Clear Sky Science · nl
Nauwkeurige generatie van ontslagbrieven met behulp van fijn-afgestelde grote taalmodellen en zelfevaluatie
Waarom administratie in het ziekenhuis echt belangrijk is
Wanneer een patiënt het ziekenhuis verlaat, eindigt het verhaal van zijn ziekte niet bij de uitgang. Artsen in andere klinieken, huisartsen en de patiënten zelf zijn allen afhankelijk van een sleutelstuk documentatie, de ontslagbrief, om te begrijpen wat er in het ziekenhuis is gebeurd en wat de volgende stappen zijn. Het opstellen van deze samenvattingen is echter langzaam, repetitief werk dat drukke zorgverleners vaak een half uur of langer per patiënt kost. Deze studie onderzoekt hoe moderne AI-taalhulpmiddelen kunnen helpen ontslagbrieven sneller en nauwkeuriger op te stellen, terwijl patiëntgegevens privé blijven en onder controle van het ziekenhuis blijven.
Verspreide dossiers omzetten in een helder verhaal
Ziekenhuisinformatie is verspreid over veel elektronische systemen: laboratoriumuitslagen in de ene tabel, operatierapporten in een andere, verpleegkundige observaties in weer een andere, enzovoort. Het verblijf van elke patiënt genereert duizenden kleine tekstfragmenten. De onderzoekers bouwden eerst een pijplijn om deze verspreide, rommelige informatie om te zetten in schone input die een AI-model kan begrijpen. Met methoden om overlappende records samen te voegen en te dedupliceren, privégegevens zoals namen en ID's te filteren, spel- en taalfouten te corrigeren en medische termen te standaardiseren, creëerden ze gestructureerde input voor elk ziekenhuisverblijf. Dit proces werd toegepast op gegevens van meer dan 6.000 schildklieroperatiepatiënten in een groot Chinees ziekenhuis, waarmee gepaarde voorbeelden werden geproduceerd van echte ontslagbrieven en de ruwe data waaruit ze waren geschreven. 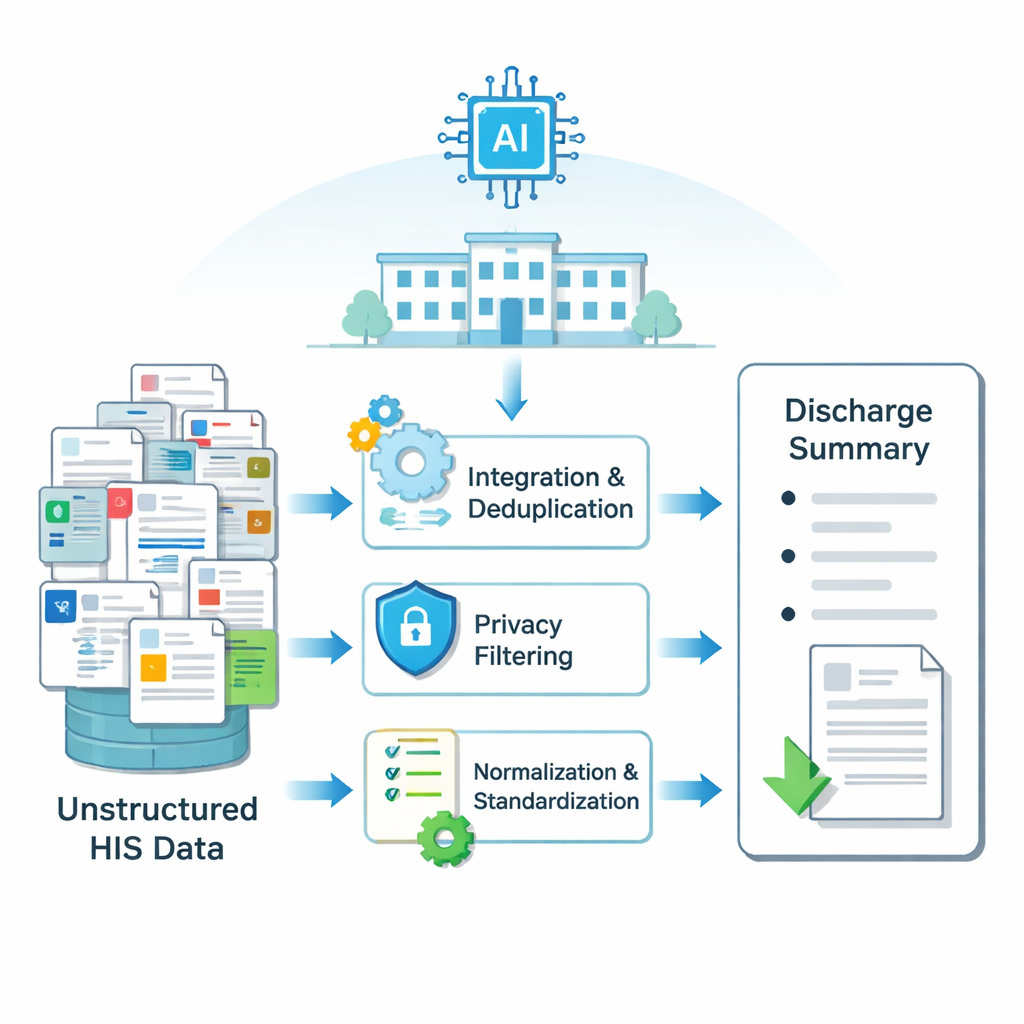
AI fijn afstemmen op de taal van de geneeskunde
