Clear Sky Science · nl
Combineren van parameterfragmentatie en groepsschudden ter verdediging tegen een onbetrouwbare server in federated learning
Waarom het beschermen van gedeelde modellen ertoe doet
Onze telefoons, ziekenhuizen en banken worden steeds vaker aangedreven door artificiële intelligentie. Vaak willen meerdere organisaties gezamenlijk een gedeeld model trainen, maar wetten en gezond verstand zeggen dat ze hun ruwe data niet op één plaats mogen samenvoegen. Federated learning is bedacht om deze spanning op te lossen: elke deelnemer traint op zijn eigen apparaat en deelt alleen modelupdates. Dit artikel toont echter aan dat zelfs die updates privéinformatie kunnen lekken als de centrale server nieuwsgierig of oneerlijk is — en introduceert daarna een nieuwe methode om zowel onze gegevens als onze identiteit beter te beschermen.
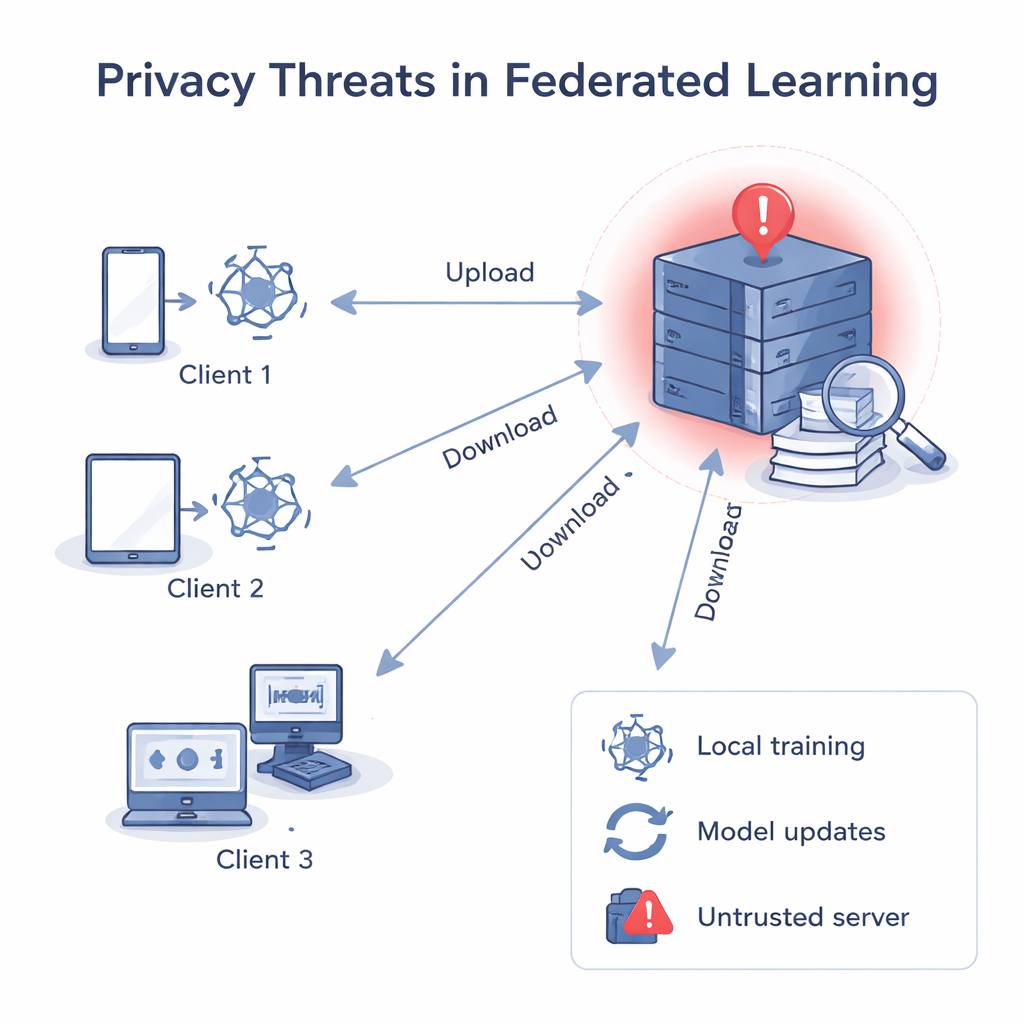
Wanneer de server niet te vertrouwen is
In klassiek federated learning stuurt een centrale server een gemeenschappelijk model uit, verbetert elke cliënt het met eigen data en stuurt dan de geüpdatete parameters terug. De server middelen deze updates tot een beter globaal model. Hoewel ruwe data de apparaten nooit verlaat, hebben eerdere onderzoeken laten zien dat gradïenten en gewichten — de getallen in het model — "achteruit kunnen worden gerund" om privédata te reconstrueren, zoals beelden of tekst, of om te raden of een specifiek record voor training is gebruikt. Als de centrale server onbetrouwbaar is, kan hij elke cliëntupdate afzonderlijk analyseren, iets leren over die lokale data en zelfs een update linken aan een bepaalde persoon of organisatie.
