Clear Sky Science · nl
QPSODRL: een verbeterd quantum-deeltjeszwermoptimalisatie- en deep reinforcement learning-gebaseerd intelligent clusteren en routeringsprotocol voor draadloze sensornetwerken
Slimmere sensornetwerken voor een verbonden wereld
Van precisielandbouw tot systeem voor rampenwaarschuwing: draadloze sensornetwerken monitoren stilletjes onze omgeving en verzamelen gegevens van honderden of duizenden kleine apparaten verspreid over grote gebieden. Hun grootste zwakte is ook hun bepalende kenmerk: elke sensor werkt op een kleine batterij die moeilijk of niet te vervangen is. Dit artikel presenteert een nieuwe manier om de organisatie en de sturing van datastromen in deze netwerken te regelen, zodat batterijen langer meegaan, informatie betrouwbaarder wordt verzonden en het netwerk zich aanpast wanneer de omstandigheden veranderen.
Waarom kleine apparaten grote intelligentie nodig hebben
In een draadloos sensornetwerk kan elke knooppunt meten, rekenen en communiceren, maar energie is schaars. Als sommige knooppunten te veel werk doen, gaan ze vroegtijdig dood, wat leidt tot “dode zones” waar geen data meer kan worden verzameld. Om dit te voorkomen, groeperen ontwerpers doorgaans knooppunten in clusters. Binnen elk cluster wordt één knooppunt de clusterhead: die verzamelt metingen van zijn buren en stuurt ze door naar een centrale basisstation. Het kiezen welke knooppunten clusterheads moeten zijn en hoe data over het netwerk moet worden gehopt, is een complexe puzzel die verandert naarmate batterijen leger raken. Traditionele regelgebaseerde of enkelvoudige-algoritmeoplossingen blijken vaak te snel tevreden met suboptimale patronen of falen wanneer de vorm en energieniveaus van het netwerk in de loop van de tijd veranderen.
Het samensmelten van quantum-geïnspireerde zwermen met leermachines
