Wanneer overheden, wetenschappers of peilers iets willen weten over een gehele populatie—zoals het gemiddelde inkomen, de opbrengst van gewassen of vervuilingsniveaus—kunnen ze zelden iedereen meten. In plaats daarvan trekken ze een steekproef en schalen die op. Dit werkt goed alleen als de data zich netjes gedragen. In de praktijk zitten enquêtes en metingen echter vol fouten en extreme waarden die de resultaten sterk kunnen vertekenen. Dit artikel introduceert een nieuwe manier om populatiegemiddelden te berekenen die betrouwbaar blijft ook wanneer de data rommelig zijn, waardoor op steekproef gebaseerde beslissingen beter te vertrouwen zijn.
Wanneer simpele gemiddelden misgaan
Standaardinstrumenten voor de schatting van een populatiegemiddelde, zoals het eenvoudige steekproefgemiddelde of gewone regressie, veronderstellen dat de meeste datapunten zich volgens vloeiende patronen gedragen, zonder extreme uitbijters of ongebruikelijke gevallen. In sociale en economische enquêtes, milieumonitoring en landbouwstatistieken wordt aan die verwachting vaak niet voldaan. Enkele foutieve metingen, zeldzame maar extreme gebeurtenissen of verkeerd gerapporteerde antwoorden kunnen schattingen van de waarheid wegtrekken en zowel vertekening als onzekerheid vergroten. Eerder werk probeerde de impact van zulke uitbijters te verminderen met zogenoemde robuuste methoden, waaronder de bekende Huber M-estimatie. Hoewel nuttig, beschermen deze methoden vooral tegen extreme waarden in de uitkomstvariabele en blijven ze kwetsbaar voor ongebruikelijke patronen in de begeleidende verklarende informatie.
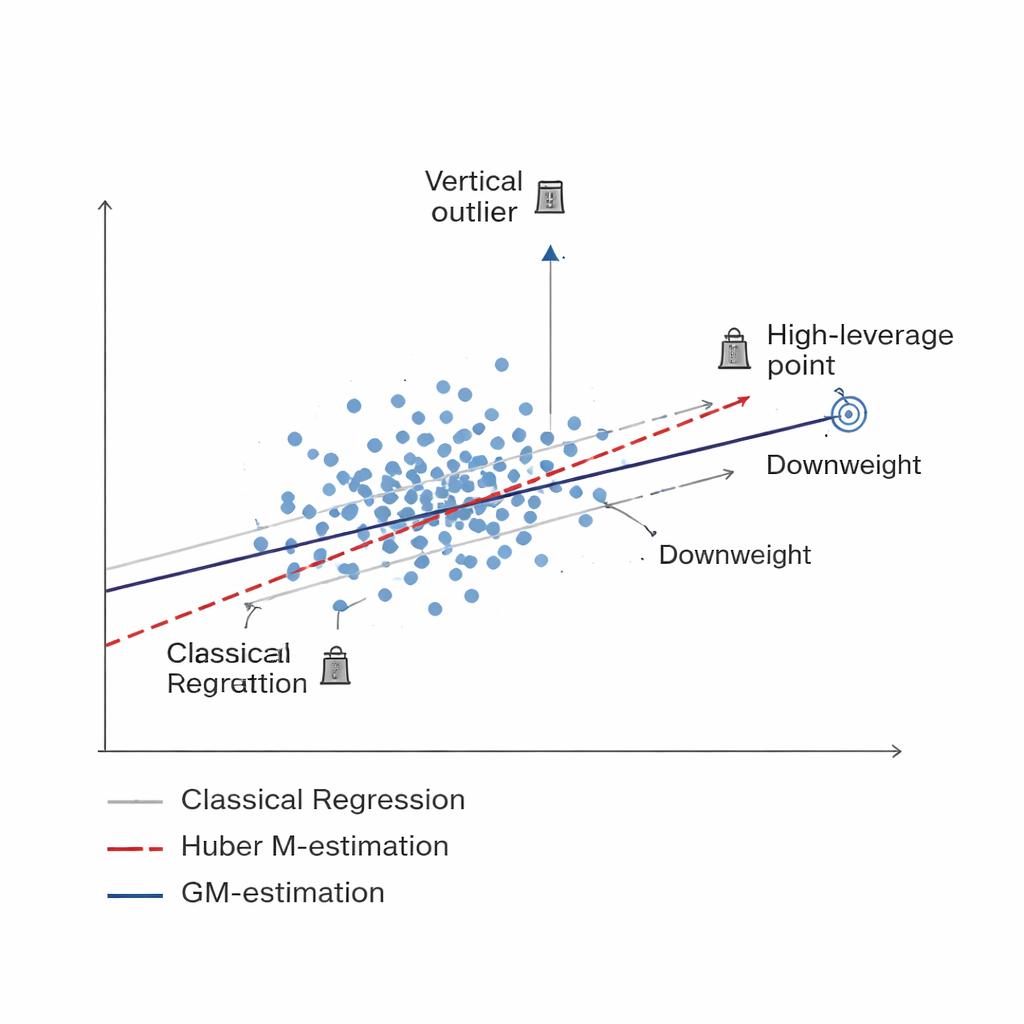
Een slimmer manier om slechte data te verzwakken Figure 1.