Updates in onschadelijke stukjes breken
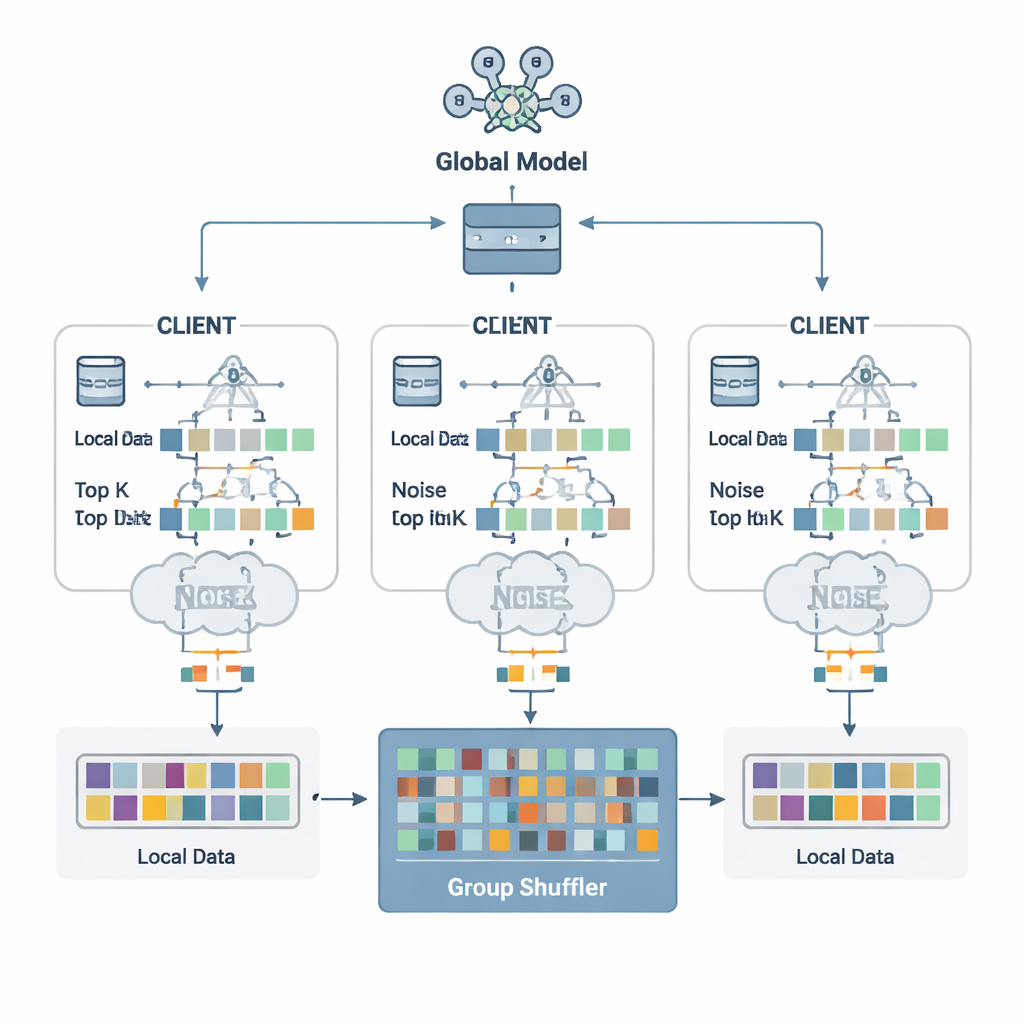
De auteurs stellen een verdedigingsschema voor genaamd Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS). Het eerste idee is eenvoudig maar krachtig: stuur nooit een volledige update. In plaats daarvan splitst elke cliënt zijn modelupdate in meerdere kunstmatige "fragmenten". De meeste hiervan zijn gevuld met willekeurige getallen, en alleen het laatste fragment wordt aangepast zodat alle fragmenten samen nog steeds overeenkomen met de werkelijke update. Elk enkel fragment, of zelfs meerdere daarvan, lijkt op ruis en onthult vrijwel niets over de oorspronkelijke data. Deze wiskundige truc lijkt op secret sharing: alleen door alle stukken te combineren kan men het geheel herstellen.
