Clear Sky Science · nl
Een hybride voorspellingsmodel voor PM2.5-concentratie gebaseerd op hoge- en lagefrequente IMF's met EMD-decompositie
Waarom schonere luchtvoorspellingen van belang zijn voor het dagelijks leven
Fijnstof in de lucht, bekend als PM2.5, is zo klein dat het diep in onze longen kan doordringen en zelfs in de bloedbaan kan komen. In Noord-China, waar zware industrie en winterverwarming geconcentreerd zijn, bereiken deze deeltjes vaak niveaus die tot gezondheidswaarschuwingen kunnen leiden, het verkeer kunnen ontregelen en zelfs fabrieken en scholen kunnen doen sluiten. Deze studie stelt een zeer praktische vraag: kunnen we uur‑voor‑uur PM2.5‑waarden beter voorspellen, zodat steden en inwoners eerder en betrouwbaarder gewaarschuwd worden voordat de lucht gevaarlijk wordt?
Een nadere blik op de vuile lucht van Noord-China
De onderzoekers richtten zich op zes grote steden in Noord-China: Beijing, Tianjin, Shijiazhuang, Taiyuan, Jinan en Zhengzhou. Deze steden vertegenwoordigen dichtbevolkte, geïndustrialiseerde gebieden waar vervuilingsepisoden frequent voorkomen, vooral in de winter. Met officiële meetgegevens verzamelde het team uurgegevens van PM2.5 voor het hele jaar 2021, wat voor elke stad 8.760 gegevenspunten opleverde. Ze vonden dat de vervuilingsniveaus sterk tussen steden verschilden; zo had Taiyuan het hoogste gemiddelde PM2.5, terwijl Beijing het laagste had. Extreme gebeurtenissen vielen op: in Taiyuan piekten de concentraties tot 652 microgram per kubieke meter tijdens een stof‑ en vervuilingsepisode in maart, waardoor de luchtkwaliteitsindex het maximum bereikte—een duidelijk teken van ernstig vervuilde lucht.
Waarom het voorspellen van PM2.5 zo moeilijk is
PM2.5-niveaus worden door veel krachten tegelijk beïnvloed—lokale emissies van verkeer en fabrieken, regionale aanvoer van stof en rook, windsnelheid, luchtvochtigheid en meer. Daardoor gedraagt het vervuilingsverloop zich minder als een vloeiende curve en meer als een gekartelde, onrustige hartslag. Traditionele statistische hulpmiddelen of zelfs moderne neurale netwerken kunnen moeite hebben met dit soort data: ze vangen mogelijk de algemene trend, maar missen plotselinge pieken, of ze werken in de ene stad goed maar falen in een andere. Eerdere studies probeerden voorspellingen te verbeteren door meer fysieke details toe te voegen (zoals chemische transportmodellen) of door uitsluitend te leunen op geavanceerde machine‑learningmethoden. Dit artikel combineert daarentegen meerdere methoden, elk gekozen om een ander “ritme” in de data te verwerken.
Het signaal splitsen in snelle en langzame ritmes
De sleutelstap is een techniek genaamd empirical mode decomposition, die de oorspronkelijke PM2.5-tijdreeks opsplitst in meerdere eenvoudigere componenten. Sommige van deze componenten trillen snel en vangen kortetermijnpieken en ruis; andere veranderen langzaam en weerspiegelen de onderliggende trend. De auteurs groeperen de eerste vijf componenten als “hoge‑frequente” delen en de resterende, plus een residuele trend, als “lage‑frequente” delen. Hoge‑frequente componenten, die onregelmatiger en sterk niet‑lineair zijn, worden gevoed aan een long short‑term memory (LSTM)-netwerk, een type deep‑learningmodel dat goed is in het leren van patronen over tijd. De vloeiender, lage‑frequente componenten worden doorgegeven aan een klassiek tijdreeksmodel bekend als ARIMA, dat effectief is wanneer de data zich meer regulier en bijna lineair gedragen.
