Clear Sky Science · nl
Automatische diagnose van leeftijdsgebonden maculadegeneratie met machine learning en beeldverwerkingstechnieken
Waarom dit belangrijk is voor uw zicht
Nu mensen langer leven, krijgen steeds meer mensen te maken met leeftijdsgebonden maculadegeneratie (LMD), een aandoening die het centrale gezichtsvermogen geleidelijk aantast en lezen, autorijden of gezichten herkennen moeilijk of onmogelijk kan maken. Oogartsen kunnen vroegtijdige waarschuwingssignalen herkennen op foto’s van de achterzijde van het oog, maar dit handmatig doen voor duizenden patiënten kost veel tijd en vereist gespecialiseerde deskundigen. Deze studie onderzoekt hoe een transparant, op machine learning gebaseerd hulpmiddel kan helpen LMD vroeg te signaleren op routinematige oogfoto’s, zonder te vertrouwen op fragiele, moeilijk te verklaren deep‑learning “black boxes.”
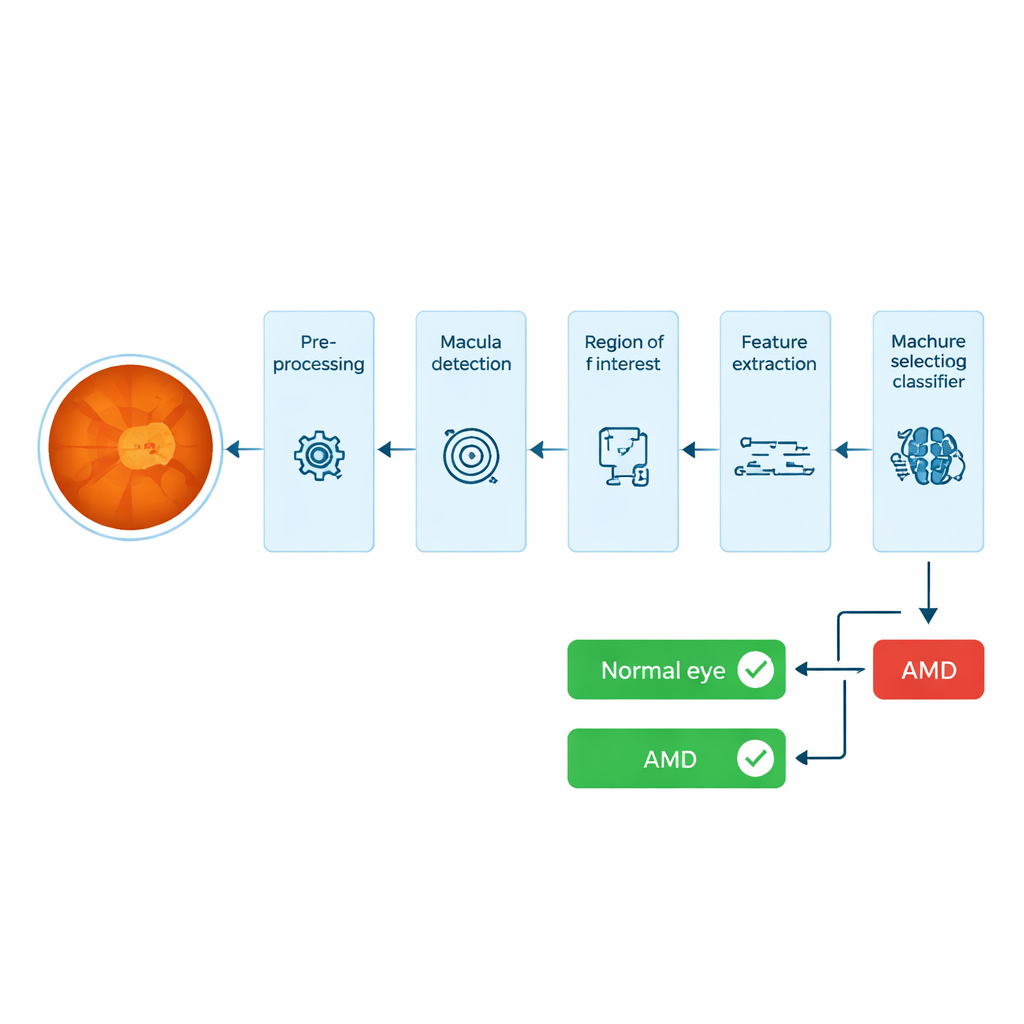
Op zoek naar problemen in het scherpe‑zichtgebied van het oog
LMD valt de macula aan, een klein donker vlekje nabij het midden van het netvlies dat zorgt voor scherp, gedetailleerd zicht. Veel geautomatiseerde systemen proberen in volledige oogbeelden kleine vetachtige afzettingen, drusen genaamd, te vinden, maar drusen kunnen gemakkelijk worden verward met andere heldere plekjes zoals kleine bloedinkjes en variëren sterk in vorm en grootte. Daardoor zijn ze lastig betrouwbaar door een computer te laten detecteren, en zelfs experts moeten tijd besteden aan het zorgvuldig controleren van de resultaten. De auteurs kiezen een andere benadering: in plaats van rechtstreeks naar drusen over het hele netvlies te zoeken, richten ze zich op het maculagebied zelf en meten hoe de textuur en kleur veranderen wanneer LMD aanwezig is.
