Clear Sky Science · nl
Blinde herkenning van kanaalcodes gebaseerd op dual-branch feature-fusie convolutionele neurale netwerken
Slimmere radio’s voor drukke ether
Draadloze netwerken raken voller nu telefoons, sensoren en voertuigen allemaal om dezelfde ether concurreren. Om chaos te voorkomen zullen toekomstige “cognitieve radio’s” eerst moeten luisteren en dan op intelligente wijze spectrum delen dat al door anderen gebruikt wordt. Een belangrijk probleem is dat deze radio’s vaak niet weten hoe het oorspronkelijke signaal voor verzending tegen fouten beschermd is. Dit artikel introduceert een nieuwe kunstmatige-intelligentie-methode die de verborgen foutcorrigerende code op een signaal kan achterhalen—zonder enige voorkennis—wat het voor slimme ontvangers makkelijker maakt zich te synchroniseren en betrouwbaar te communiceren.
Waarom verborgen foutcorrigerende codes ertoe doen
Moderne draadloze verbindingen beschermen gegevens met foutcorrigerende codes, die zorgvuldig gestructureerde redundantie toevoegen zodat ontvangers fouten door ruis en interferentie kunnen herstellen. Verschillende omstandigheden vragen om verschillende codes: eenvoudige Hamming-codes, krachtigere BCH- en Reed–Solomon-codes, flexibele LDPC- en Polar-codes, of streaming-achtige convolutionele en Turbo-codes. In niet-coöperatieve situaties—zoals militaire communicatie, spectrumtoezicht of open gedeelde banden—kan een ontvanger een zender niet vragen welke code wordt gebruikt. Ze zien alleen een verstoorde stroom bits. Het correct raden van het coderingsschema, een taak die blinde coderekognition heet, is essentieel voordat zinvolle decodering of hogere verwerkingsstappen mogelijk zijn.
Beperkingen van eerdere herkenningsmethoden
Eerdere onderzoeken richtten zich ofwel telkens op één codefamilie of vertrouwden op handgemaakte statistieken zoals hoe vaak bits zich herhalen, hoe willekeurig een reeks eruitziet, of algebraïsche trucs toegespitst op een specifieke code. Deze benaderingen kunnen aangeven “dit is een soort blokcode”, maar hebben moeite om meerdere populaire formaten tegelijk te onderscheiden. Deep learning verbeterde de zaak door bitstromen deels te behandelen als zinnen in een taalmodel. Toch kijken de meeste neurale netwerken ofwel alleen naar ruwe sequenties ofwel alleen naar handmatig ontworpen features, en kunnen doorgaans hooguit twee of drie codetypes tegelijk aan. Hun nauwkeurigheid daalt scherp als het bitfoutpercentage stijgt — precies wanneer robuuste herkenning het meest nodig is.