De studie ontwikkelt een nieuwe familie van schatters gebaseerd op Generalized M-estimation, of GM-estimatie. In plaats van elk bemonsterd element gelijk te behandelen, kennen GM-methoden adaptieve gewichten toe die afhankelijk zijn van twee dingen tegelijk: hoe extreem de waarneming van een element is (een verticale uitbijter) en hoe ongewoon de bijbehorende informatie is (een high-leverage punt). Drie specifieke varianten—Mallows-GM, Schweppes-GM en SIS-GM—zijn ontworpen voor veelvoorkomende steekproefopstellingen, waaronder eenvoudige aselecte steekproeftrekking zonder teruglegging en complexere gestratificeerde designs waarbij de populatie in relatief uniforme groepen is verdeeld. Door beide typen problematische observaties gezamenlijk te controleren, streven deze schatters ernaar de uiteindelijke schatting van het populatiegemiddelde stabiel te houden, zelfs wanneer de data ernstige besmetting bevatten.
De nieuwe schatters op de proef stellen
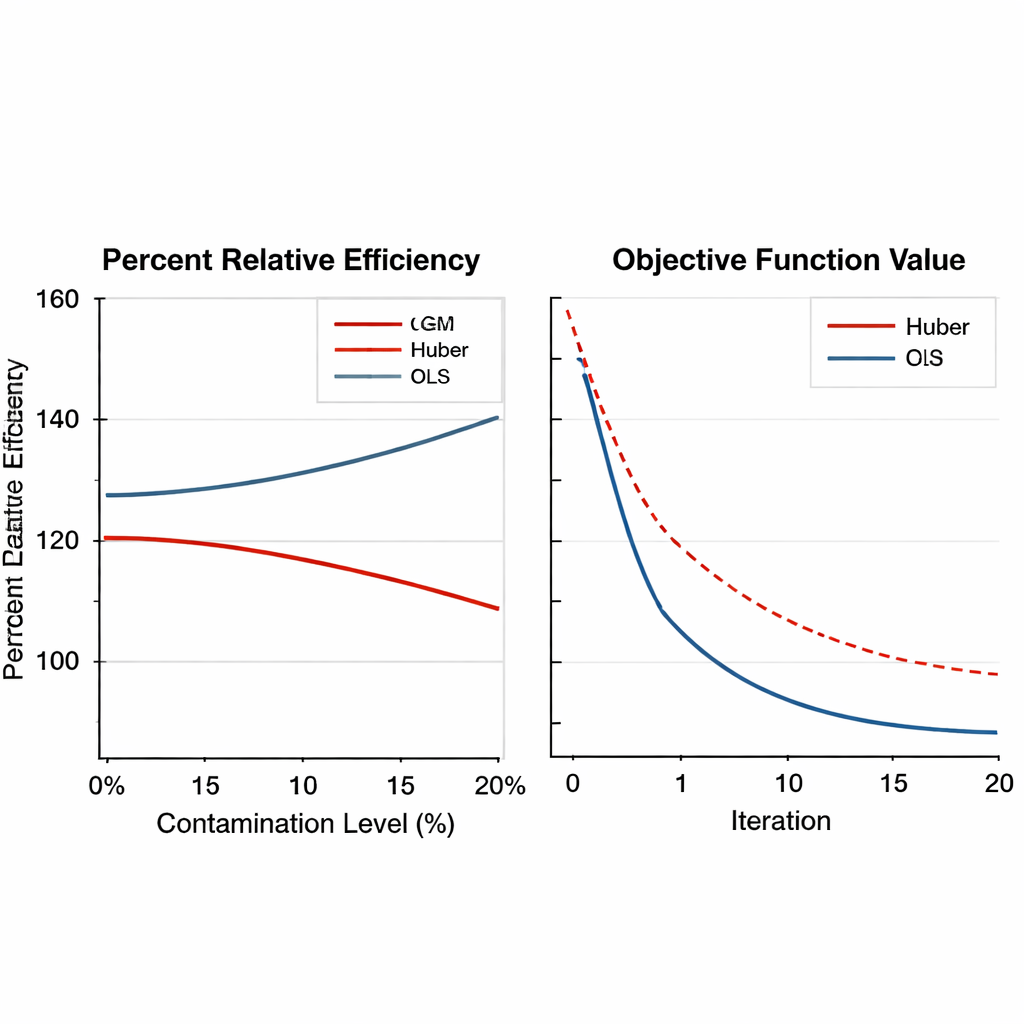
Om te onderzoeken hoe goed de op GM gebaseerde schatters werken, voert de auteur uitgebreide numerieke experimenten uit. Eerst worden echte gegevens uit de tabakslandbouw geanalyseerd in twee vormen: een schone versie en een opzettelijk vervuilde versie waarbij één element is vervangen door extreme waarden. De nieuwe schatters worden vergeleken met traditionele regressie en Huber-gebaseerde robuuste methoden met behulp van een maat genaamd percentuele relatieve efficiëntie, die aangeeft hoeveel kleiner de schattingsfout is. Over een breed scala aan steekproefgroottes presteren de GM-schatters consistent beter dan de oudere methoden, vooral wanneer de data extreme waarden bevatten. In sommige scenario’s reduceert de best presterende GM-schatting de fout met meer dan 50 procent vergeleken met de Huber-aanpak.
Robuustheid over designs, omstandigheden en afstemmingskeuzes Figure 2.
