Clear Sky Science · nl
Sociale gebruikersgeolocatie gebaseerd op K-medoids en Gaussian Kernel graph attention network
Waarom je tweets kunnen onthullen waar je woont
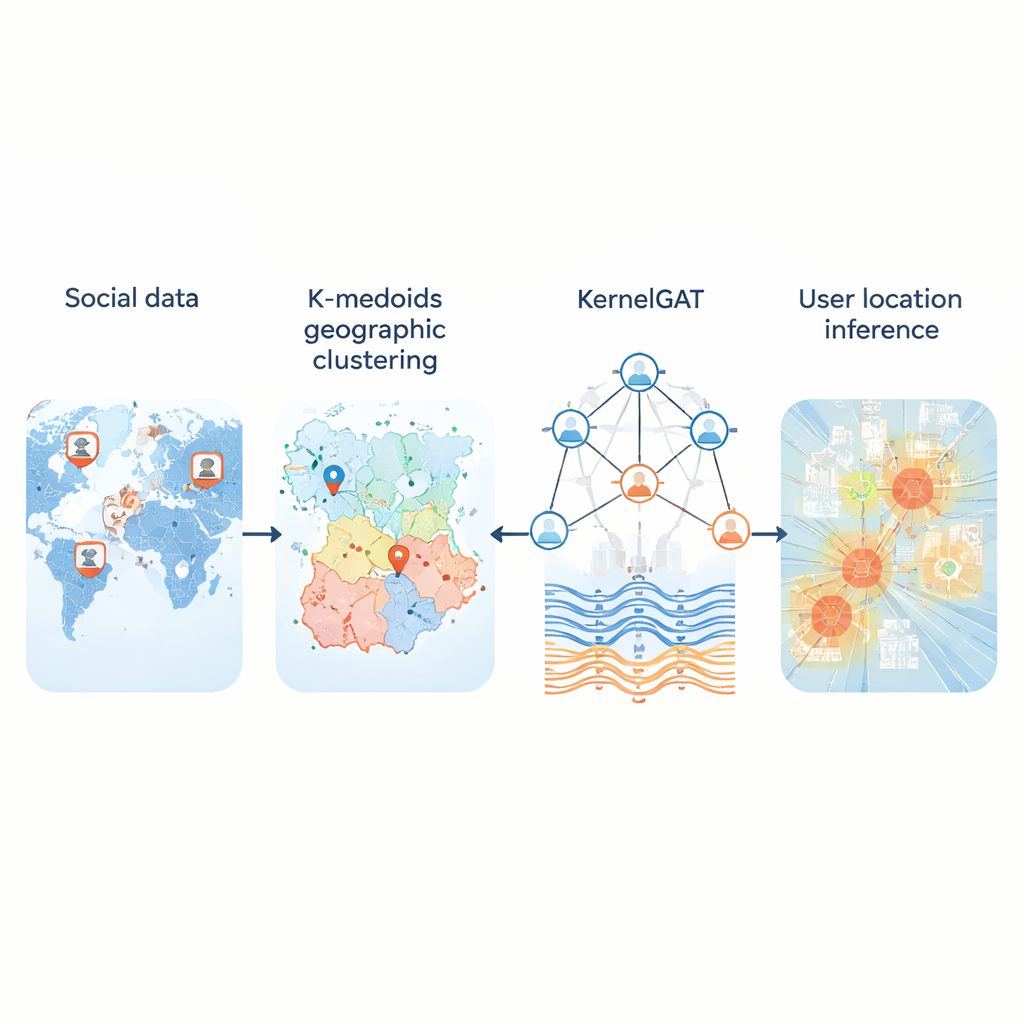
Elke dag plaatsen miljoenen mensen berichten op sociale media zonder hun GPS-coördinaten te delen. Toch laten die berichten aanwijzingen achter over waar gebruikers wonen, werken en reizen. Het kunnen afleiden van locatie uit dit openbare spoor is belangrijk voor alles van noodhulp en ziektebewaking tot lokale aanbevelingen en gerichte diensten. Dit artikel introduceert een nieuwe methode, KMKGAT genoemd, die zowel wat mensen zeggen als hoe ze online met elkaar verbonden zijn gebruikt om hun locatie te schatten, en dat nauwkeuriger dan eerdere benaderingen.
