Clear Sky Science · nl
Visueel begeleide AI-kleurkunstbeeldgeneratie met verbeterde GAN
Waarom slimme kunstmachines ertoe doen
Digitale hulpmiddelen kunnen nu in enkele seconden portretten, landschappen en abstracte taferelen schilderen, maar veel van deze AI-kunstwerken voelen nog net even vreemd aan—kleuren botsen, texturen lijken vlak, of de “stijl” komt niet helemaal overeen met wat mensen voor ogen hadden. Dit artikel presenteert een nieuwe manier om computers te leren kleurenkunstwerken te maken die rijker, coherenter en dichter bij echte schilderijen liggen, terwijl gebruikers het resultaat kunnen bijsturen met eenvoudige visuele aanwijzingen zoals schetsen en kleurkeuzes. Het doel is AI een betrouwbaarder creatief partner te maken voor kunstenaars, ontwerpers en alledaagse gebruikers die gepersonaliseerde kunst willen zonder jarenlange training.
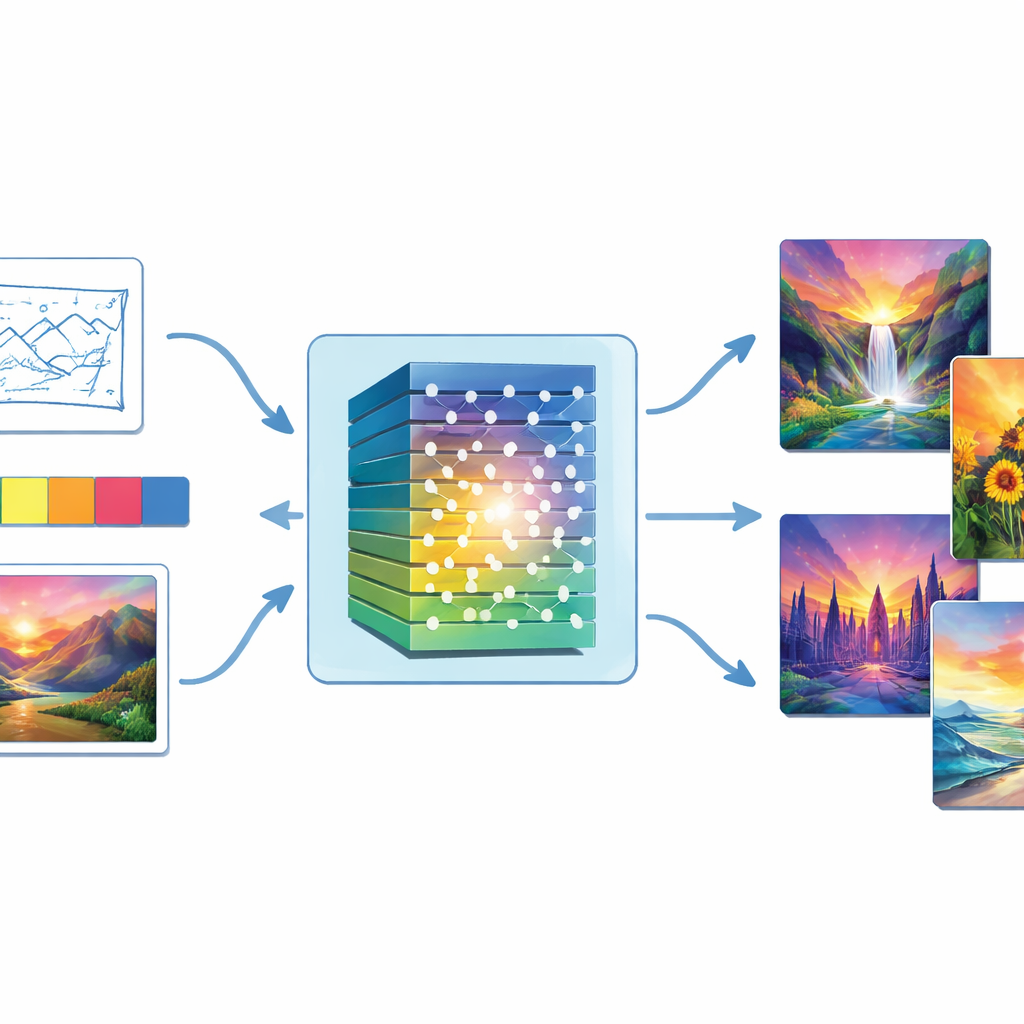
Van willekeurige ruis naar afgewerkte schilderijen
Centraal in de studie staat een type AI dat Generative Adversarial Network heet, of GAN. Een GAN bestaat uit twee tegengestelde onderdelen: een “generator” die probeert overtuigende beelden te maken uit willekeurige ruis, en een “discriminator” die beoordeelt of een afbeelding echt of nep lijkt. Door vele rondes van wederzijdse training wordt de generator beter in het misleiden van de discriminator en worden de beelden geleidelijk levensechter. De auteurs versterken dit kernidee door een diepe beeldverwerkingsstack—een convolutioneel neuraal netwerk—te integreren zowel in de generator als de discriminator, zodat het systeem beter alles kan vastleggen van brede vormen tot fijne penseelachtige details.