Het paper breidt vervolgens de tests uit met grootschalige computersimulaties. Kunstmatige populaties worden gegenereerd onder verschillende distributievormen—normaal, scheef en heavy-tailed—en vervuild met uiteenlopende fracties uitbijters, van geen tot 20 procent. Zowel eenvoudige als gestratificeerde steekproefplannen worden beschouwd, en de sterkte van de relatie tussen de hoofdvariabele en de hulpvariabelen varieert van zwak tot sterk. De GM-schatters behouden niet alleen hun voorsprong bij zware besmetting, vaak met efficiëntiewinsten boven de 150 procent, maar vertonen ook een vloeiende en betrouwbare numerieke convergentie. Belangrijk is dat hun prestatie weinig verandert wanneer de interne afstemmingsinstellingen binnen redelijke grenzen worden aangepast, wat betekent dat beoefenaars ze niet voor elke nieuwe enquête tot in het kleinste detail hoeven bij te stellen.
Wat dit betekent voor enquêtes in de praktijk
Simpel gezegd laat het artikel zien dat de voorgestelde GM-gebaseerde schatters een veiligere manier bieden om onvolmaakte steekproeven om te zetten in schattingen van populatiebrede gemiddelden. Onder ideale, schone datatoestanden zijn ze ongeveer even nauwkeurig als klassieke methoden. Maar wanneer de data meetfouten, verkeerd gerapporteerde waarden of zeldzame extreme gebeurtenissen bevatten—zoals vaak voorkomt in nationale enquêtes, milieumonitoring en financiële statistieken—leveren ze aanzienlijk betrouwbaardere uitkomsten. Omdat ze computationeel haalbaar zijn en goed werken over verschillende designs en omstandigheden, bieden deze schatters praktijkmensen een praktische upgrade die bewijsgestuurde beslissingen bestendiger kan maken tegen de onvermijdelijke rommeligheid van data uit de echte wereld.
Bronvermelding: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
Trefwoorden: steekproefonderzoek, robuuste schatting, uitbijters, generalized M-estimation, gemiddelde van een eindige populatie