Standaard grote taalmodellen zijn getraind op algemene tekst van het internet en boeken, dus ze hebben vaak moeite met gespecialiseerde medische terminologie en lokale documentatiestijlen. Het team vergeleek verschillende manieren om bestaande modellen te "fijn-afstemmen" zodat ze Chinese medische dossiers beter begrijpen. Een nieuwe methode, weight-decomposed low-rank adaptation of DoRA genoemd, past de interne gewichten van het model gerichter aan dan oudere technieken zoals LoRA en QLoRA. Over verschillende modellen heen, waaronder Qwen2, Mistral en Llama 3, leverde DoRA consistent samenvattingen die vloeiender waren, dichter bij menselijk geschreven versies in betekenis lagen en minder verwarring vertoonden (gemeten met een standaardmaat genaamd perplexity). In wezen hielp DoRA de AI medische formuleringen en terminologie aan te leren zonder dat volledige hertraining op enorme hardware nodig was.
De AI leren om het eigen werk te controleren
Zelfs een goed getraind model kan belangrijke details vergeten of kleine fouten invoeren wanneer het in één keer een lange samenvatting schrijft. Geïnspireerd door psychologische ideeën over snelle "Systeem 1"-denkprocessen versus langzamere, zorgvuldige "Systeem 2"-redenering, ontwierpen de auteurs een zelfevaluatie-lus. Eerst schrijft het model een initiële ontslagbrief op basis van de verwerkte ziekenhuisgegevens. Daarna worden de oorspronkelijke gegevens in segmenten verdeeld—zoals pathologievondsten, doktersvoorschriften of labpanelen—en wordt elk segment opnieuw gekoppeld aan de conceptsamenvatting. Het model krijgt in feite de vraag: "Is alles in dit segment terug te vinden in de samenvatting?" Zo niet, dan herschrijft het de tekst om ontbrekende of inconsistente informatie toe te voegen. Deze cyclus herhaalt zich tot drie keer of totdat het model de samenvatting als compleet beoordeelt, wat resulteert in een verfijnde versie die trouwere overeenstemming heeft met het patiëntendossier. 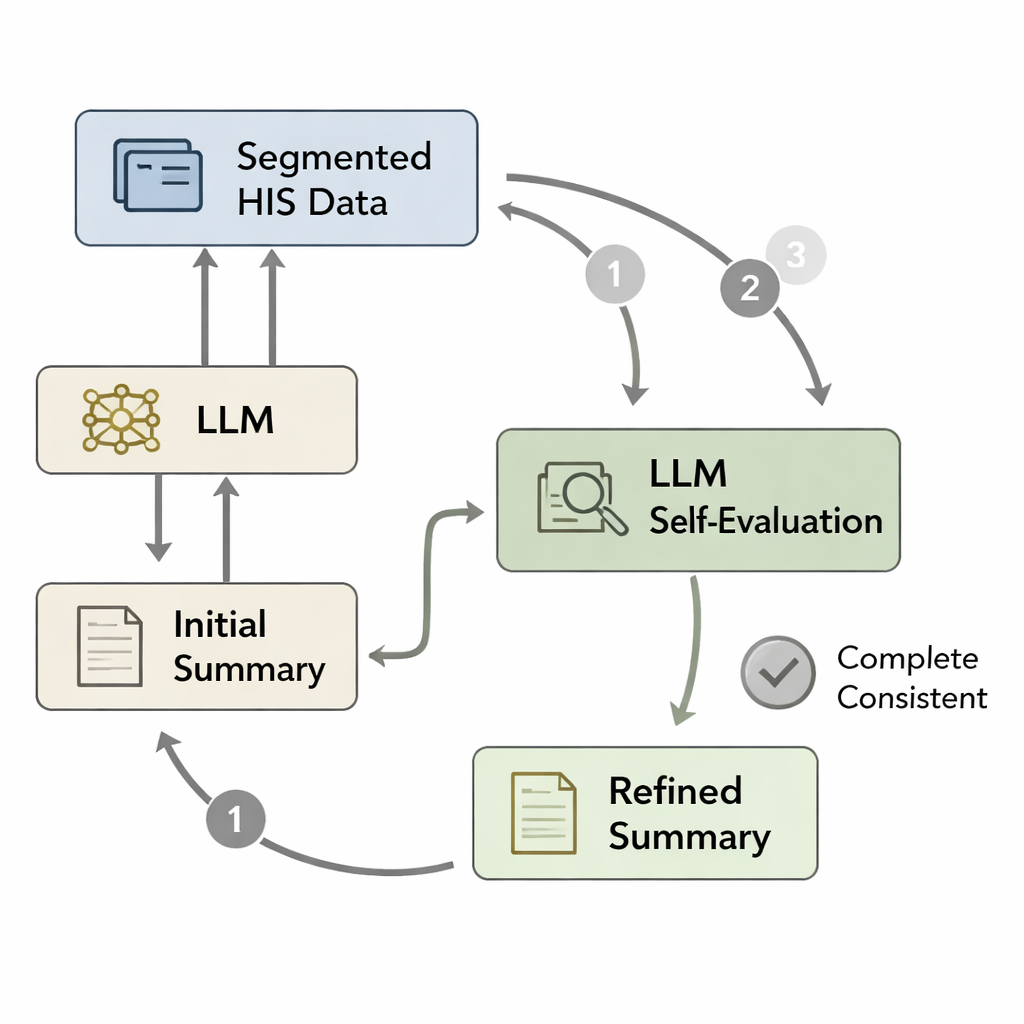
Hoe goed presteerde de AI vergeleken met mensen?