Van ruwe foto naar de “vingerafdruk” van de macula
Het systeem begint met een kleurenfoto van de achterzijde van het oog, een zogeheten fundus‑afbeelding. Het verbetert eerst het contrast met standaard beeldverwerkingsstappen zodat donkere en lichte gebieden beter te onderscheiden zijn. Vervolgens lokaliseert het automatisch de papil—het heldere cirkelvormige gebied waar zenuwen het oog verlaten—en gebruikt de bekende geometrische relatie tot de macula om langs een smalle strook van het beeld te zoeken naar het donkerste gebied dat past bij de verwachte grootte en positie van de macula. Rond dit punt snijdt het systeem een klein rechthoekig gebied uit: dit is de regio van belang, met het weefsel dat het meest waarschijnlijk vroeg LMD‑gerelateerd letsel toont.
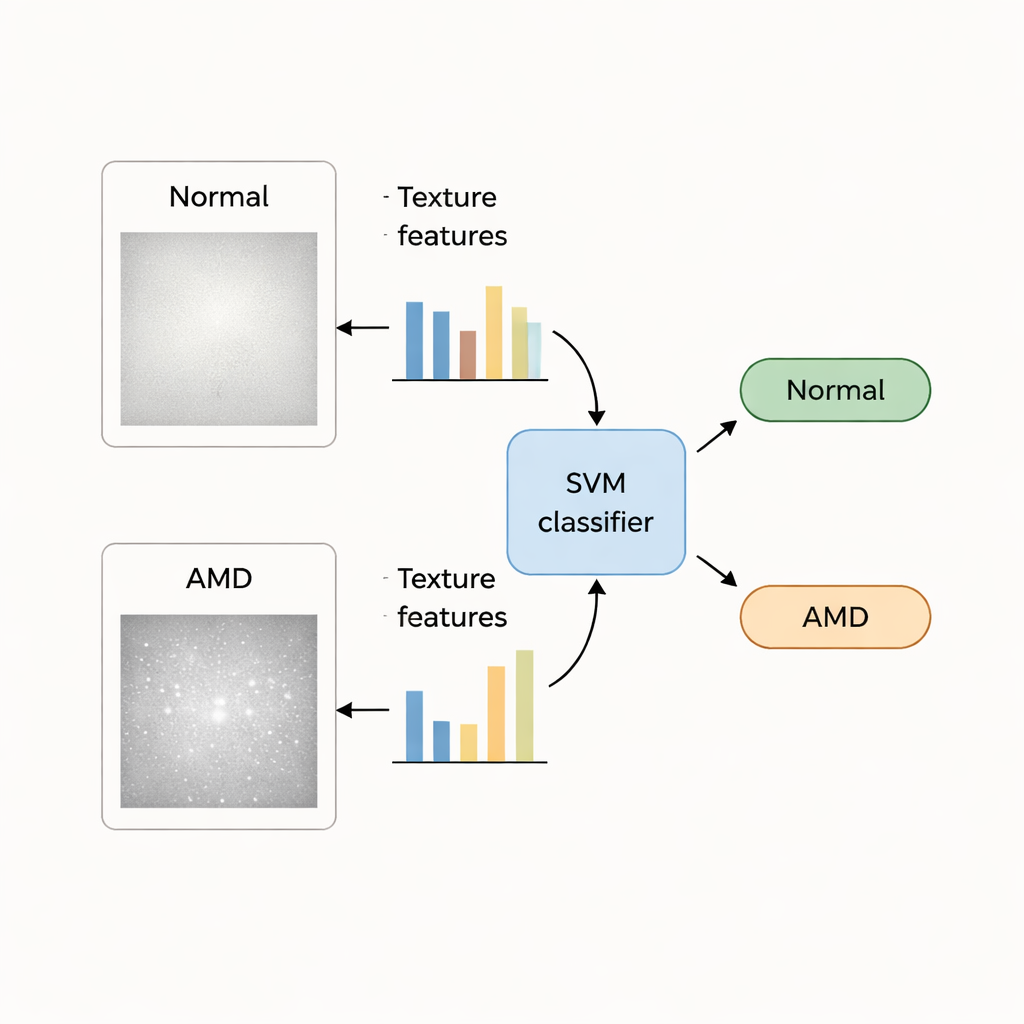
Patronen en kleuren omzetten in getallen
Binnen dit maculaire vlak berekenen de onderzoekers een grote set numerieke beschrijvingen, ofwel "handgemaakte kenmerken." Textuurkenmerken vangen hoe pixelintensiteiten zijn gerangschikt—of het oppervlak er glad, gevlekt of onregelmatig uitziet—terwijl kleurkenmerken verschuivingen in helderheid en tint vastleggen die veranderingen in pigment en weefselgezondheid kunnen weerspiegelen. In totaal worden voor elke oogfoto 140 textuur‑ en 48 kleurwaarden gemeten. Omdat niet al deze getallen even nuttig zijn, past het team statistische tests en een kenmerk‑rangschikkingsmethode toe om een kleinere subset te selecteren die het beste gezonde en LMD‑ogen scheidt, waarbij redundante of rumoerige metingen worden weggesneden.
De machines trainen om “LMD” of “normaal” te zeggen
Met deze geselecteerde kenmerken trainen de auteurs verschillende bekende machine‑learningclassifiers—Support Vector Machine (SVM), k‑Nearest Neighbor, Naïve Bayes en een eenvoudige neuraal netwerk—om het verschil te leren tussen normale en door LMD aangetaste ogen. Ze gebruiken twee openbare verzamelingen van netvliesafbeeldingen: de STARE‑dataset, met 35 normale en 74 LMD‑beelden, en de grotere ODIR‑dataset, met honderden gelabelde gevallen. Om de betrouwbaarheid te testen, splitsen ze herhaaldelijk elke dataset in trainings‑ en testgedeelten, waarbij ze door de beelden heen rouleren zodat elk oog minstens eenmaal als test dient, en meten ze vervolgens nauwkeurigheid, foutpercentage en hoe vaak LMD correct wordt gedetecteerd.
