren, kan de voorgestelde extensie veel scams herkennen zodra ze voor het eerst verschijnen, niet pas nadat iemand ze heeft gemeld. De auteurs erkennen dat aanvallers zich blijven ontwikkelen en dat modellen opnieuw getraind moeten worden en uitgebreid naar telefoons en andere browsers. Toch laat hun werk zien dat een intelligente, privacy‑beschermende add‑on die op uw eigen apparaat draait, kan fungeren als een onvermoeibare tweede paar ogen—stilletjes elke bezochte site controlerend en ingrijpend wanneer iets verdacht lijkt, lang voordat een gehaaste klik in een kostbare fout verandert.
Bronvermelding: Dandotiya, M., Goyal, N., Khunteta, A. et al. Real time identification of phishing attacks through machine learning enhanced browser extensions. Sci Rep 16, 6612 (2026). https://doi.org/10.1038/s41598-026-35655-7
Trefwoorden: phishingdetectie, browserextensie, machine learning, cybersecurity, nepwebsites