Clear Sky Science · nl
Onenigheid tussen menselijke en AI-evaluatie van behandelplannen
Waarom dit van belang is voor dagelijkse medische zorg
Naarmate hulpmiddelen met kunstmatige intelligentie (AI) artsen gaan helpen bij het kiezen van behandelingen, rijst een belangrijke vraag: wiens oordeel vertrouwen we meer — mensen of machines? Deze studie onderzoekt een eenvoudige maar verontrustende mogelijkheid: artsen en AI-systemen kunnen niet alleen van mening verschillen over welke behandeling het beste is, maar ook over wat in de eerste plaats telt als een “goed” behandelplan. Het begrijpen van deze kloof is essentieel als we willen dat AI ondersteuning biedt in plaats van stilletjes de besluitvorming in de klinische praktijk te vertekenen.
Een rechtstreekse vergelijking van behandeladviezen
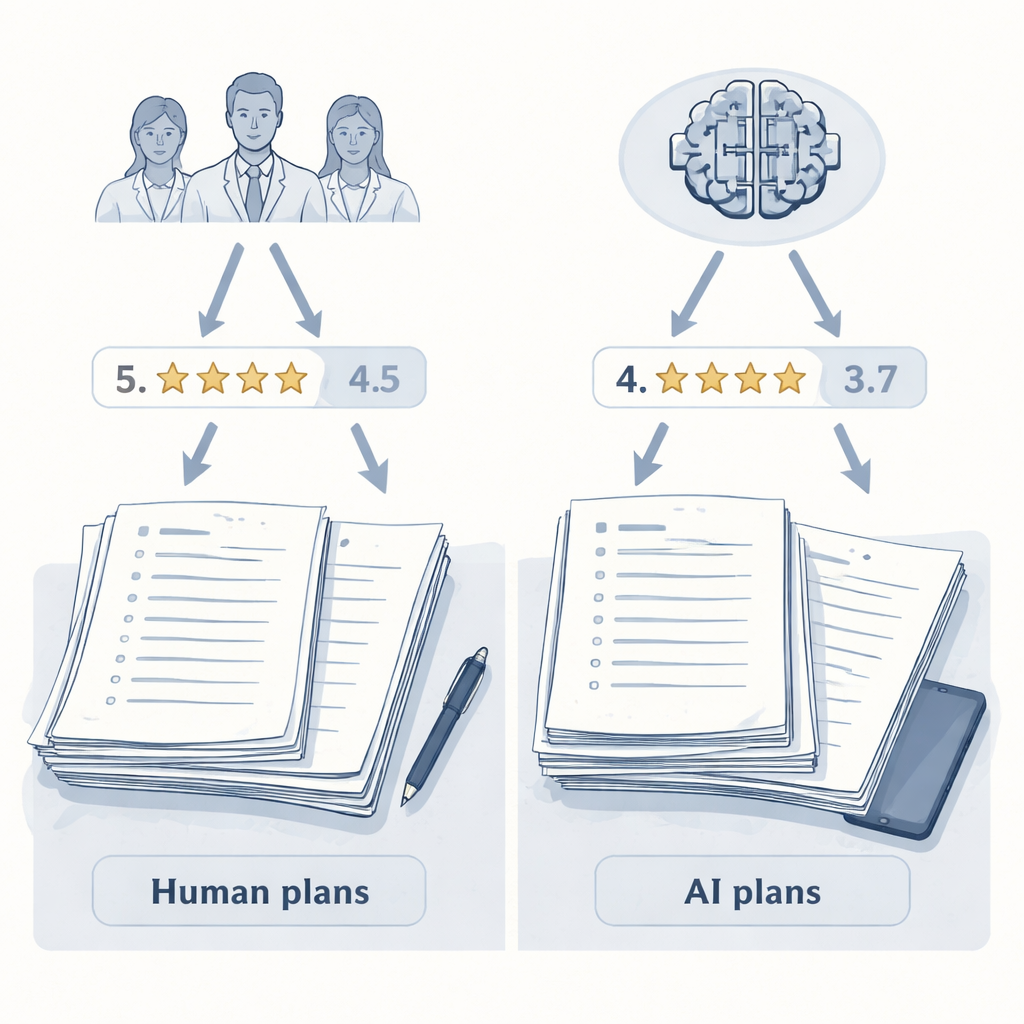
De onderzoekers richtten zich op dermatologie, een vakgebied waarin artsen langdurige huidaandoeningen behandelen die zelden één eenduidig “correct” antwoord hebben. Tien ervaren dermatologen en twee grote taalmodellen (LLM’s) — een algemeen model en een model met nadruk op redeneervermogen — kregen ieder de opdracht behandelplannen te schrijven voor vijf uitdagende, verzonnen casussen, zoals ernstig eczeem, psoriasis in combinatie met andere aandoeningen en zwangerschapsacne. Om eerlijk te blijven werden alle 60 plannen bewerkt naar een gemeenschappelijk formaat: vergelijkbare lengte, structuur en toon. Alle duidelijke aanwijzingen of een mens of een AI het plan had geschreven werden verwijderd, zodat latere beoordelaars op inhoud zouden beoordelen, niet op stijl.