Duidelijke resultaten en betere verklaringen
Over alle tests heen steekt de SVM‑classifier die textuurkenmerken uit het maculaire gebied gebruikt er bovenuit. In de STARE‑dataset onderscheidt hij LMD bijna 99% van de tijd correct van normale ogen; in ODIR ligt de nauwkeurigheid rond 95%. Textuurinformatie blijkt krachtiger dan kleur alleen, en het combineren van beide soorten kenmerken overtreft de prestaties van textuur op zichzelf niet. Hoewel sommige deep‑learning‑systemen in de literatuur vergelijkbare of iets hogere scores bereiken, hebben die veel gelabelde data nodig en bieden ze weinig inzicht in welke beeldsignalen ze gebruiken. Daarentegen corresponderen de handgemaakte textuur‑ en kleurkenmerken in deze studie met herkenbare structuren in het netvlies, wat het systeem beter interpreteerbaar maakt voor clinici.
Wat dit betekent voor patiënten
In gewone bewoordingen laat de studie zien dat een relatief eenvoudig, transparant computerprogramma een standaard oogfoto kan bekijken, inzoomen op de macula en—met zeer hoge betrouwbaarheid—kan aangeven of LMD waarschijnlijk aanwezig is, zonder eerst te proberen elke kleine afzetting te traceren. Zo’n hulpmiddel kan oogklinieken en screeningsprogramma’s helpen snel grote aantallen beelden te sorteren, waardoor patiënten met vroege ziekte eerder door specialisten worden gezien, en artsen bovendien een duidelijker beeld krijgen van welke visuele patronen de machine gebruikt om haar besluit te nemen.
Bronvermelding: Agarwal, D., Bhargava, A., Alsharif, M.H. et al. Automatic diagnosis of age-related macular degeneration using machine learning and image processing techniques. Sci Rep 16, 5037 (2026). https://doi.org/10.1038/s41598-026-35428-2
Trefwoorden: leeftijdsgebonden maculadegeneratie, retina‑beeldvorming, machine learning, vroege ziektectectie, medische beeldanalyse