Van online geklets naar echte plaatsen
Wanneer gebruikers tweets of microblogs schrijven, kunnen ze plaatsnamen noemen, lokale termen gebruiken of contact hebben met nabije vrienden. Bedrijven zoals Twitter (nu X) kennen het internetadres van een gebruiker, maar externe onderzoekers en serviceproviders meestal niet. Zij moeten werken met openbare informatie: de tekst zelf, gebruikersprofielen en wie met wie communiceert. Eerdere methoden vielen in drie categorieën. Alleen-inhoudsmethoden haalden woorden en hashtags uit berichten om locaties te raden. Alleen-netwerkmethoden vertrouwden op het feit dat mensen vaak met dichtbij gelegen gebruikers interacteren. Een derde, krachtigere familie combineerde beide perspectieven, maar had nog steeds blinde vlekken — vooral voor mensen in dunbevolkte gebieden en voor gebruikers wiens online verbindingen grote afstanden overspannen.
Slimmere geografische groepering met echte gebruikerscentra
Een belangrijk probleem is hoe je de continue aarde omzet in een reeks regio’s die een computer kan leren voorspellen. Veel systemen delen de kaart op in een vast raster. Dat werkt redelijk in steden maar faalt in landelijke gebieden, waar enorme cellen vele honderden kilometers bestrijken. De nieuwe methode vervangt starre rasters door k-medoids-clustering, een manier om gebruikers te groeperen zodat elke regio wordt gecentreerd rond een echte gebruiker in plaats van een kunstmatig punt. Dit maakt de regio’s compact en minder gevoelig voor uitschieters, met name waar gebruikers schaars zijn. In tests op drie grote Twitter-datasets die de Verenigde Staten en de wereld beslaan, verminderde deze adaptieve partitionering de typische fouten vergeleken met rastergebaseerde schema’s en leverde het realistischere “thuisregio’s” voor gebruikers op.
De netwerkfocus op nabije, vergelijkbare gebruikers laten liggen
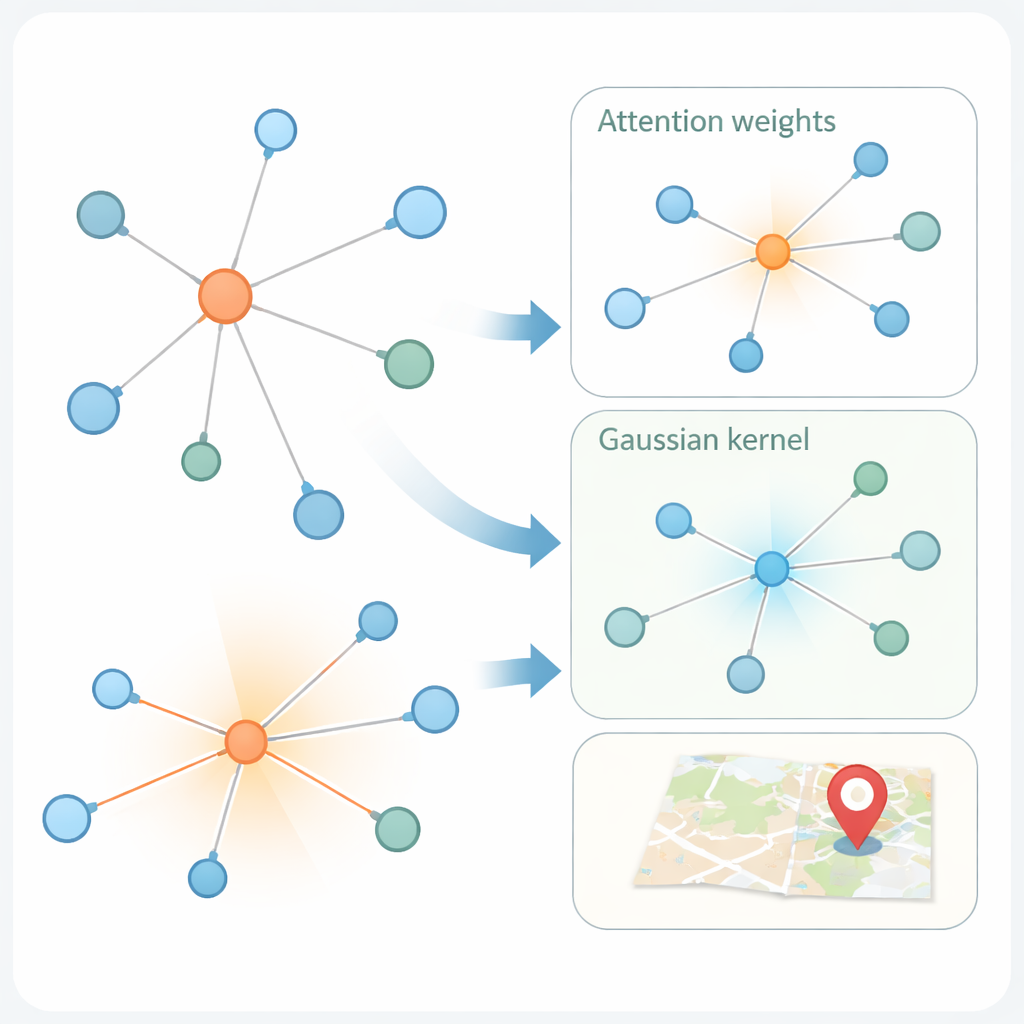
De tweede innovatie ligt in hoe het model leert van de sociale grafiek. Moderne “graph attention networks” wegen al de buren van een gebruiker verschillend, op basis van hoe vergelijkbaar hun kenmerkrepresentaties zijn. Maar alleen gelijkenis kan misleidend zijn: een account in New York en een ander in Londen kunnen vergelijkbare taal gebruiken maar ver van elkaar verwijderd zijn. KMKGAT breidt attention uit met een Gaussian-kernel, een wiskundig filter dat buren bevoordeelt waarvan de geleerde kenmerken dicht bij die van de doelfiguur liggen en de invloed van verre buren dempt. Meerdere zulke kernels, gecombineerd als een mengsel van lenzen, stellen het model in staat om localiteit op verschillende schalen vast te leggen. Dit respecteert het eenvoudige maar krachtige principe dat online interacties vaak het sterkst zijn tussen mensen die fysiek dichter bij elkaar zijn.