Hoe mensen en AI het beoordeelden
De plannen werden daarna in twee rondes blind gescoord volgens dezelfde rubric. Ten eerste beoordeelde dezelfde groep van tien dermatologen elk plan op algehele kwaliteit van 0 tot 10, rekening houdend met effectiviteit, veiligheid, uitvoerbaarheid en patiëntgerichtheid. Ten tweede beoordeelde een apart AI-model — uitsluitend gebruikt als beoordelaar, niet als planmaker — precies dezelfde plannen met dezelfde instructies. Cruciaal is dat noch de menselijke beoordelaars noch de AI-beoordelaar wisten wie een bepaald plan had geschreven. Deze opzet maakte het de auteurs mogelijk één sleutelvariabele te isoleren: of de evaluator mens of AI was.
Mensen steunen mensen, AI steunt AI
De resultaten lieten een duidelijk “evaluator-effect” zien. Wanneer mensen de plannen beoordeelden, gaven ze hogere cijfers aan plannen geschreven door collega-dermatologen dan aan die van een van de AI-systemen. Door mensen gemaakte plannen hadden een iets hogere gemiddelde score en bezetten de top vijf van de ranglijst. Een van de AI-modellen, het geavanceerde redeneermodel, eindigde laag in de ranglijst. Toen echter de AI-beoordelaar het overnam, keerde het beeld zich om. Nu stegen de twee door AI geschreven plannen naar de bovenkant van de lijst en daalden alle plannen van menselijke dermatologen daaronder. Gemiddeld beoordeelde de AI-beoordelaar AI-gegenereerde plannen hoger dan door mensen gemaakte plannen, hoewel hij exact dezelfde, gestandaardiseerde tekst las als de dermatologen.
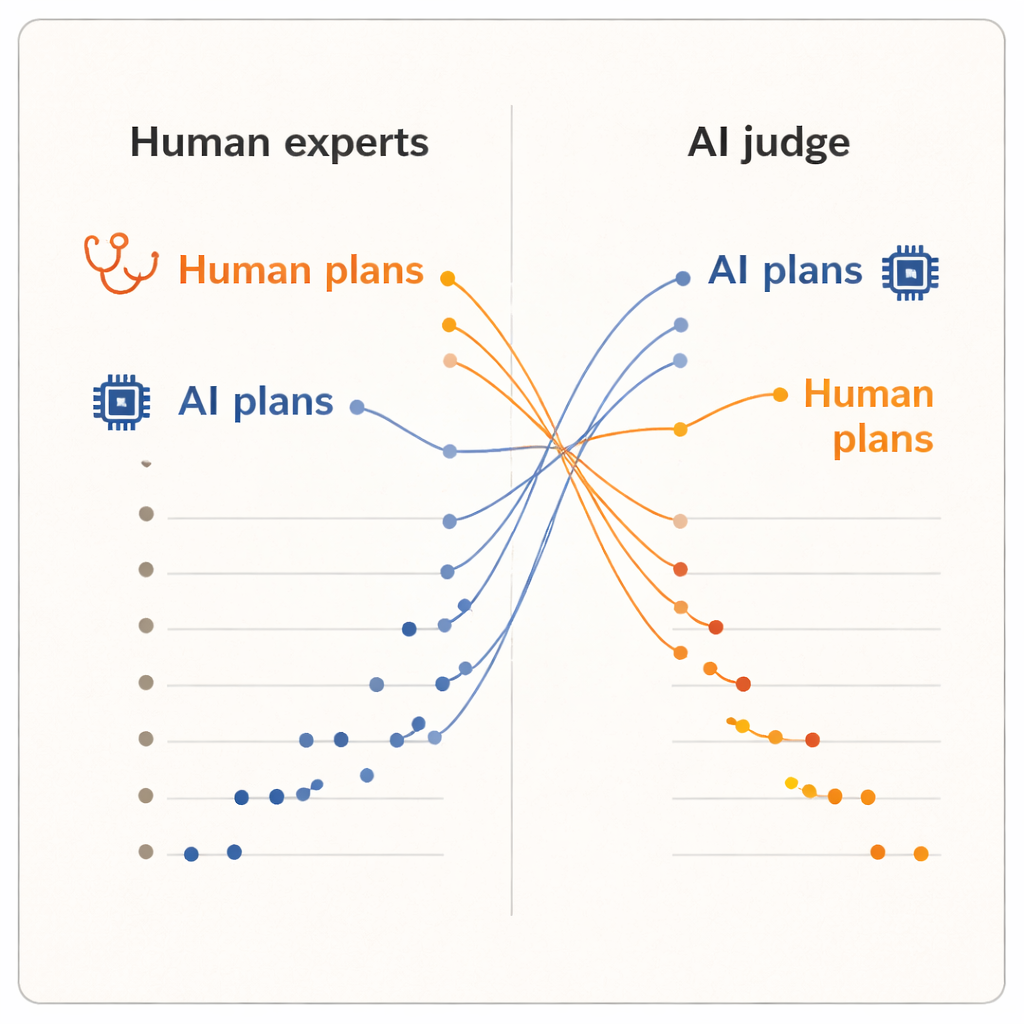
Verschillende ideeën over wat een "goed" plan is
Aangezien de plannen waren genormaliseerd wat betreft woordkeus en de beoordelaars geen kennis hadden van de herkomst, beargumenteren de auteurs dat deze splitsing niet verklaard kan worden door oppervlakkige afwerking. In plaats daarvan suggereert het dat mensen en AI-systemen verschillende interne maatstaven hanteren. Klinici leunen waarschijnlijk op real-world ervaring: wat haalbaar is in hun praktijk, hoe patiënten reageren en welke afwegingen