Clear Sky Science · nl
Geautomatiseerde identificatie van contextueel relevante biomedische entiteiten met gegrondvestte LLM's
Waarom slimmer taggen van medische artikelen ertoe doet
Elk jaar verschijnen duizenden biomedische studies, vol details over genen, celtypen, ziekten en behandelingen. Veel van deze informatie blijft echter opgesloten in lange pdf’s, waardoor andere wetenschappers moeite hebben de precieze data te vinden die ze nodig hebben. Dit artikel onderzoekt hoe moderne kunstmatige intelligentie—grote taalmodellen, of LLM’s—deze belangrijke biomedische termen automatisch uit onderzoeksartikelen kan halen, en zo verspreide publicaties omzet in goed georganiseerde, doorzoekbare bronnen.
Van rommelige artikelen naar doorzoekbare bouwstenen
Biomedische onderzoekscentra, zoals de Duitse Collaborative Research Centers, zijn afhankelijk van duidelijke, gestructureerde data om studies jarenlang herbruikbaar te maken. Traditioneel moesten onderzoekers hun datasets handmatig labelen met belangrijke entiteiten zoals organismen, cellijnen en genen—een tijdrovende en moeizame taak. LLM’s kunnen volledige artikelen lezen en context begrijpen, waardoor ze veelbelovend zijn voor het automatiseren van dit taggen. Er is echter een kanttekening: beslissen welke termen echt relevant zijn hangt af van de wetenschappelijke vraag en hoe de data hergebruikt zullen worden. De auteurs werken binnen een zorgvuldig ontworpen metadata-schema van het op nefrologie gerichte CRC “NephGen”, dat de AI vertelt welke soorten entiteiten gezocht moeten worden en hoe die georganiseerd moeten worden.
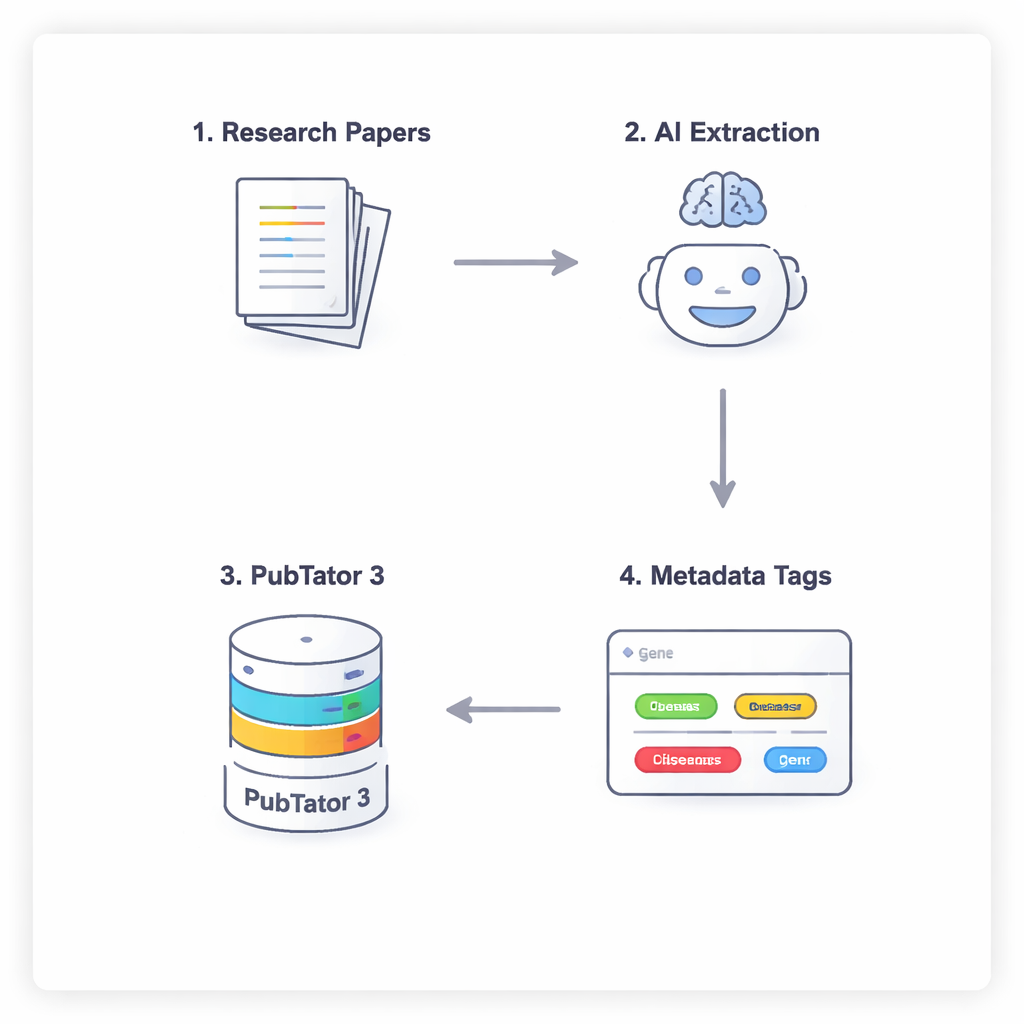
Een vierstappen-conversatie tussen AI en een biologische database
Om te voorkomen dat de AI zomaar raadt of biomedische feiten “hallucineert”, gebruiken de onderzoekers een vierstappenproces dat de modellen dwingt zorgvuldig na te denken en zichzelf te controleren. Eerst scant het model de volledige tekst van een artikel (met uitzondering van discussie en referenties) om potentieel relevante entiteiten voor te stellen. Ten tweede moet het een externe tool raadplegen, PubTator 3, een grote biomedische database, om te bevestigen dat elke voorgestelde term daadwerkelijk bestaat en een erkend identificatienummer heeft. Ten derde wijst de AI elke bevestigde entiteit toe aan een veld in het NephGen-metadata-schema, dat entiteiten groepeert in een hiërarchische, door mensen ontworpen structuur. Ten slotte consolideert het model al deze informatie in een gestructureerde JSON-uitvoer, in wezen een nette machineleesbare samenvatting van belangrijke biomedische entiteiten in het artikel.