Om de kwaliteit te beoordelen gebruikte het team zowel automatische scores als menselijke beoordelaars. Artsen en medische onderzoekers beoordeelden samenvattingen op nauwkeurigheid, volledigheid, duidelijkheid, consistentie en bruikbaarheid voor vervolgzorg. Het beste systeem—een combinatie van DoRA-fijnafstemming en de zelfevaluatie-lus—kwam in alle categorieën het dichtst bij menselijk geschreven ontslagbrieven. Het verbeterde vooral de volledigheid, wat betekent dat er minder gemiste diagnoses, behandelingen of belangrijke labwaarden waren. In een gedetailleerd voorbeeld vergat de AI aanvankelijk het noemen van een kleine schildklierkanker en een specifiek hormoonpilletje; na twee zelfevaluatierondes werden beide details correct toegevoegd. Gemiddeld genereerde het systeem een ontslagbrief in ongeveer 80 seconden op een ziekenhuisserver, vergeleken met 30–50 minuten voor een zorgverlener om er een vanaf nul op te stellen, hoewel menselijke controle essentieel blijft voordat de tekst in het officiële dossier komt.
Wat dit kan betekenen voor patiënten en zorgverleners
De studie laat zien dat AI-systemen, met zorgvuldige training en ingebouwde zelfcontrole, ontslagbrieven kunnen produceren die na een korte menselijke controle klinisch acceptabel zijn. Dit vervangt artsen niet, maar kan hun tijd verplaatsen van routinematig typen naar hogere-orde review en besluitvorming. Door alle berekeningen binnen het ziekenhuisnetwerk te houden en identificerende gegevens te verwijderen, respecteert de aanpak ook de privacy van patiënten. Hoewel de resultaten tot nu toe uit één afdeling in één ziekenhuis komen, wijst het kader op een toekomst waarin AI helpt complexe medische gegevens om te zetten in heldere, betrouwbare verhalen in veel specialismen, wat veiligere overdrachten in de zorg en betere begrijpelijkheid voor patiënten en families ondersteunt.
Bronvermelding: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Trefwoorden: ontslagbrieven, medische AI, grote taalmodellen, klinische documentatie, zelfevaluatie