Het systeem leren waar het moet kijken
Hoewel standaard GANs scherpe beelden kunnen produceren, missen ze vaak het grotere geheel: ze kunnen kleine details overaccentueren en de globale structuur verliezen, of geen consistente artistieke stijl behouden. Om dit aan te pakken voegt het team een adaptief aandachtmechanisme toe. Deze module analyseert de interne feature-maps van de generator en leert tijdens training welke regio’s van een afbeelding op elk moment het belangrijkst zijn. Vervolgens versterkt het die sleutelgebieden—zoals randen, texturen en focale objecten—en verzacht het minder belangrijke achtergrondzones. Speciale verliesmaatregelen volgen hoe goed het gegenereerde beeld de stijl en textuur van een doelwerk benadert en dwingen het model zo om herkenbare inhoud in balans te brengen met een coherente artistieke uitstraling.
De machine sturen met visuele aanwijzingen
In tegenstelling tot alleen-tekstsystemen laat deze benadering mensen het kunstwerk rechtstreeks visueel sturen. Gebruikers kunnen een schets aanleveren om de compositie te definiëren, een kleurenpalet om de sfeer te bepalen, een voorbeeldstijlbeeld om na te bootsen, of eenvoudige scenetagging. Deze invoeren gaan samen met de willekeurige ruis de generator in. Het model berekent vervolgens kleurkenmerken zoals tint, verzadiging en helderheid, en past zijn output aan zodat het uiteindelijke schilderij zowel de kleurnuances van de gebruiker als de referentiestijl respecteert. Een kleur-matchingdoelstelling verstevigt de band tussen wat de gebruiker aangeeft en wat het systeem produceert, zodat een koel blauw zeezicht bijvoorbeeld niet plotseling verandert in een warme zonsondergang.
Leren verbeteren door proef en fout
Het systeem gaat een stap verder door diepe reinforcement learning te gebruiken, een techniek geïnspireerd op leren door vallen en opstaan. Hier behandelt een aparte beslissingsmodule het verschil tussen de huidige output en de doelbegeleiding als zijn “staat” en stelt kleine aanpassingen voor aan elementen zoals schetssterkte of paletgewichten als zijn “acties”. Na elke wijziging meet het systeem hoeveel belangrijke beeldkwaliteitscores verbeteren—zoals peak signal-to-noise ratio, structurele gelijkenis en stijlverlies—en gebruikt dit als een beloningssignaal. In de loop van de tijd leert deze lus een beleid dat de begeleiding automatisch verfijnt om de generator naar beelden te sturen die zowel visueel trouw als artistiek consistent zijn.