Testen van acht AI-modellen met echt nieronderzoek
Het team implementeerde deze workflow via API’s voor 14 verschillende LLM’s en ontdekte dat slechts acht modellen betrouwbaar aan de strikte vereisten konden voldoen, zoals het retourneren van geldige JSON en het correct gebruiken van tools. Ze pasten deze acht modellen vervolgens toe op zes nefrologische onderzoeksartikelen en vroegen elke auteur van een artikel de uiteindelijke lijst met entiteiten van de AI in een korte, face-to-face interview te beoordelen. Omdat er geen vast “correct” aantal te extraheren entiteiten bestaat, concentreerden de auteurs zich op precisie: welk aandeel van de voorgestelde entiteiten de wetenschappers als correct beoordeelden. Met statistische meta-analysmethoden aangepast voor proporties dicht bij 100% schatten ze de precisie per model, rekening houdend met variatie tussen artikelen.
Hoge nauwkeurigheid, maar compromissen in moeite, kosten en snelheid
Over alle modellen behaalden de AI-systemen een totale precisie van ongeveer 91%, wat betekent dat het merendeel van de voorgestelde entiteiten als correct werd beoordeeld. GPT-4.1, GPT-4o Mini en Gemini 2.0 Flash hadden de hoogste precisie—ongeveer 94% tot 98%—hoewel hun onderlinge verschillen niet statistisch duidelijk waren. Gemini-modellen stelden over het algemeen meer entiteiten voor, wat leidde tot meer correcte tags maar ook meer controlewerk voor mensen. Sommige kleinere of goedkopere modellen, zoals GPT-4.1 Nano, waren sneller en goedkoop, maar duidelijk minder accuraat. De auteurs visualiseerden deze spanningen met Pareto-fronten en identificeerden combinaties van modellen die precisie, aantal correcte entiteiten, kosten en verwerkingstijd in balans brachten: bijvoorbeeld, GPT-4o Mini bleek bijzonder aantrekkelijk wanneer zowel nauwkeurigheid als lage kosten prioriteit hebben.
Waarom mensen nog steeds in de lus horen
S ondanks de sterke prestaties benadrukt de studie belangrijke beperkingen. De modellen verwisselden soms informatie over het gepubliceerde artikel met details die niet echt relevant waren voor de onderliggende dataset die toekomstige gebruikers mogelijk willen hergebruiken. Deze verwarring weerspiegelt een bredere uitdaging in geautomatiseerde tekstanalyse: wetenschappelijke artikelen bespreken vaak veel meer dan wat uiteindelijk in een gedeelde dataset terechtkomt. De auteurs bevelen daarom aan dat menselijke experts AI-gegenereerde annotaties blijven beoordelen voordat ze worden gepubliceerd. Ze merken ook op dat hun evaluatie slechts zes nefrologie-artikelen beslaat, dus breder testen over verschillende vakgebieden nodig is. Naarmate de tijd vordert, kan een routinematige “human-in-the-loop”-workflow een consensusreferentieset opbouwen, waardoor het mogelijk wordt niet alleen precisie maar ook het aantal door de AI gemiste entiteiten te meten.
Wat dit betekent voor toekomstige biomedische gegevensdeling
De studie toont aan dat, mits zorgvuldig geleid en gegrond in betrouwbare databases, moderne LLM’s betrouwbaar kunnen helpen bij het annoteren van biomedische artikelen en daarmee de handmatige lasten voor onderzoekers sterk verminderen. De beste modellen naderen deskundigenniveau qua precisie en bieden verschillende afwegingen tussen grondigheid, kosten en snelheid. Vooralsnog blijft menselijke beoordeling essentieel om te waarborgen dat annotaties daadwerkelijk overeenkomen met de datasets en de onderzoekscontext. Maar naarmate hulpmiddelen en open-source modellen zich verder ontwikkelen, zouden workflows als deze de standaard kunnen worden om de huidige vloed van medische artikelen om te zetten in goed georganiseerde, herbruikbare data commons.
Bronvermelding: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Trefwoorden: biomedische tekstanalyse, grote taalmodellen, metadata-annotatie, gegrond AI, nieronderzoek