Deze studie introduceert QPSODRL, een protocol dat twee krachtige ideeën combineert: een quantum-geïnspireerde zwermmethode voor het vormen van clusters en een deep reinforcement learning-motor voor routering. In de eerste fase verkennen virtuele “deeltjes” verschillende manieren om clusterheads en leden toe te wijzen. Hun gedrag wordt gestuurd door een maat voor hoe gelijkmatig energie over het netwerk verdeeld is, bekend als entropie. Wanneer het energiegebruik onevenwichtig is, moedigt het algoritme brede exploratie van nieuwe clusterindelingen aan; wanneer de situatie stabiel lijkt, verfijnt het veelbelovende opstellingen. Een speciale stap van “elite-perturbatie” duwt de beste kandidaten af en toe in nieuwe richtingen, wat helpt de zoektocht uit lokale doodlopende wegen te brengen en voorkomt dat dezelfde energie-intensieve knooppunten te veel worden gebruikt. 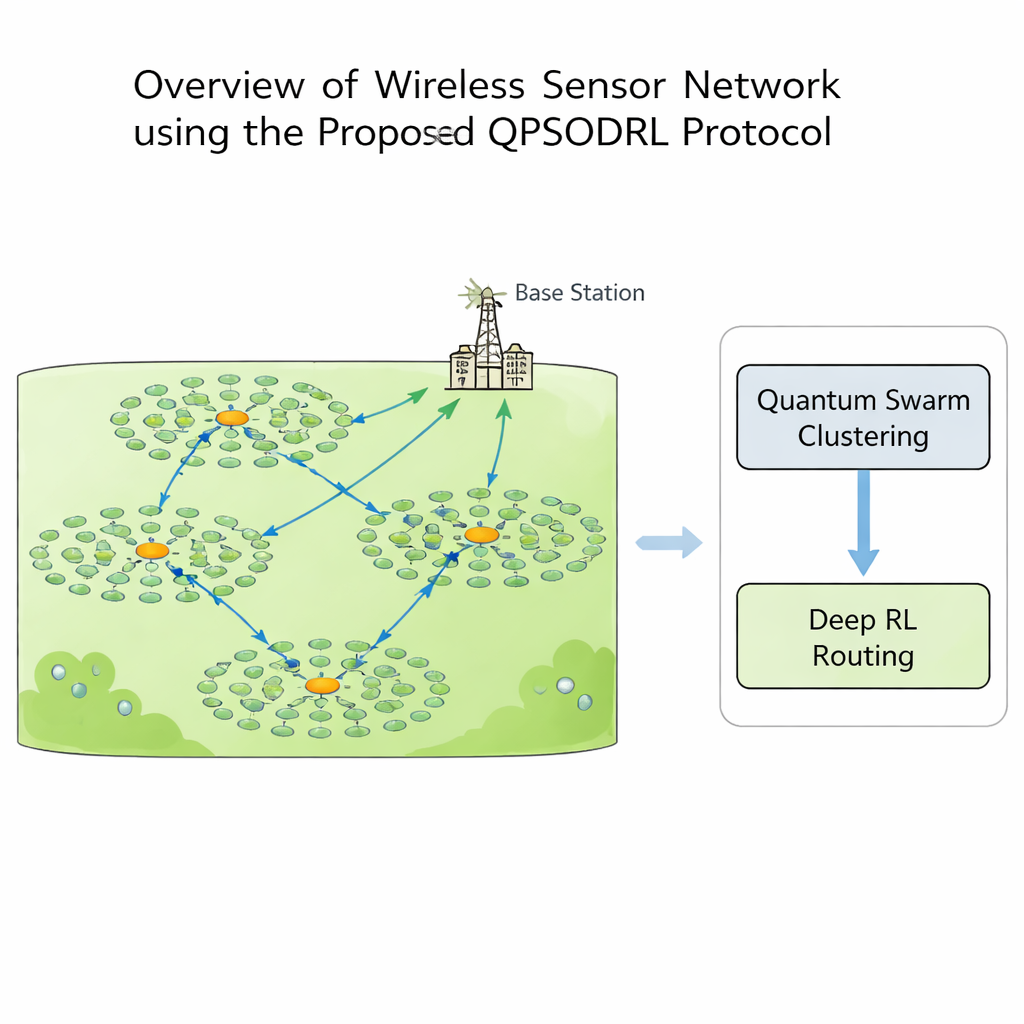
Het netwerk leren betere paden te vinden
Zodra clusters zijn gevormd, beslist de tweede fase hoe elke clusterhead zijn data naar het basisstation moet sturen. In plaats van vaste routes te volgen, beschouwt QPSODRL elke clusterhead als een agent in een leerproces. In elke stap observeert de agent zijn resterende energie, de energie en afstand van naburige heads en geschatte vertragingen, en kiest vervolgens de volgende hop. Een gespecialiseerde vorm van deep Q-learning, Dueling Double Deep Q‑Network genoemd, schat hoe goed elke keuze op de lange termijn is. De auteurs voegen een “entropie”-term toe om te ontmoedigen dat het systeem te snel te zeker wordt, zodat het blijft blijven onderzoeken van alternatieve routes. Ze ontwerpen ook een verbeterd experience-replaymechanisme dat het leren doelbewust richt op de meest informatieve situaties — zoals wanneer energie laag is of vertragingen pieken — zodat het model sneller verbetert in de scenario’s die er het meest toe doen. 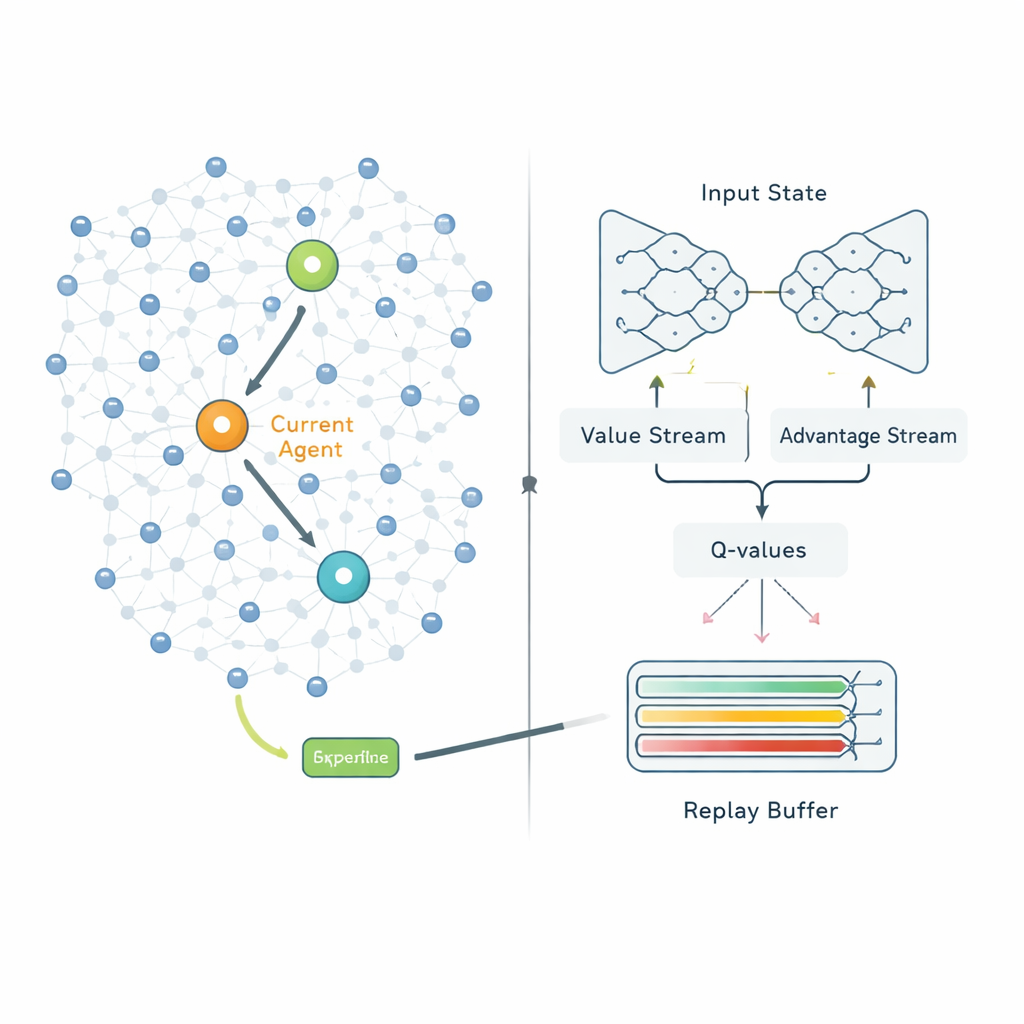
De aanpak op de proef gesteld