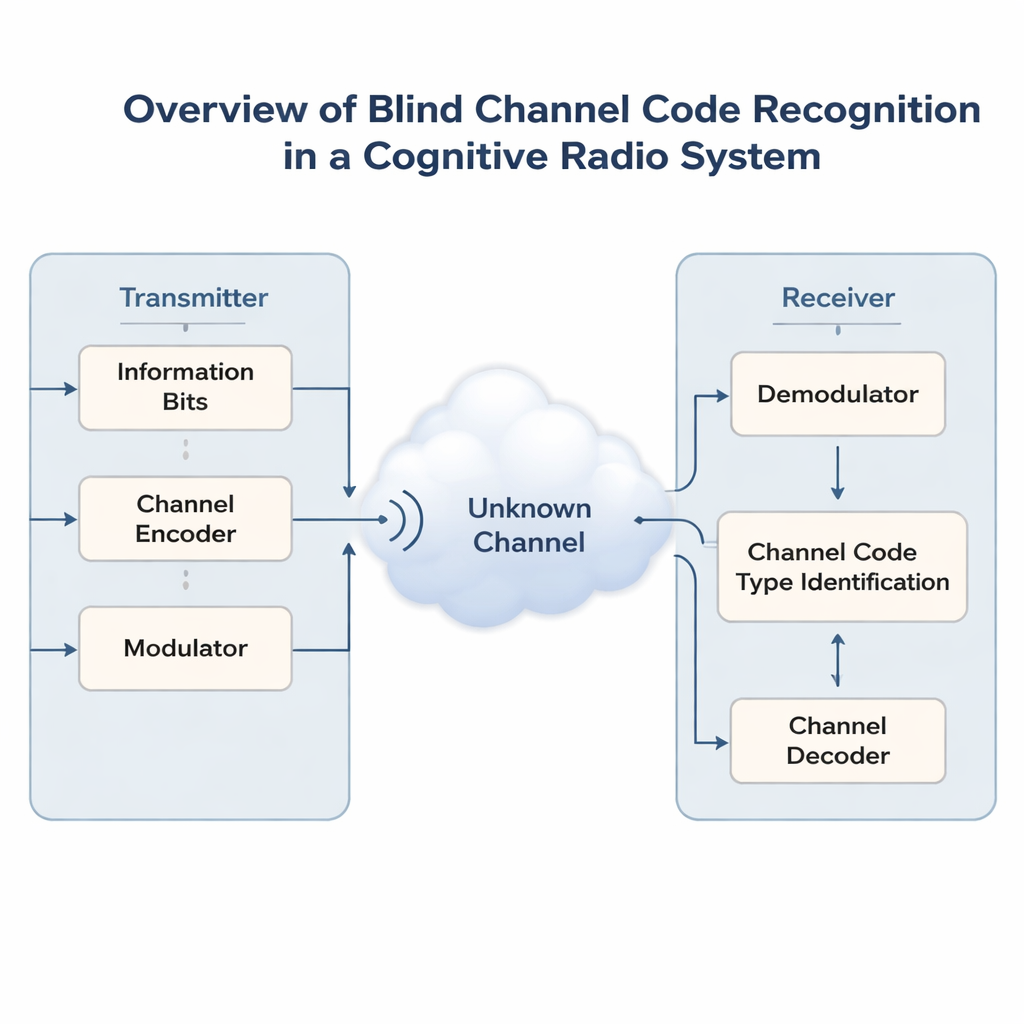
Een tweesporig neuraal netwerk dat naar structuur en statistiek kijkt
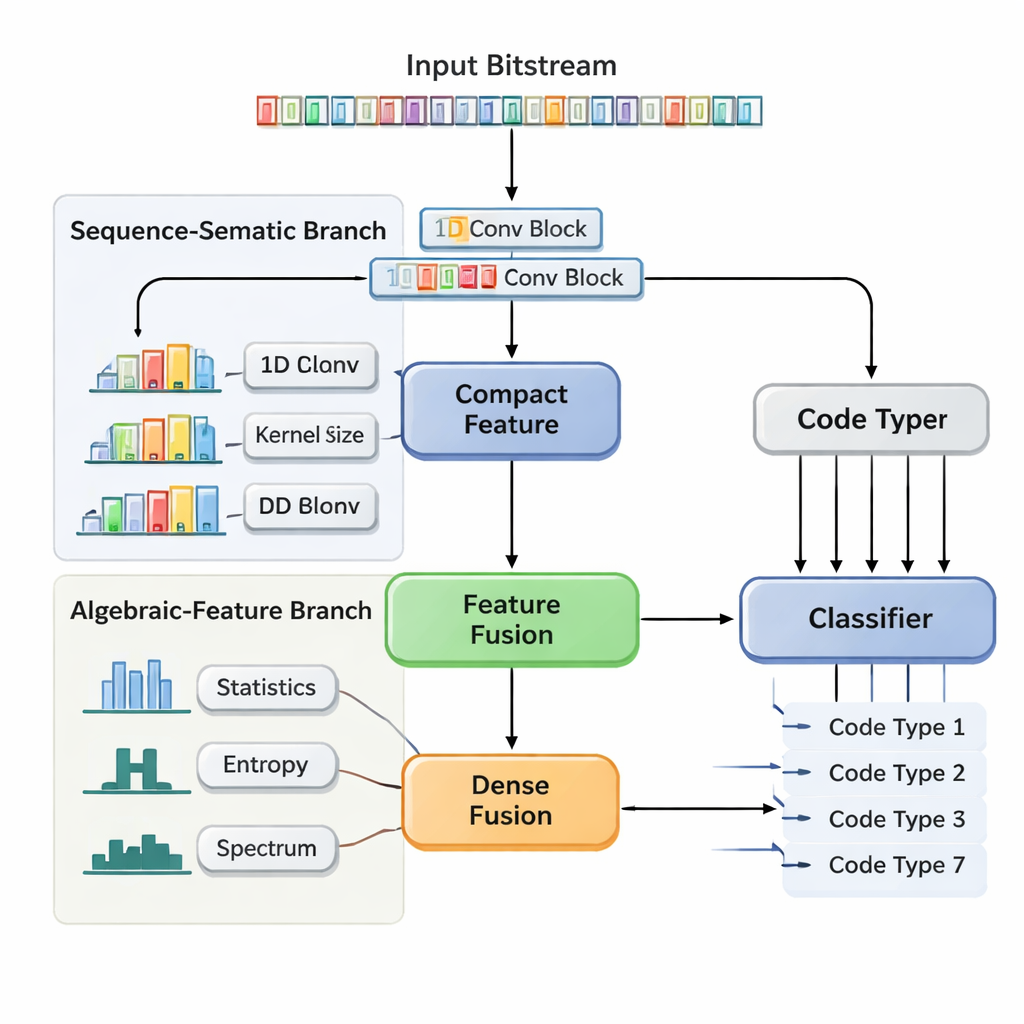
De auteurs stellen een Dual-Branch Feature Fusion Convolutional Neural Network (DBFCNN) voor dat blinde herkenning van zeven veelgebruikte codes in één keer aanpakt: Hamming, BCH, Reed–Solomon, LDPC, Polar, convolutionele en Turbo-codes. De eerste tak behandelt de binnenkomende bits als korte “woorden”, groepeert ze in 8-bit blokken en zet elk blok om in een dichte vector, vergelijkbaar met woord‑embeddings in natuurlijke taalverwerking. Vervolgens past het een reeks eendimensionale convoluties toe met verschillende venstergroottes en dilatatie-snelheden. Kleine filters vangen patronen op korte afstand op, zoals de strakke structuur van eenvoudige blokcodes, terwijl grotere en gedilateerde filters langere reeksen overspannen en sporen oppikken van interleavers en pariteitsstructuren die typisch zijn voor Turbo- en LDPC-codes. Een globale poolingstap perst dit samen tot een compact samenvattend ‘vingerafdruk’ van de sequentiestructuur.
Handgemaakte metingen die het model stabiliseren
De tweede tak neemt een heel ander perspectief. In plaats van ruwe bits berekent deze zeven families beschrijvende statistieken waarvan ingenieurs weten dat ze gevoelig zijn voor coderingkeuzes. Deze omvatten hoe vaak runs van identieke bits voorkomen, hoe complex de sequentie is, hoe willekeurig ze lijkt, hoe sterk ze correleert met verschoven kopieën van zichzelf en hoe de energie over frequenties verdeeld is. Extra maten onderzoeken hoe “lineair” de code lijkt en hoe lokale bitblokken zich gedragen. Omdat deze statistieken langzaam veranderen met toenemende ruis bieden ze het netwerk een stabiel, ruisbestendig perspectief. Een klein neuraal sub-netwerk zet deze featurevector om in een andere compacte representatie. Uiteindelijk concateneert DBFCNN de twee takken, normaliseert en regulariseert de gecombineerde features en voert ze naar een classifier die kansen voor elk van de zeven codetypes uitzendt.