Ruis toevoegen en alles door elkaar husselen
Het verzenden van veel fragmenten kan nog steeds inefficiënt zijn en, als ze samen worden bekeken, een aanvaller mogelijk meer laten afleiden. Om dit te voorkomen selecteert elke cliënt alleen de belangrijkste fragmentwaarden — de Top-K invoeren die het meest van belang zijn voor het leren — en voegt daar zorgvuldig gekalibreerde willekeurige ruis aan toe volgens de principes van differentiële privacy. Deze ruis maakt het statistisch moeilijk om te zeggen of de data van één persoon een bepaalde waarde heeft beïnvloed. Vervolgens komt het tweede belangrijke ingrediënt: groepsschudden. In plaats van fragmenten rechtstreeks naar de server te sturen, sturen cliënten ze naar een vertrouwde "shuffler" die fragmenten van veel cliënten in groepen mixt voordat ze worden doorgestuurd. Na deze vermenging kan de server niet meer achterhalen welk fragment van welke cliënt afkomstig is, waardoor de koppeling tussen updates en identiteiten wordt verbroken.
Nauwkeurigheid behouden terwijl lekken worden verminderd
Het team testte SDPFGS op standaard beeld- en tekstbenchmarks, waaronder handgeschreven cijfers (MNIST), kledingfoto's (Fashion-MNIST) en kleurbeelden (CIFAR-10 en CIFAR-100), evenals een taak voor nieuwsklassificatie. Ze vergeleken hun methode met meerdere state-of-the-art privacytechnieken die alleen ruis gebruiken, alleen schudden of eenvoudige gradiëntcompressie toepassen. In al deze experimenten evenaarde of overtrof SDPFGS consequent de nauwkeurigheid van concurrerende methoden, terwijl het minder communicatie en trainingstijd gebruikte dan veel van die methoden. Vooral onder modelinversie-aanvallen — waarbij een aanvaller probeert trainingsvoorbeelden te reconstrueren — had SDPFGS de laagste succesratio voor aanvallen, wat betekent dat het het minst lekte over de onderliggende data.
Wat dit betekent voor gewone gebruikers
Voor een leek is de kernboodschap dat "de data verbergen" niet genoeg is; we moeten ook verbergen wat onze apparaten tijdens training verzenden. SDPFGS doet dit door elke modelupdate om te zetten in noisy, geschudde fragmenten die op zichzelf nutteloos zijn maar samen nog steeds een hoogwaardig globaal model opleveren. Het resultaat is een sterker schild tegen een nieuwsgierige of gecompromitteerde server, met slechts een kleine kost in nauwkeurigheid en efficiëntie. Naarmate federated learning zich verspreidt naar de gezondheidszorg, financiën en slimme apparaten, kunnen technieken zoals SDPFGS helpen verzekeren dat mensen profiteren van krachtige gedeelde modellen zonder de sleutels tot hun privéleven over te dragen.
Bronvermelding: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Trefwoorden: federated learning, gegevensprivacy, differentiële privacy, modelinversie-aanvallen, veilige aggregatie