Om te zien hoe QPSODRL presteert, voert de auteur gedetailleerde computersimulaties uit van netwerken met 100 en 200 knooppunten verspreid over gebieden van verschillende groottes en met verschillende fracties knooppunten die als clusterheads fungeren. Het nieuwe protocol wordt vergeleken met vier recente en geavanceerde concurrenten die deeltjeszwermen, walvisoptimalisatie, fuzzy logic of andere hybride en leer-gebaseerde schema’s gebruiken. Onder alle geteste opstellingen houdt QPSODRL het netwerk langer operationeel voor meer communicatierondes, levert het meer datapakketten bij het basisstation af en verbruikt het minder totale energie. Het verdeelt ook de werklast onder clusterheads gelijkmatiger, wat blijkt uit een lagere variatie in hoeveel verkeer elke head verwerkt. Deze voordelen zijn vooral duidelijk in zwaardere indelingen waarbij het basisstation aan de rand van het veld is geplaatst en sommige knooppunten langere hops moeten maken.
Wat dit betekent voor systemen in de echte wereld
Voor niet-specialisten is de kernboodschap dat het geven van het vermogen aan sensornetwerken om zowel hun structuur globaal te optimaliseren als lokaal te leren van ervaring hun nuttige levensduur aanzienlijk kan verlengen. De quantum-geïnspireerde clustering van QPSODRL houdt het energiegebruik in balans, terwijl de deep learning-gebaseerde routering zich aanpast aan veranderende omstandigheden zonder constante menselijke bijsturing. Hoewel de resultaten zijn gebaseerd op simulaties met vaste, niet-bewegende knooppunten, suggereren ze dat toekomstige sensordeployments — van slimme steden tot omgevingsobservatoria — langer kunnen draaien, minder vaak falen en beter gebruik kunnen maken van beperkte batterijkracht door soortgelijke intelligente besturingsstrategieën toe te passen.
Bronvermelding: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Trefwoorden: draadloze sensornetwerken, energie-efficiënte routering, deep reinforcement learning, zwermoptimalisatie, netwerkclustering