in de praktijk acceptabel aanvoelen. Een AI-beoordelaar, getraind op grote tekstverzamelingen, kan daarentegen de voorkeur geven aan plannen die patronen volgen die veel voorkomen in de medische literatuur of richtlijnen, ook als die patronen lokale beperkingen of patiëntvoorkeuren niet volledig vastleggen. De studie is bescheiden van omvang — slechts tien clinici, vijf casussen en één AI-beoordelaar — en meet waargenomen kwaliteit, niet daadwerkelijke patiëntuitkomsten. Toch is de omkering opvallend genoeg om dieperliggende vragen op te werpen over hoe we klinische AI evalueren.
Het heroverwegen van hoe we klinische AI testen en gebruiken
Uit deze bevindingen trekken de auteurs twee brede lessen. Ten eerste missen traditionele “juiste-antwoord” tests voor medische AI veel van wat ertoe doet in de echte zorg, waar plannen effectiviteit, veiligheid, kosten, logistiek en wensen van de patiënt moeten balanceren. Zij pleiten voor rijkere, multimetrische evaluatiekaders die expliciet deze dimensies scoren, meerdere menselijke en AI-beoordelaars gebruiken en analyseren waar en waarom meningsverschillen ontstaan in plaats van alles in één cijfer samen te brengen. Ten tweede suggereren zij dat verschillen tussen menselijke en AI-oordelen een eigenschap kunnen zijn, niet slechts een fout. Bij zorgvuldig gebruik kunnen door AI gegenereerde plannen dienen als een goed doordachte second opinion die artsen aanzet hun veronderstellingen te heroverwegen, terwijl artsen de real-world context en ethische afweging leveren die AI mist. Het bouwen van betrouwbare, transparante interfaces die aannames blootleggen, clinici toestaan prioriteiten aan te passen en kritische beoordeling uitnodigen, kan helpen om deze spanning tussen menselijke en AI-perspectieven om te zetten in veiligere, meer evenwichtige besluitvorming.
Bronvermelding: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Trefwoorden: klinische besluitvormingsondersteuning, kunstmatige intelligentie in de geneeskunde, samenwerking mens en AI, behandelplanning, evaluatiebias