Betrouwbaarheid aantonen onder rumoerige omstandigheden
Om DBFCNN grondig te testen genereerden de auteurs meer dan een miljoen synthetische voorbeelden die zeven codefamilies, meerdere parameterinstellingen en bitfoutpercentages bestrijken van vrijwel foutloos tot extreem rumoerig. Ze trainden en testten het model met zorgvuldige Monte Carlo-procedures om verborgen overlap tussen trainings- en testgegevens te vermijden. Over dit brede bereik presteerde DBFCNN consequent beter dan drie sterke referentiemodellen, inclusief een eerder ontworpen multiscale gedilateerd CNN specifiek voor deze taak. Bij matige en lage foutpercentages (bitfoutpercentage onder 10⁻³) identificeerde het nieuwe netwerk ongeveer 98% van de tijd correct het codetype, een absolute verbetering van ruwweg 5–11 procentpunt ten opzichte van het sterkste eerdere model. Zelfs bij vrij hoge ruisniveaus behield DBFCNN een duidelijk voordeel en kon het meerdere complexe codes nog met hoge zekerheid herkennen.
Wat dit betekent voor toekomstige slimme radio’s
Voor niet‑experts is de kernboodschap dat dit werk laat zien hoe het combineren van domeinkennis met deep learning radio’s veel zelfstandiger kan maken. DBFCNN leert het subtiele “accent” van verschillende foutcorrigerende codes in rumoerige bitstromen door op twee manieren tegelijk te luisteren: de ene tak hoort gedetailleerde lokale patronen, de andere meet globale statistische aanwijzingen. Door deze gezichtspunten te fuseren kan het systeem meestal precies bepalen welk coderingsschema wordt gebruikt, zonder medewerking van de zender. Die vaardigheid is een bouwsteen voor cognitieve radio’s die zich bij onbekende netwerken kunnen voegen, zich aan veranderende omstandigheden kunnen aanpassen en beter gebruik kunnen maken van schaarse spectrumruimte, terwijl communicatie betrouwbaar blijft zelfs wanneer de ether druk en rumoerig is.
Bronvermelding: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
Trefwoorden: cognitieve radio, kanaalcodering, deep learning, foutcorrectie, signaalclassificatie