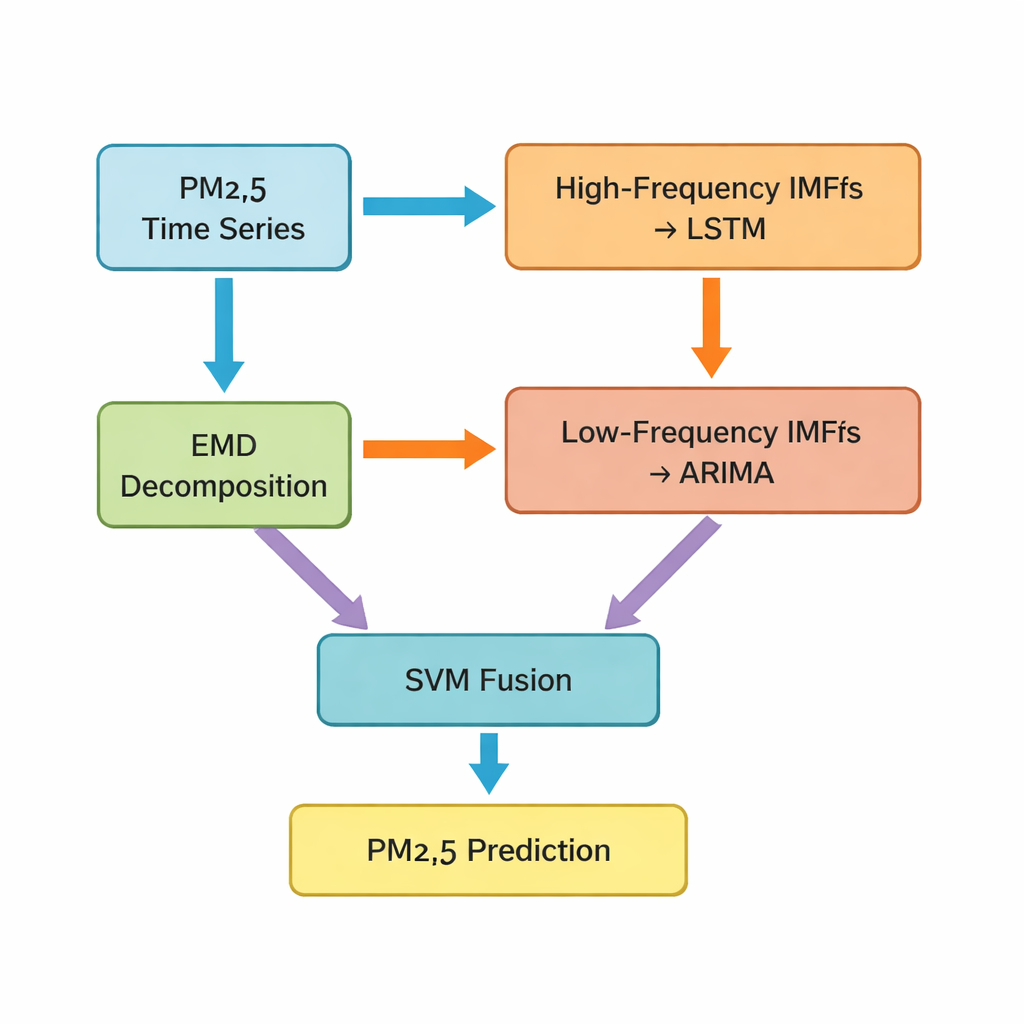
Verschillende modellen samenvoegen tot één slimmere voorspelling
Nadat de LSTM- en ARIMA‑modellen elk hun eigen deelvoorspellingen hebben geproduceerd, staat de studie nog voor een uitdaging: hoe deze afzonderlijke voorspellingen samen te voegen tot één definitieve, best‑guess PM2.5‑waarde voor het volgende uur. Hiervoor gebruiken de auteurs een support vector machine (SVM), een andere machine‑learningmethode die leert hoe de twee invoerwaarden te wegen en te combineren. In wezen fungeert de SVM als scheidsrechter, die beslist wanneer het “snelle” beeld van de wereld (hoge‑frequente patronen) zwaarder moet wegen en wanneer het “langzame” beeld (langetermijntrends) moet domineren. Het gecombineerde systeem, dat de auteurs Hybrid‑EMDHL noemen, wordt vervolgens beoordeeld met verschillende prestatieindicatoren, waaronder gemiddelde fout, hoe nauw voorspellingen overeenkomen met waargenomen waarden en hoe goed het model de richting van verandering voorspelt—of de waarden stijgen of dalen.
Heldere waarschuwingen en betere planning
Het hybride model presteert beter dan elk van zijn hoofdcomponenten afzonderlijk in alle zes steden. Het vermindert niet alleen gemiddelde en kwadratische fouten, maar verbetert ook sterk het vermogen om correct te anticiperen of PM2.5 in het volgende uur zal stijgen of dalen—een cruciale eigenschap voor het uitgeven van tijdige gezondheidsadviezen. In veel gevallen halveert de hybride benadering de foutmaten vergeleken met een enkel neuraal‑netwerkmodel, en de “richtingsnauwkeurigheid” overschrijdt 0,69, wat betekent dat in ruim twee derde van de testgevallen de trend correct wordt voorspeld. Voor een leek betekent dit weerberichtachtige luchtkwaliteitsvoorspellingen die scherper en betrouwbaarder zijn. Voor stadsplanners en gezondheidsautoriteiten biedt het een praktisch hulpmiddel om gerichte, vroege maatregelen te ondersteunen—zoals het aanpassen van industriële activiteiten of verkeersmaatregelen—voordat een vervuilingsepisode piekt, wat helpt blootstelling te verminderen en het dagelijks leven te beschermen in enkele van China’s meest vervuilde stedelijke gebieden.
Bronvermelding: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Trefwoorden: PM2.5-voorspelling, luchtvervuiling, Noord-China, machine learning, tijdreeksdecompositie