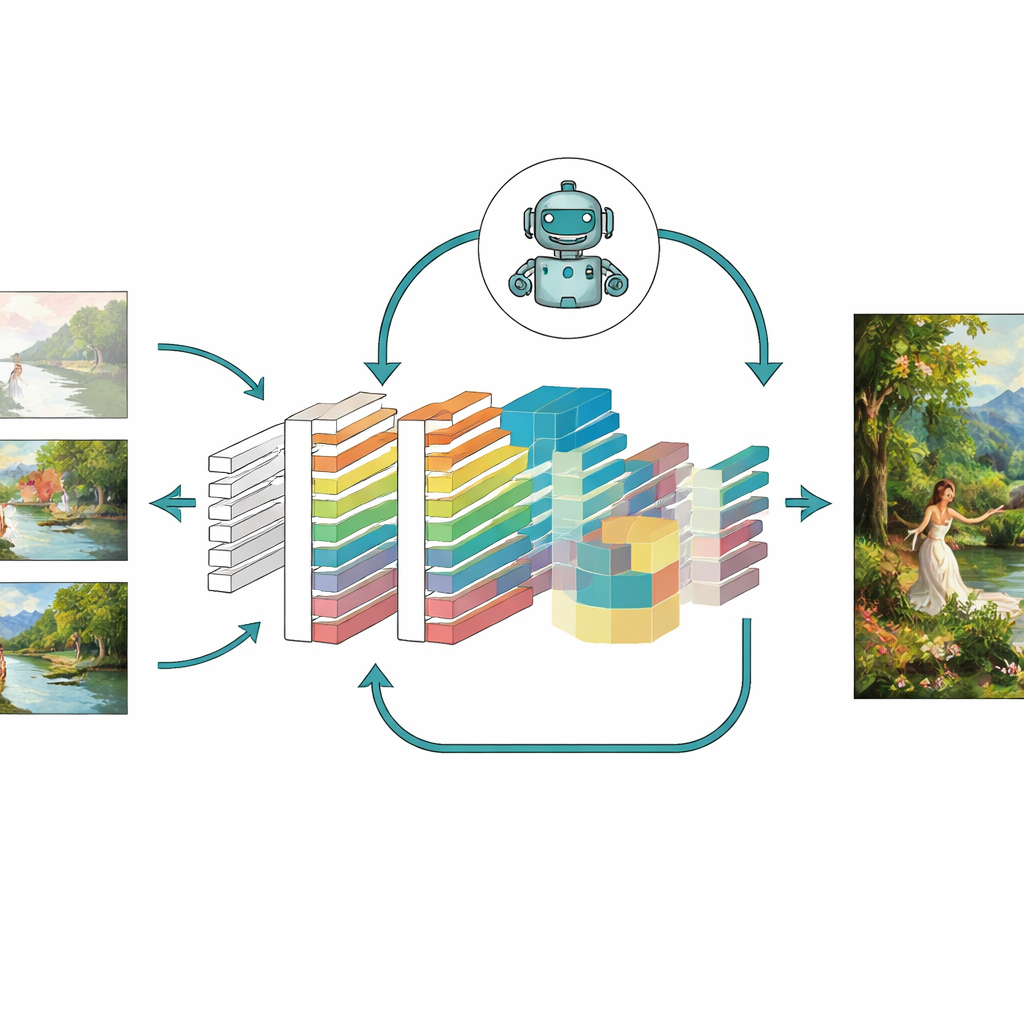
Het model op de proef stellen
Om te beoordelen of deze ideeën werkelijk helpen, testten de auteurs hun verbeterde model—genoemd CNN-GAN—op een grote collectie schilderijen van de Universiteit van Oxford en op een aangepaste set van meer dan 5.000 kleurwerken in stijlen zoals portretten, landschappen en abstracte taferelen. Ze vergeleken de resultaten met verschillende bekende systemen, waaronder klassieke GAN-varianten, auto-encoders en zelfs moderne diffusion-based generators. Over vele maatstaven produceerde het nieuwe model scherpere beelden met minder artefacten, een nauwere structurele overeenkomst met echte kunstwerken, een lagere perceptuele afstand tot doelbeelden en een grotere diversiteit in de soorten scènes die het kon genereren. Ablatiestudies, waarbij telkens één module werd verwijderd, toonden aan dat aandacht, reinforcement learning en het gecombineerde verliesontwerp elk betekenisvolle verbeteringen bijdroegen en samen de sterkste prestaties leverden.
Wat dit betekent voor toekomstige creatieve hulpmiddelen
In alledaagse bewoordingen beschrijft het artikel een schildermachine die niet alleen leert van duizenden kunstwerken, maar ook speciale aandacht schenkt aan belangrijke regio’s, luistert naar visuele aanwijzingen van gebruikers en zichzelf geleidelijk leert hoe die aanwijzingen beter af te stemmen voor betere resultaten. Het resultaat is een AI die consistenter hoge kwaliteit en stylistisch eenduidige afbeeldingen kan genereren dan eerdere methoden, terwijl er toch ruimte blijft voor menselijke sturing. Hoewel het systeem nog steeds moeite heeft met uiterst ingewikkelde texturen en afhankelijk is van aanzienlijke trainingsdata, suggereren de auteurs toekomstige uitbreidingen—zoals multiscale-modules en lichtere netwerken—om het efficiënter en breder toepasbaar te maken. Gezamenlijk wijzen deze ontwikkelingen op AI-kunsthulpmiddelen die sneller zijn, trouwere weergave van gebruikersintentie bieden en beter in staat zijn het subtiele karakter van door mensen gemaakte schilderijen vast te leggen.
Bronvermelding: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Trefwoorden: AI-kunstgeneratie, beeldstijltransformatie, generatieve adversariële netwerken, kunstmatige creativiteit, neurale beeldsynthese