Lichte tekstkenmerken die toch locatiehint geven
In plaats van te vertrouwen op zware deep-language-modellen, die moeite kunnen hebben met de rumoerige, vol slang zijnde stijl van tweets, gebruiken de auteurs een klassieke techniek genaamd TF–IDF om de verzameling berichten van elke gebruiker om te zetten in een zak gewogen trefwoorden. Veelvoorkomende woorden zoals “de” of “lol” krijgen weinig gewicht, terwijl zeldzamere, regiogebonden termen naar boven komen. Deze tekstkenmerken worden vervolgens aan elke gebruiker in de sociale grafiek gekoppeld en door het verbeterde attention-netwerk geleid. Interessant genoeg leverden de beste resultaten op toen tijdens het trainen de meeste tekstkenmerken willekeurig werden weggelaten, wat suggereert dat slechts een klein deel van de woorden daadwerkelijk helpt bij locatiebepaling en de rest vooral ruis toevoegt.
De staat van de kunst verslaan op schaal
Om de prestaties te beoordelen, keken de onderzoekers hoe ver, in kilometers, het voorspelde regiocentrum verwijderd was van de bekende coördinaten van elke gebruiker, en welk percentage gebruikers binnen 161 km (100 mijl) van hun werkelijke locatie werd geplaatst. Over drie benchmark-Twitter-datasets heen presteerde KMKGAT consequent gelijk aan of beter dan sterke bestaande systemen, en verbeterde de nauwkeurigheid binnen 161 kilometer met enkele procentpunten — een betekenisvolle winst op dit volwassenheidsniveau. De voordelen waren het duidelijkst bij kleine en middelgrote netwerken, terwijl bij een enorm mondiale grafiek de methode werd beperkt doordat tijdens training alleen directe buren gesampled konden worden.
Wat dit betekent in alledaagse termen
Voor niet-specialisten is de conclusie dat het steeds beter mogelijk is om te schatten waar gebruikers van sociale media zich bevinden, zelfs als ze nooit een locatie-tag delen. Door gebruikers te groeperen in realistische regio’s gebaseerd op daadwerkelijke accounts en door het model te leren vooral nabijgelegen, vergelijkbare buren in het sociale netwerk te vertrouwen, beperkt KMKGAT waar iemand waarschijnlijk woont of post. Dit kan hulpverleners helpen mensen tijdens rampen te vinden, lokale zoek- en aanbevelingsdiensten verbeteren en studies ondersteunen over hoe informatie zich over plaatsen verspreidt. Tegelijk benadrukt het hoeveel onze gewone online interacties kunnen onthullen over ons offline leven, wat het belang onderstreept van zorgvuldige gegevensgebruik en privacybescherming.
Bronvermelding: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Trefwoorden: geolocatie op sociale media, Twitter-gebruiker locatie, grafische neurale netwerken, locatiegebaseerde diensten, online privacy